VPC: Behind The Scenes
By Piyush Srivastava and Fahim Ansari
- Published:
- 14 min read
DigitalOcean Virtual Private Cloud (VPC) is a private networking solution that provides isolation for resources running on the DigitalOcean public cloud on isolated private networks. As of this writing, Droplets, DigitalOcean’s virtual machines, and Managed Databases products can run natively on VPC.
What is DigitalOcean VPC?
Over time there has been a growing need for secure networks, driven by the increase in digital footprints of online businesses, and greater needs for cloud mobility and ever increasing data breaches over networks. VPC provides a more secure, isolated, private IP network within the DigitalOcean cloud. Private networking of this form provides a strong security foundation with increased protection and privacy of data as it moves around within the DigitalOcean ecosystem isolated from the public internet.
As with all DigitalOcean products, DigitalOcean VPC is built with simplicity at core. Users can start using VPCs without any prior networking knowledge. To keep the experience simple and intuitive, we have intentionally tried to stay away from exposing networking complexities like subnetting andIP addressing to end users, though advanced users will have more flexibility. All resources on the DigitalOcean cloud always land in a VPC. If a user has not intentionally created a VPC, the resources still land in a “default” VPC which is auto generated. This is done to ensure that the getting started experience is low friction and intuitive. Moreover, adding a leg by default into the private network means there are no surprises and frictions later on for users for enabling private networking. In addition, users can create custom VPCs with an address range of their choice from the RFC1918 address space if they need more control over their networks.
Behind The Scenes
Droplet Networking Model
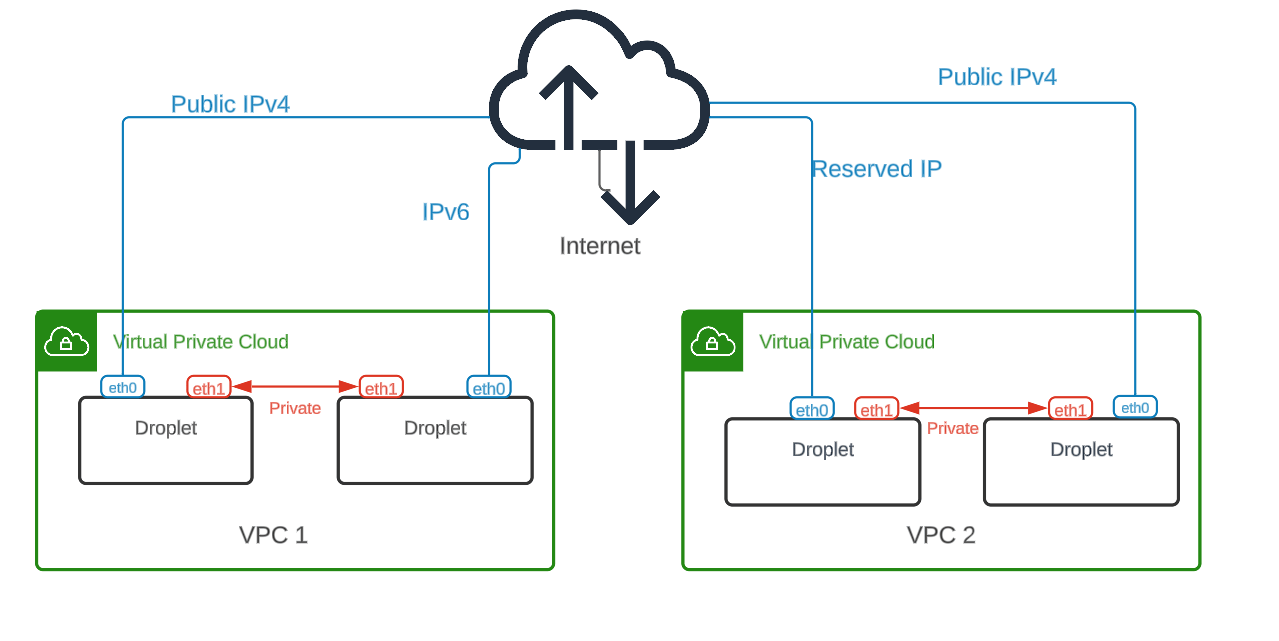
DigitalOcean Droplets have two interfaces - public (eth0) and private (eth1). The public interface has a public IPv4, an anchor IPv4 (to enable reserved IPs) and an optional public IPv6 if users choose to enable it. The private interface has a private IPv4 allocated from the VPC subnet in which the Droplet was launched. All VPC traffic flows through the private interface. An example may make this clear:
root@vpc-droplet:~# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 32:bb:fd:db:41:c8 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname ens3
inet 167.71.12.252/20 brd 167.71.15.255 scope global eth0
valid_lft forever preferred_lft forever
inet 10.18.0.6/16 brd 10.18.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::30bb:fdff:fedb:41c8/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 9a:5b:bf:df:7e:2c brd ff:ff:ff:ff:ff:ff
altname enp0s4
altname ens4
inet 10.110.16.3/20 brd 10.110.31.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::985b:bfff:fedf:7e2c/64 scope link
valid_lft forever preferred_lft forever
This is an example interface configuration of a Droplet based on Ubuntu 22.04 image. eth0 is the public interface while eth1 is the private interface. All VPC traffic flows through eth1. A few things worth mentioning here are that VPC for end users looks and feels like a L2 domain. Droplet to droplet traffic forwarding is done end to end using L2 constructs i.e. MAC (Media Access Control) addresses. VPC being a L2 forwarded network means droplets ARP for destination droplet IPs and receive the MAC address of destination droplets which are used by the host networking stack to craft ethernet frames that are sent out from the droplets. Looking at the droplet’s routing table makes it clear that the VPC traffic is L2 forwarded as the 10.110.16.0/20 route below does not have any “gateway” configured. Moreover, if we look at the local ARP table, one can find the entries for other droplets with their MAC addresses.
root@vpc-droplet:~# ip route
default via 167.71.0.1 dev eth0 proto static
10.18.0.0/16 dev eth0 proto kernel scope link src 10.18.0.6
10.110.16.0/20 dev eth1 proto kernel scope link src 10.110.16.3
167.71.0.0/20 dev eth0 proto kernel scope link src 167.71.12.252
Another detail to note is that the VPC route, for example the 10.110.16.0/20 route above, is specific to the VPC subnet in which the Droplet was launched. This means that any traffic that does not match this route (including traffic to other RFC1918 destinations) will be routed via the default route over the public interface eth0. This is worth mentioning as users who have advanced networking use cases like site-to-site VPNs or NAT gateways may need to add custom routes for routing specific RFC1918 / non-RFC1918 subnets over the private interface. Both private and public interfaces are configured with 1500 MTU, meaning Droplets can transmit max 1500 byte packets without fragmentation. There is no support for jumbo frames on the VPC network as yet.
Data Plane
Droplets run on a multi-tenanted fleet of bare metal hypervisors (HV). A single production hypervisor typically hosts Droplets belonging to several different VPCs of many tenants. This warrants the need for strong network isolation across VPCs to help ensure data protection and privacy. There is also a need to support overlapping IPs across tenants. The entire RFC1918 address space is available for a tenant to use, which means that private address space of VPCs across different tenants can conflict or overlap. Therefore, identifying and forwarding traffic based on IP addresses is not enough and there is a need for some other unique construct at L2 / L3 level for VPC traffic routing.
Isolation is achieved by modeling VPC as an encapsulated tunnel using VXLAN. Every VPC is isolated in its own VXLAN tunnel (Virtually Extensible Local Area Network). VXLAN has a concept of VXLAN network identifier (VNI) which is used for uniquely identifying a VPC tunnel on the dataplane. All Droplet to Droplet traffic within a VPC is contained within the corresponding VXLAN tunnel and is not allowed to leak outside of it at any point on the network except for the VXLAN tunnel endpoints (VTEPs). VTEPs are the endpoints in the network where the VXLAN packets are encapsulated or decapsulated. Droplet to Droplet VPC traffic is HV to HV point to point VXLAN. This creates a full mesh dataplane where every HV directly sends VXLAN packets to other HVs. This means that every hypervisor hosting a VPC droplet is a VTEP.
VPC subnets can overlap across tenants and hence there is a need to uniquely identify VPC traffic from constructs other than IP addresses as the IPs alone are not sufficient to disambiguate and associate packets with the corresponding VXLAN tunnel or more specifically the VNI. To do this, VPC datapath relies on MAC addresses for unique identification. The VPC control plane has been designed to keep the droplet MAC addresses globally unique. As discussed earlier, VPCs are forwarded using L2 constructs and each VPC in that sense looks like a L2 domain and therefore MAC addresses fundamentally need to be unique within a VPC boundary. Even though VPC relies on global MAC uniqueness, this can be achieved by guaranteeing MAC uniqueness within the L2 domain. There may be a future where global uniqueness constraint for droplet MAC addresses is taken away as it is not strictly required in the L2 context.
As an ethernet frame egresses the source hypervisor, VPC datapath looks at the source MAC and figures out which VXLAN to associate the packet with. It then encapsulates the packet with VXLAN with the appropriate VNI, and forwards to the destination hypervisor. For curious readers, few natural questions that would come to mind - A VPC can have many Droplets, how does the datapath identify each of them to associate with a VXLAN tunnel? or How does the VPC datapath learn the details of the destination HV to send the VXLAN packet to? These are good questions and a gentle introduction to the VPC control plane and core routing software (Open vSwitch) will help shine some light on these.
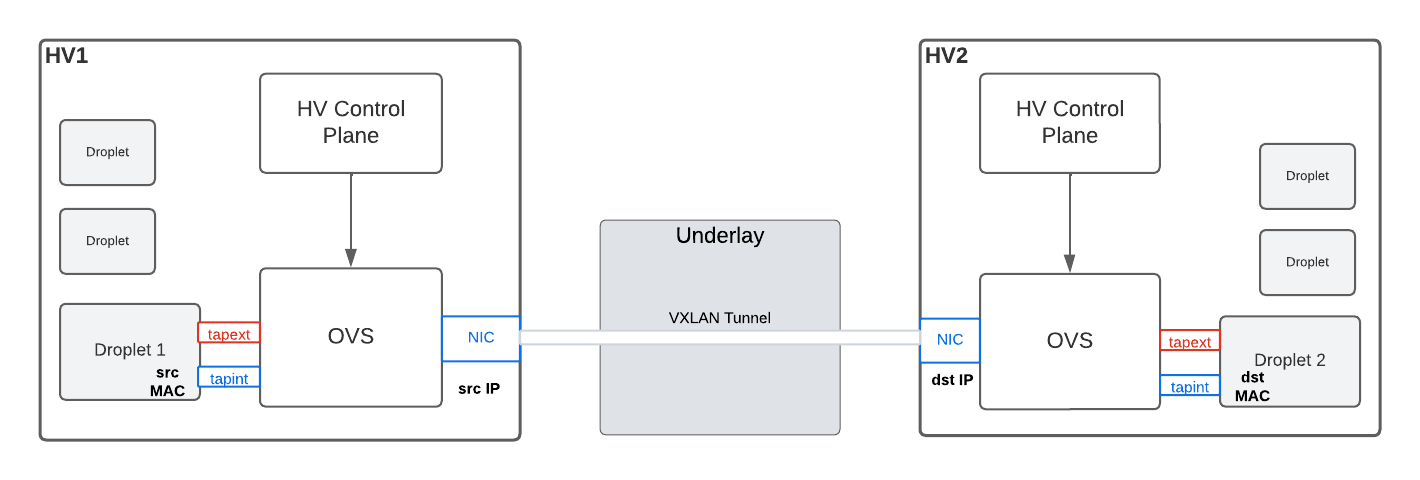
As illustrated in the diagram above, virtual NICs (vNIC) of all Droplets are connected to OvS. Droplet vNICs are added to OvS with the port abstraction. OvS provides the capability to express the datapath with OpenFlow specification. In simple terms, there is a lot of flexibility to program the OvS datapath for enabling the VPC use case. Let’s look at the journey of an outbound and an inbound VPC packet as it flows from droplet to Droplet and discuss how OvS enables the packet flow.
Journey of an outbound VPC IP packet from a Droplet (d1) on HV1 to Droplet (d2) on HV2
-
d1 networking stack crafts an ethernet frame with src MAC of d1 and dst MAC of d2
-
OvS matches on source MAC to find the tunnel ID for VXLAN encapsulation
-
OvS encapsulates ARP request in VXLAN with outer dest IP set to destination HV
-
OvS outputs the packet on a port to forward it on the underlay
Since VPC is a L2 forwarded network, d1 ARPs for d2’s MAC (details of the ARP packet journey are left out of this blog). ARP’s journey follows a similar path as that of IP packet’s journey mentioned above. Since there is a need to match on the source MAC and finding the tunnel ID based on that, there should be some way to express that in the datapath. This is done by programming OvS flows which look like the following:
cookie=0x487b800020000, duration=1543543.925s, table=67, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1500,dl_src=c2:4c:ae:ea:ad:57 actions=load:0x487b8->NXM_NX_TUN_ID[],resubmit(,68)
This flow matches on the source MAC (dl_src) to associate the appropriate tunnel ID. In the above flow, the action load:hex_tunnel_id->NXM_NX_TUN_ID[] loads the programmed tunnel ID as the VNI for the tunneled packet. VPC members are uniquely identified using MAC addresses, so for all members that belong to the same VPC, the same tunnel ID (VNI) is used for VXLAN encapsulation. VPC control plane is the source of truth for VPC membership and is responsible for distributing the membership state to the control plane running on each hypervisor which in turn is responsible for programming the OvS datapath (adding, removing, updating flows). Once the tunnel ID is associated, the packet is resubmitted to the next OvS table to set the dst IP for the tunneled packet.
cookie=0x487d900020000, duration=1544306.696s, table=68, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1500,tun_id=0x487d9,dl_dst=8a:f1:c7:e8:7e:d2 actions=load:0xa26f2e6->NXM_NX_TUN_IPV4_DST[],load:0x12b5->NXM_NX_PKT_MARK[],output:5
The above flow matches on the tunnel ID and destination MAC to figure out the destination HV IP to send the VXLAN encapsulated packet to. The action load:hex_ipv4->NXM_NX_TUN_IPV4_DST[] loads the programmed IPv4 into the dest IP of the tunneled packet. After this, the packet is sent to the port that is configured in OvS as the “VXLAN” port which takes care of vxlan encapsulation making use of NXM* fields that were set earlier for the tunneled packet. The OvS VXLAN port specifically serves as the VTEP on the datapath. OvS flows are programmed using the state provided by the VPC control plane. For example, each VPC member has the following fields: mac address, tunnel_id, HV host. These fields are necessary and sufficient for programming the OvS flows for tunnel encap, decap and traffic forwarding for VPC use case. Now that we have some context on the OvS datapath, let’s look at the journey of an inbound IP packet on a destination hypervisor.
Journey of an inbound VPC IP packet into Droplet (d2) on HV2 from Droplet (d1) on HV1
-
Packet enters the OvS datapath
-
OvS matches on tunnel ID and destination MAC to find the OvS port for d2
-
OvS decaps the packet and sends it to d2’s OVS port
-
Packet is delivered to the d2’s networking stack
There is a flow on the destination HV that does the above match and forwarding. As with other flows, the state needed to program this flow is provided by the VPC control plane which we will explain in the next section. This flow looks like:
cookie=0x487b800020000, duration=1808537.462s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1100,tun_id=0x487b8,in_port=5,dl_dst=c2:4c:ae:ea:ad:57 actions=load:0xc24caeeaad57->OXM_OF_METADATA[],resubmit:1
The above flow looks at packets on the OvS VXLAN port (VTEP), then matches on tunnel ID and destination MAC and the resulting action of the match is to forward the packet to the OvS port that corresponds to the droplet. Native VXLAN support in OvS along with the capability of expressing the datapath with the highly flexible OpenFlow spec helps in programming complex VPC datapath and other packet processing use cases.
Control Plane
The control plane is the brain that powers the orchestration of VPC routing and datapath. Routing updates on the datapath need to be done based on user actions like adding or removing Droplets from a VPC, fleet events like Droplets migrating to other HVs because of hardware faults, or maintenance activities. As discussed in the earlier sections, the VPC data plane is a peer-to-peer mesh system where encapsulated VXLAN packets are transmitted point to point from HV to HV. This means any time placement of the Droplet is updated or a Droplet is added / removed, the whole mesh needs to be re-converged to reflect the latest state of the endpoints.
The re-convergence and distribution of the updated state to all HVs hosting VPC Droplets is done by the VPC control plane. The main challenge that needed to be solved in the VPC context was solving for distributed state propagation at scale for a full mesh data plane. Moreover, there are variations in user behavior and fleet updates that are hard to predict and therefore the design of the system should keep into account enough headroom for throughput surges, concurrent updates, and updates to large VPCs with many members. The convergence system needs to balance the needs and trade-offs across these scaling dimensions, combined with keeping the complexity of the overall system contained and manageable.
There are scenarios where many hypervisors need to be evacuated which causes a sudden uptick on the VPC control plane traffic as the Droplets are getting migrated and the new placement state needs to be updated on the VPC control plane. This triggers a reconcile of the VPC datapath across the HV fleet. Then, there are user scenarios where there is a need to quickly scale up or down based on changing traffic conditions and demand for customer workloads which can cause a surge in VPC control plane traffic. A surge in control plane traffic, along with the need to distribute the updated state across many HVs combined with many VPCs updating concurrently makes it an interesting distributed systems problem to solve.
Let’s start with discussing a user action of creating a Droplet in a VPC and how it flows through the stack. A user would use the UI or the Public API to create a droplet in a VPC. A Droplet create request lands into Droplet API handlers which orchestrate the request through the VPC stack if a Droplet needs to be added to the VPC. There are a few pieces of orchestration that need to happen on the control plane to fully make all the systems aware of the new droplet, its network interface configurations, hypervisor placement and VPC membership. The “droplet” API handlers after talking to VPC “product” layer APIs hand-off the create request to lower level “compute stack” services. These compute stack services then coordinate with various Network services to set up the Droplet for VPC membership.
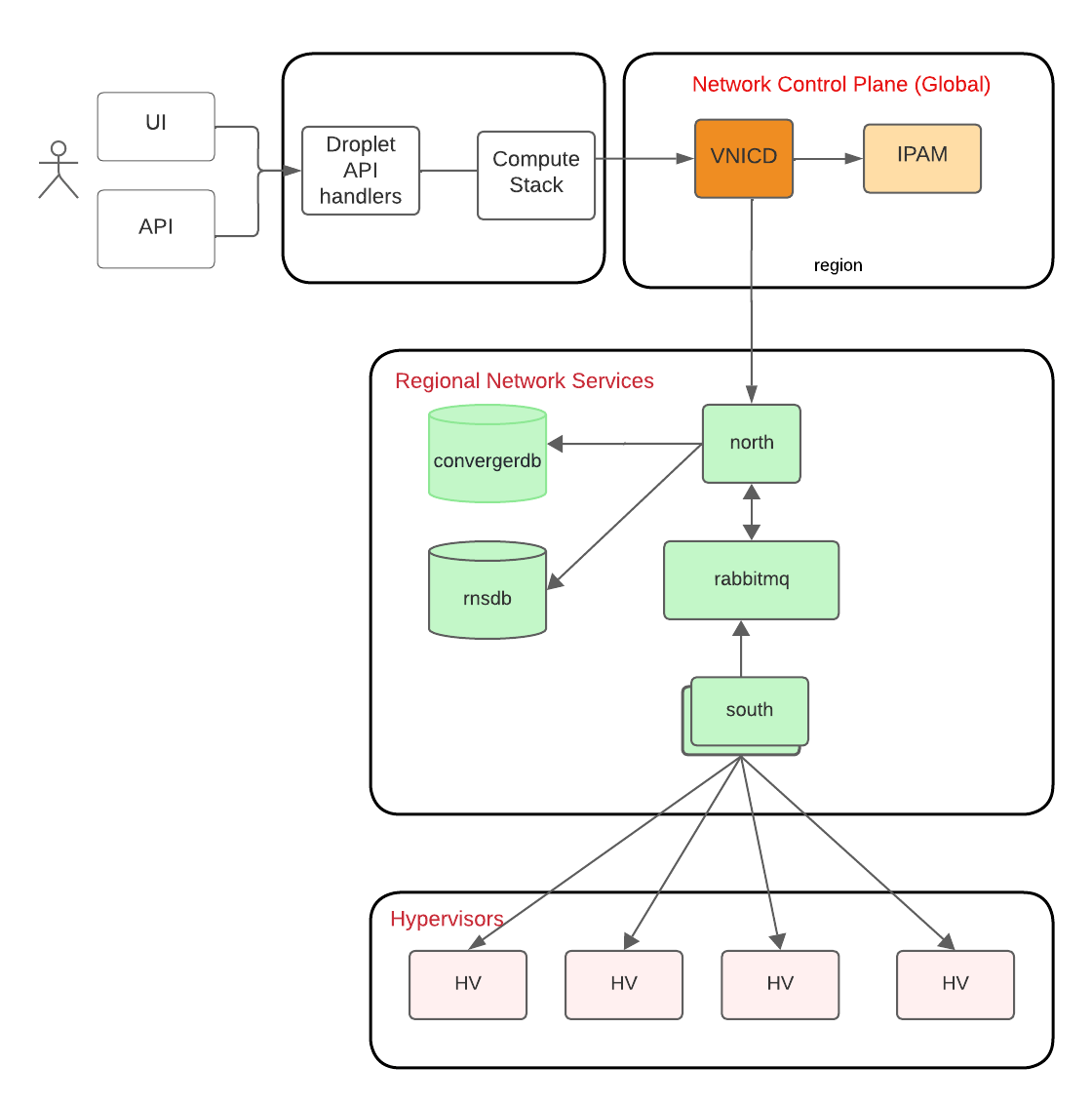
The key network services that are in the critical path are VNICD, the service dedicated to managing the configuration and lifecycle of virtual NICs that are plugged into Droplets, IP Address Management Service (IPAM) for allocating public and private addresses, and Regional Networking Service (RNS), the core control plane service for VPC. To keep the discussion here scoped to VPC, let’s assume that a Droplet create request results in that Droplet being added as a VPC member on RNS.
What happens when a VPC member is added to RNS? As discussed earlier, VPC members are uniquely identified by MAC addresses. So, whenever a Droplet needs to be added as a VPC member, the MAC address of the private VNIC is taken and sent to RNS to add as a member. In addition to the MAC address, RNS also needs to know the hypervisor placement and the VPC ID to which the member needs to be added to. Once the member is added to RNS, it is first transactionally persisted into a database and after that a “convergence” process is triggered to propagate the updated VPC state across all HVs that are hosting the members of the updated VPC. Convergence process needs to be able to handle high throughput updates that could be happening concurrently across multiple VPCs. In addition, convergence should be resilient to failures that may happen in various parts of the system. Some failure scenarios being - one or more HVs hosting a VPC being not reachable due to a crash or a network partition resulting in the state being partially converged, updates to VPC potentially getting lost with failures and so on.
The convergence framework on the VPC control plane is composed of three main components:
-
North: northbound API which other services like VNICD consume to add, remove members, update HV placement on RNS
-
RabbitMQ: provides a task queue where VPC update messages are buffered,
-
South: workers that consume tasks from RabbitMQ and synchronously call HV control planes across many hypervisors for state convergence.
The convergence stack with North, RabbitMQ, and South provides a robust task management framework for distributed state propagation. Every update to the VPC is a “task” that contains the entire set of VPC members in the payload and is scheduled to execute on all the targets that are interested in receiving the updates. In this context, all the targets are HVs hosting droplets of the updated VPC. There is still a possibility of failures at multiple places in this stack which potentially result in missing updates or partial updates to a subset of targets. To deal with this problem, the convergence system relies on versioning.
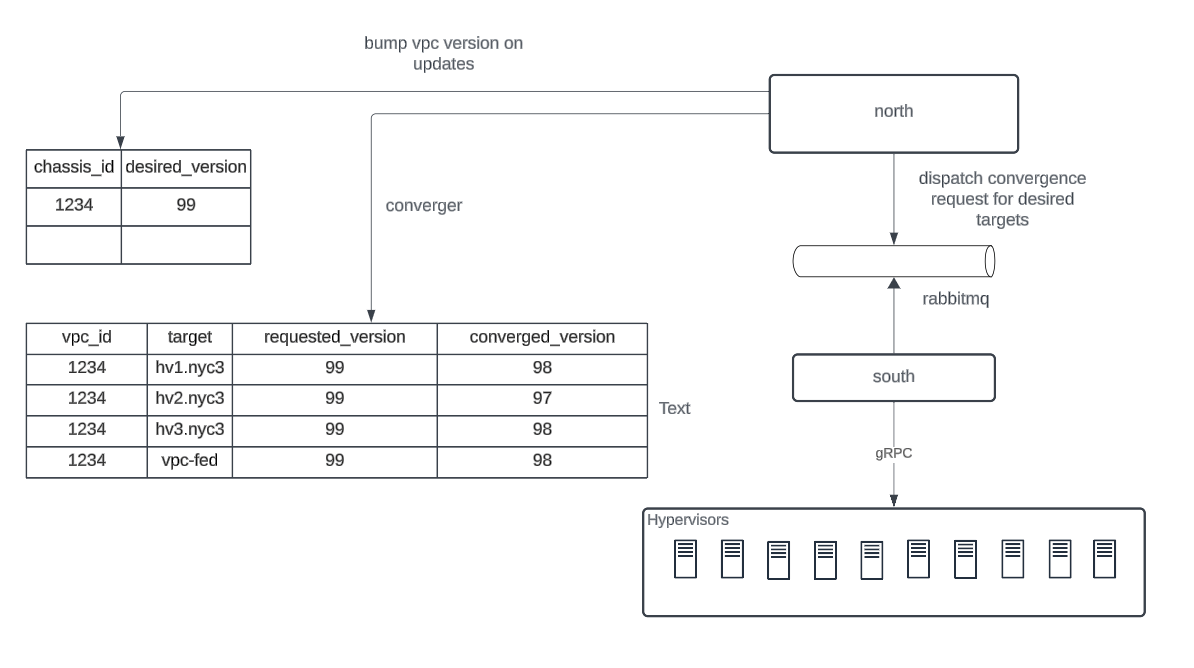
Every update to a VPC bumps up its version in the database and when the converger goes ahead with applying the updates for every HV, it keeps track of what version has been converged on an HV and what is the “desired” version. If the desired version is greater than the converged version for a specific HV, a convergence attempt is made to catch up the HV to the desired version. The convergence attempt can fail for many reasons, in which case the converged version is not incremented and the convergence retries. The retries are done using a periodic job that that attempts to catch up all VPCs that are partially converged. Overall, this helps in dealing with many failure modes that happen across the system and also makes it resilient against crashes. The RNS control plane could crash but since the VPC updates and the version bump is done transactionally, the system resumes from where it left off when it comes back online. To curious readers, this may look familiar with sophisticated task execution or workflow management frameworks. As the DigitalOcean networking stack has evolved, there is also a possibility to look at a BGP based control plane for VPC in the future.
Conclusion
DigitalOcean’s Virtual Private Cloud is a complex globally distributed system with many moving parts playing a role in providing a resilient, highly available private networking experience to end users. As we have gained operational experience with the system and as we continue evolving the system to support more VPC features, we continue to revisit our design decisions, find similarities and patterns across other product stacks and refine and sometimes redefine our architecture.
About the author(s)
Principal Engineer, AI Infrastructure
Related Articles
Under the Hood: Serving Kimi K3
Jonathan Dieu
- July 30, 2026
- 12 min read

Outperforming Fable 5 at half the price: meet model synthesis, a new server-side tool on DigitalOcean Inference Engine
- July 23, 2026
- 8 min read
Upcoming GPU Pricing Updates
- July 21, 2026
- 2 min read