How we built the most performant DeepSeek V3.2, MiniMax-M2.5 and Qwen 3.5 397B on DigitalOcean Serverless Inference
By Debarshi Raha and Bhaskar Dutt
- Updated:
- 6 min read
Today at Deploy, we are announcing the general availability of DeepSeek V3.2, MiniMax-M2.5, and Qwen 3.5 397B on DigitalOcean Serverless Inference. On DeepSeek V3.2 and Qwen 3.5 397B, we deliver #1 output speed across all providers Artificial Analysis tested. On DeepSeek V3.2 specifically, that translates to 230 output tokens per second and sub-1-second Time-to-First-Token (TTFT) for 10,000 input tokens.
This post covers how we got there: the GPU-level work, the serving stack tuning, and the specific technical tradeoffs we made along the way.
Why fast inference matters
The focus in AI development has fundamentally shifted from the training of models to the efficiency of inference. This shift is driven by the proliferation of agentic workloads, copilots, and real-time systems that form the core of next-generation AI applications. For these applications, speed is no longer just a performance metric; it is the critical differentiator between an engaging product and one that users abandon. Specifically, low-latency inference is essential for a seamless end-user experience. For highly interactive applications like conversational agents and voice interfaces, any delay beyond a sub-1-second TTFT is perceived as sluggish.
The importance of fast inference is compounded by the complexity of modern AI workflows. An agentic task, for instance, often involves dozens of sequential model calls, where even minute Time-Per-Output-Token (TPOT) delays can accumulate into several seconds of user-visible latency. Quick inference also helps businesses by providing reliable performance and lower costs. Optimization in this area, such as that provided by DigitalOcean’s inference engine, allows enterprises to achieve superior token economics, sustained throughput, and predictable latency, which are essential for scaling their AI-native applications reliably and affordably.
Leading the Artificial Analysis benchmarks on speed
The benchmarks we’re publishing today reflect this. On DeepSeek V3.2 with 10K input tokens, we deliver:
- Output speed: 230 tok/s (3.9x AWS Bedrock at 59 tok/s)
- TTFT: 0.96s (only Google Vertex is faster among 12 providers tested)
- Balanced performance across latency and output speed: DigitalOcean is one of only three providers to be ranked in the most favorable quadrant on the Artificial Analysis Latency vs. Output Speed chart.
 Figure 1: DeepSeek V3.2 Non-Reasoning, output speed across providers. Source: Artificial Analysis, April 2026.
Figure 1: DeepSeek V3.2 Non-Reasoning, output speed across providers. Source: Artificial Analysis, April 2026.
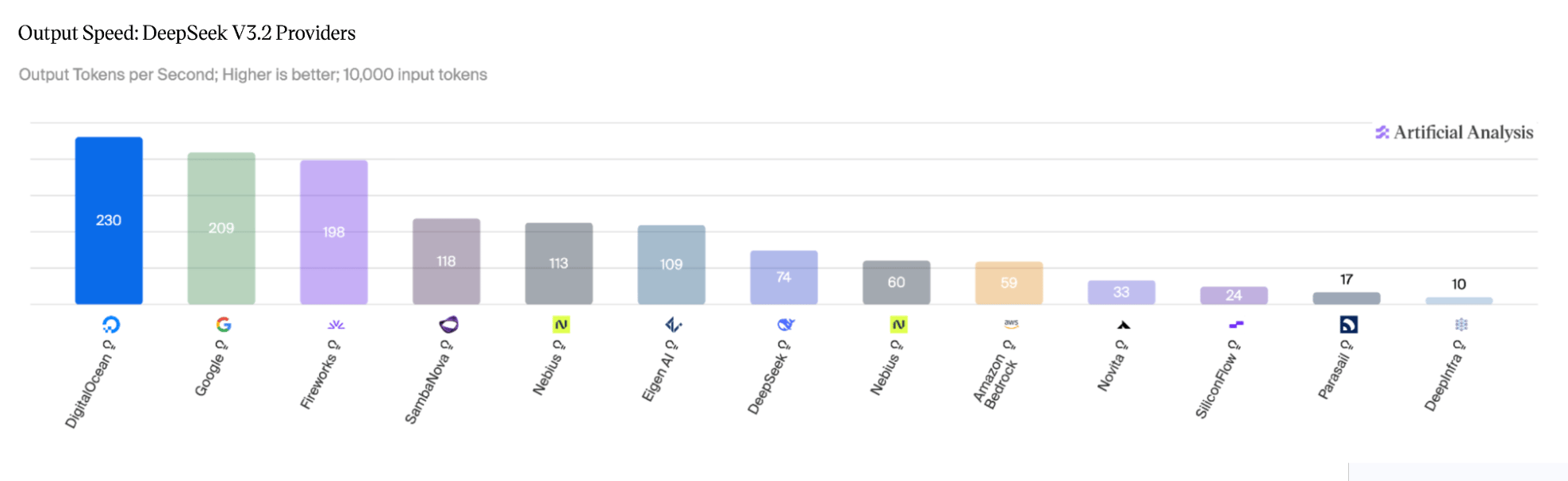 Figure 2: DeepSeek V3.2 Reasoning, output speed across providers. Source: Artificial Analysis, April 2026.
Figure 2: DeepSeek V3.2 Reasoning, output speed across providers. Source: Artificial Analysis, April 2026.
 Figure 3: DeepSeek V3.2 Reasoning, latency vs output speed quadrant. Source: Artificial Analysis, April 2026.
Figure 3: DeepSeek V3.2 Reasoning, latency vs output speed quadrant. Source: Artificial Analysis, April 2026.
Similar performance numbers for MiniMax-M2.5 and Qwen3.5 397B:
 Figure 4: MiniMax-M2.5, output speed across providers. Source: Artificial Analysis, April 2026.
Figure 4: MiniMax-M2.5, output speed across providers. Source: Artificial Analysis, April 2026.
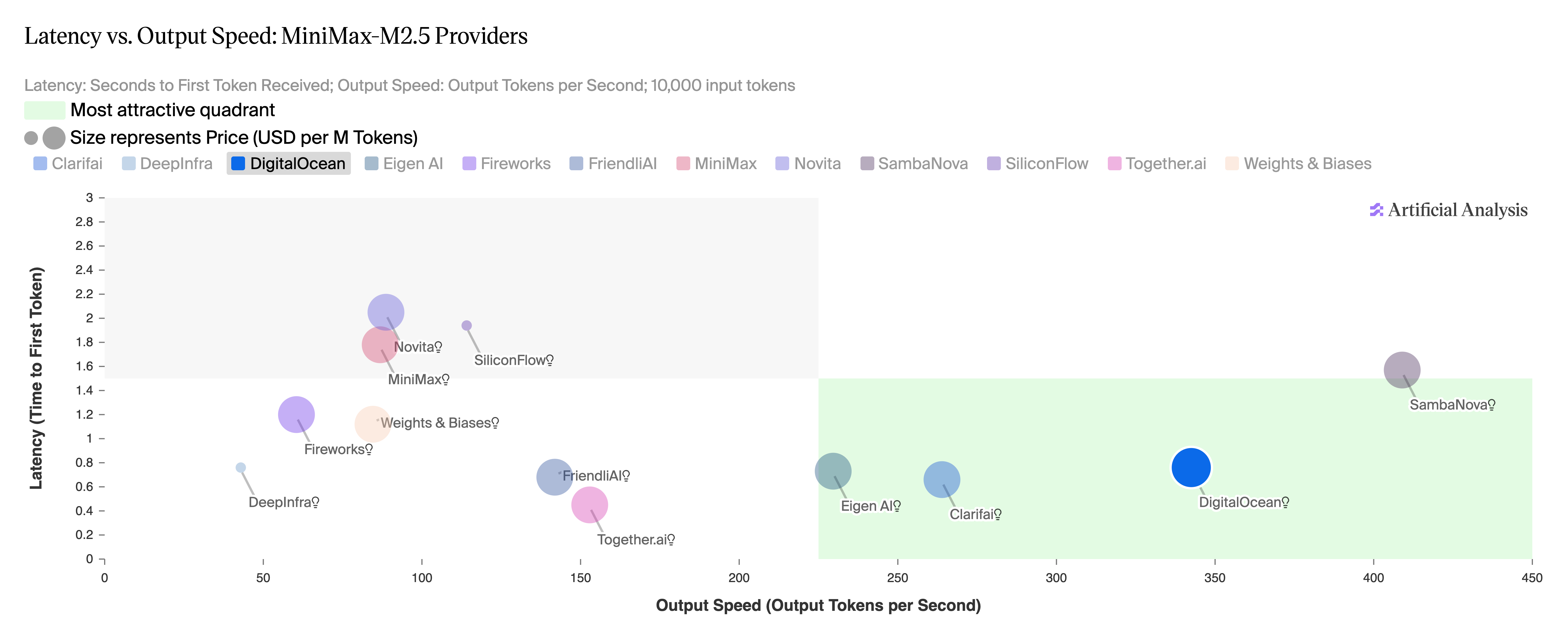 Figure 5: MiniMax-M2.5, latency vs output speed across providers. Source: Artificial Analysis, April 2026.
Figure 5: MiniMax-M2.5, latency vs output speed across providers. Source: Artificial Analysis, April 2026.
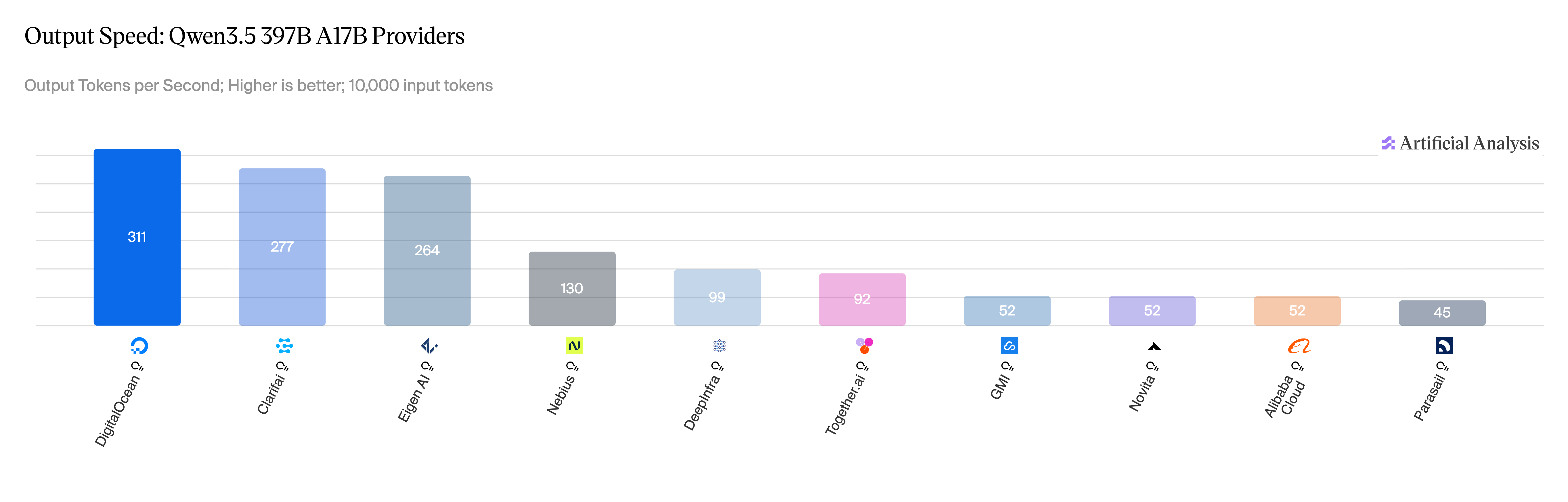 Figure 6: Qwen 3.5 397B, output speed across providers. Source: Artificial Analysis, April 2026.
Figure 6: Qwen 3.5 397B, output speed across providers. Source: Artificial Analysis, April 2026.
 Figure 7: Qwen 3.5 397B, latency vs output speed across providers. Source: Artificial Analysis, April 2026.
Figure 7: Qwen 3.5 397B, latency vs output speed across providers. Source: Artificial Analysis, April 2026.
The engineering behind the numbers
Achieving this level of performance required more than just cutting-edge GPUs. Standard configurations on latest-generation hardware often fail to reach the top of the Artificial Analysis leaderboard. To achieve these results, we co-designed and optimized every layer of the stack: selecting premium GPUs, maximizing CUDA efficiency on virtualized NVIDIA Blackwell Ultra GPUs, implementing speculative decoding, and applying quantization where it offered the best balance of speed and accuracy.
Hardware: The Power of NVIDIA Blackwell Ultra
The foundation of our performance breakthrough is the NVIDIA HGX™ B300 GPU. The Blackwell Ultra architecture provides a massive leap forward, featuring 288GB of HBM3e capacity—a 50% increase over the B200—alongside 1.5x greater NVFP4 compute power. This hardware foundation was essential for handling the massive throughput requirements of DeepSeek and Qwen at scale. While early deployment in virtualized environments initially resulted in a 25% performance hit, our direct collaboration with NVIDIA enabled us to resolve these issues, unlocking the full potential of the Blackwell silicon.
Model Quantization: Efficiency of NVFP4
We used the NVFP4-quantized version of the models, which uses a specialized 4-bit floating-point format to significantly reduce the memory footprint (~1.8x compared to FP8) and increase inference throughput. These benefits are uniquely leveraged by the NVIDIA Blackwell Ultra architecture, which features 1.5x greater dedicated NVFP4 compute power, allowing for massive performance gains with minimal impact on model accuracy. Refer to the model evaluation for DeepSeek V3.2 to see NVFP4 accuracy against original FP8 model weights.
However, raw silicon and quantization are only half the story. To translate that hardware power into world-class inference speeds, we had to implement a highly customized software stack.
Inference Engine: Performance optimizations of vLLM
We optimized the open source vLLM serving framework with a series of techniques:
- Tensor Parallelism: We used tensor parallelism for distributing the large model layers across multiple GPUs, a necessary technique for running models that exceed the memory capacity of a single GPU, which requires high-speed GPU interconnects. Based on the model size, we used either TP4 or TP8 configurations to run inference across 4 or 8 GPUs.
- Kernel Fusion: This key optimization fuses multiple operations into a single GPU kernel, which minimizes the overhead of individual kernel launches and reduces CPU gapping. By executing these merged operations on-chip, kernel fusion significantly cuts down on slower off-chip memory accesses, leading to much faster processing.
- Programmatic Dependent Launch: We used Programmatic Dependent Launch to overlap kernels wherever possible, which hides kernel launch overhead and mitigates tail effects in short-running kernels. This improves performance for low-batch-size, low-concurrency, high-interactivity workloads by ~10%.
- Speculative Decoding and Multi-Token Prediction (MTP): We leveraged the latest model features like Multi-Token Prediction (MTP) for DeepSeek to accelerate token generation, improving the Time-Per-Output-Token (TPOT). MTP was used as part of Speculative Decoding optimization to boost generation speeds. This technique uses a smaller draft model (MTP heads or EAGLE heads) to predict token sequences that the larger target model validates in a single forward pass, significantly increasing throughput while maintaining the high quality of the primary model’s output. For MiniMax-M2.5, we trained an EAGLE3 draft model using TorchSpec — a torch-native online speculative-decoding training framework that runs FSDP training and vLLM-based target inference concurrently, learning from MiniMax-M2.5-regenerated responses and live vLLM-generated hidden states to match the base model’s exact token distribution. For deployment, our experiments showed that reducing tensor parallelism for the draft model improves performance by minimizing inter-GPU communication overhead. For MiniMax-M2.5, Time-Per-Output-Token (TPOT) improved by 23% by setting “draft_tensor_parallel_size”: 1 in our setup.
Kernel fusion and draft model training were completed in close collaboration with Inferact, the original creators of the leading inference serving engine vLLM, whose expertise was instrumental in optimizing these complex workloads for specific GPU and model versions.
Real world performance
The same techniques are already running in production for customers serving inference at scale. Workato, which processes over 1 trillion automated workloads to extend its production automation with agentic AI, is running on DigitalOcean’s inference platform with 77% faster Time-To-First-Token, 79% lower end-to-end latency, and 67% lower inference costs.
“Before DigitalOcean, we didn’t have a dedicated solution for multi-node serving, which slowed our AI progress. DigitalOcean got us up and running quickly, and through close collaboration on performance optimization, helped us accelerate our inference performance and overall progress by two to three times.” — Oscar Wu, AI Research Scientist & Technical Lead, Workato
The path forward: Scaling intelligence
Our commitment to performance doesn’t stop here. We are expanding our catalog of optimized models tailored to evolving customer demand. As we move toward the next frontier of inference, we are building the infrastructure for multi-node serving with disaggregated configurations and Wide Expert Parallelism capabilities to handle the world’s most demanding agentic workloads. With hardware and software co-design, we’re focused on continuing to deliver the performance AI-native enteprises need to scale.
Try DeepSeek V3.2, MiniMax-M2.5, or Qwen 3.5 397B on DigitalOcean Serverless Inference today.
Full benchmark methodology and results are available at Artificial Analysis.
About the author(s)
Debarshi is a Fellow Engineer at DigitalOcean, where he focuses on advancing data and AI services for DigitalOcean Inference Cloud.
Helping DigitalOcean run AI inference for you faster, smarter, and more efficiently than ever before
Related Articles

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read

The Inference Tax: How Prefix-Aware Routing Eliminates the Hidden Cost of LLMs at Scale
- June 1, 2026
- 13 min read

DigitalOcean Serverless Inference: A Deep Dive
- June 1, 2026
- 17 min read