Businesses that provided automated customer support, content generation, or AI-driven services relied on pre-trained models, including large language models (LLMs) like GPT-2, which gained traction around 2018. These models generated responses based solely on the data on which they were trained. While effective for handling static tasks, these models had limitations for dynamic scenarios. They could not access updated information, making them less adaptable to changes in business needs, like product launches or policy updates. This limitation persisted until 2020, when retrieval augmented generation (RAG) was introduced. RAG allowed users to retrieve information from external knowledge sources, improving relevance and accuracy in AI-generated responses.
For instance, if you built a translation tool using an LLM, the model would only provide translations based on the training data it had seen. If a new term or phrase emerged after the model was trained, the translation tool wouldn’t have access to this information and might produce inaccurate or outdated translations. This could hinder effective communication with international clients or partners, resulting in misinterpretations of key messages, marketing materials, or contracts. With the introduction of RAG, companies can now structure their LLMs to retrieve relevant information from external knowledge sources, ensuring that responses remain accurate and up to date. Besides retrieving the latest information, RAG could also provide specialized information, such as accessing a company’s support tickets (to provide tailored responses based on previous inquiries), where the focus is on retrieving detailed and contextually relevant data. Read on to learn about RAG, how it works, and its benefits.
Key takeaways:
-
Retrieval Augmented Generation (RAG) is a technique that combines an AI language model with a retrieval system: when asked a question, the system first retrieves relevant documents or data, and then the AI model uses that information to produce a more accurate, context-informed answer.
-
RAG addresses the limitations of standalone language models (which have fixed training data) by allowing real-time access to external knowledge sources, thus keeping answers up-to-date and grounded in factual references.
-
By using RAG, AI applications like chatbots or Q&A systems become smarter and more reliable—providing answers that can be traced back to source documents—making it a key approach for building AI systems that require both the creativity of generation and the accuracy of retrieved knowledge.
What is RAG?
RAG is a technique in natural language processing and artificial intelligence that combines two components: information retrieval and text generation.
In this approach, external documents or data sources from web pages/research papers/proprietary company datasets are first retrieved in response to a query (based on a user’s input). This retrieval process uses a vector database, where the data is pre-processed into vector embeddings. These embeddings capture *semantic meanings, allowing for efficient search and retrieval of the most relevant documents based on the query. Then, generative models like generative pre-trained transformers (GPT) or bidirectional and auto-regressive transformers (BART) use the retrieved information to produce a coherent and relevant response. RAG builds more informed and accurate outputs, combining existing knowledge bases with generative capabilities.
*Semantic meaning deciphers the relationships between words and their usage in context. For example, the words “bank” (as a financial institution) and “bank” (as the side of a river) have different meanings depending on the context.
How does a RAG work?
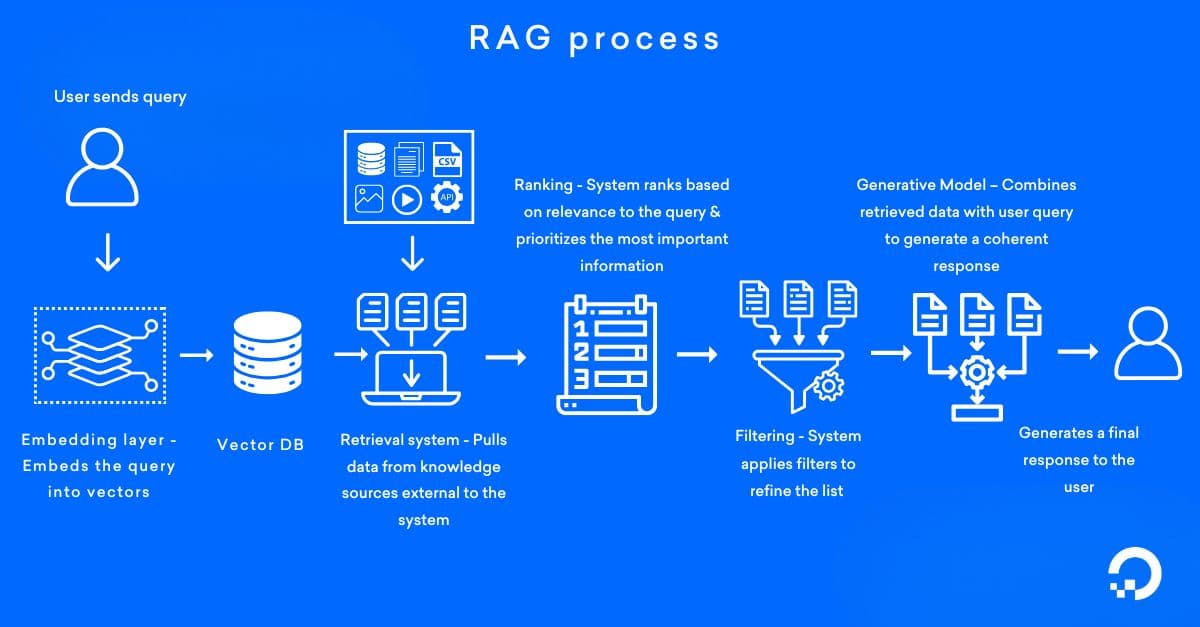
Input query
The user initiates this step by providing a query through a user interface like a chatbot, search bar, or API request. Technically, the input is captured and processed by the system, mostly using natural language processing (NLP) techniques like tokenization (breaking down the query into smaller units like words or phrases), stemming/lemmatization (reducing words to their base forms), and named entity recognition (NER) (identifying key entities like dates, names, or locations) to understand the context and intent of the query.
At this stage, the RAG system embeds the query into vectors — converting the text into numerical representations that can be used for document retrieval. These vectors enable the RAG system to perform similarity searches against a vector database provided by the organization, which stores pre-embedded document representations. This query embedding step allows the RAG system to perform vector-based similarity searches against the document corpus. The input query is passed into the RAG framework via REST APIs or integrated systems that accept text inputs from web applications, mobile apps, or other platforms for further processing.
Document retrieval
Once the list of documents is identified based on relevance to the user’s query, the system searches within a pre-built knowledge base, which could include internal company documents, databases, or pre-scraped external repositories (such as Wikipedia). The system compares the query embeddings with document embeddings, applying vector scoring techniques to rank and retrieve the most relevant information. This process ensures that only the most pertinent documents are selected. The retrieved documents provide factual data or context to support the response.
Information ranking
The retrieved contexts can be in any one or a combination of the formats—structured data (text, JSON, or HTML) or unstructured data (raw text data, scanned documents, or multimedia files like images, audio, and video) or other formats (PDFs, CSV files, or XML).
Different ranking techniques are applied depending on the source of the retrieval results to ensure that the most useful and accurate information is prioritized. The ranking is done by assessing how well the retrieved documents match the query. In an e-commerce fraud detection system, you might have retrieved transaction records in JSON format that are ranked using anomaly detection techniques, and unusual spending patterns are prioritized to identify potentially fraudulent activities based on the query.
Response generation
The retrieval results are next passed to the generative models (like GPT-4 or Mistral) through document concatenation or embedding injection, depending on the system architecture. The generation process combines contextual embeddings (numerical representations of words, sentences, or passages) from the retrieved content, self-attention mechanisms (e.g., the transformer architecture) to focus on relevant information, uses decoding techniques (like beam search or sampling techniques), and the model’s pre-trained knowledge (language patterns, facts, and syntax) to generate a relevant response.
Final output
The system generates a user-friendly response by formatting the text into structured outputs, such as plain text, HTML, or JSON. It then performs post-processing to ensure clarity and coherence. Finally, the response is integrated into the application interface and delivered through APIs or dynamic web calls, making the information easily accessible and as accurate as possible.
Benefits of RAG
You can access dynamic, context-rich responses with RAG, ensuring your applications stay up-to-date and relevant. It adapts quickly to new information, and builds trust by delivering accurate, well-sourced information.
-
Improved accuracy: By combining retrieval with generation, RAG improves the accuracy of responses. Instead of relying solely on a model’s pre-trained knowledge, it pulls relevant information from external sources, making responses more factually grounded. For example, when asked about recent events like news or scientific research, a RAG workflow can fetch up-to-date details from trusted databases.
-
Reduced hallucinations: Generative models alone can sometimes produce inaccurate responses, known as AI hallucinations. RAG minimizes this by anchoring outputs to retrieved documents, ensuring the information is drawn from factual sources rather than purely generated. For example, in educational platforms, RAG improves generative AI by delivering accurate, fact-checked answers to student queries.
-
Better handling of specialized topics: RAG is an excellent technique for niche or technical topics where the model’s training data might be limited. Pulling from domain-specific documents generates more accurate and detailed responses, such as retrieving medical papers to answer healthcare-related queries.
-
Scalable knowledge integration: You can easily scale RAG systems to include more extensive and diverse datasets. As your knowledge base grows, so does the system’s ability to generate more informed and relevant responses, making it adaptable to various industries or applications. For instance, in conversational AI platforms, RAG can incorporate diverse data sources, allowing the system to improve its understanding and provide more accurate responses across various topics.
RAG vs fine-tuning vs prompt engineering
All three methods—RAG, fine-tuning, and prompt engineering—are designed to improve the performance of AI models. However, they vary in approach:
💡Ready to take your AI and machine learning projects to the next level? DigitalOcean GPU Droplets offer flexible, cost-effective, and scalable solutions designed specifically for your workloads. Effortlessly train and infer AI/ML models, manage large datasets, and tackle complex neural networks for deep learning applications while meeting high-performance computing (HPC) requirements.
You can now build powerful, responsive RAG applications with DigitalOcean GPU Droplets.
-
RAG dynamically augments model responses by pulling in data but still relies on prompt engineering for query formulation.
-
Fine-tuning changes the model itself by retraining it on new data to specialize it for specific tasks.
-
Prompt engineering aims to get the best out of an unchanged, pre-trained model.
These methods are not mutually exclusive. For example, you can combine these three approaches to create an AI agent or chatbot, where RAG helps the chatbot pull real-time product information, fine-tuning adapts the underlying LLM to make the chatbot more skilled at answering domain-specific questions, and prompt engineering would ensure that the chatbot asks users the right questions and interprets their requests accurately.
| Parameter | RAG | Fine-tuning | Prompt engineering |
|---|---|---|---|
| Data dependency | Uses pre-built knowledge base, which can include structured and unstructured data, internal databases, and pre-scraped external web sources | Requires huge, domain-specific dataset for training | Uses a pre-trained model with minimal or no additional data |
| Adaptability | Highly adaptable to new or evolving information | Can be adapted only with additional training or transfer learning | Adaptable but limited to crafting the right prompts |
| Latency | Potential for latency due to document retrieval and ranking | Low latency after the model is fine-tuned | Immediate response, no latency introduced by external retrieval |
| Cost and resources | Moderate: Computational cost tied to document retrieval | High: Requires large computational resources for training | Low: Minimal computational overhead, but requires prompt crafting |
| Real-time information | Can access real-time, external information for dynamic responses | Provides dynamic responses based on the latest fine-tuning. Requires frequent retraining to stay up-to-date. | No real-time data access, relies on pre-existing model knowledge |
| Scalability | Scales with the availability of external data sources | Difficult to scale without resource investment | Highly scalable, relies only on model and prompt construction |
💡Lepton AI, Supermaven, Nomic AI, and Moonvalley harness the power of DigitalOcean GPU Droplets to improve AI training and inference, optimize code completion, extract valuable insights from vast unstructured datasets, and produce stunning cinematic media. These innovations demonstrate the scalability and accessibility of AI-driven solutions.
Sign up to unleash the full potential of DigitalOcean GPU Droplets!
Challenges of RAG
While RAG offers a dynamic solution, it also presents challenges in data consistency and scalability. Organizations may struggle with integrating diverse data sources, as varying formats and quality can lead to inconsistencies.
Additionally, scaling RAG to handle large, diverse datasets might introduce increased complexity and maintenance efforts, while handling biased or incomplete data can distort responses and affect overall accuracy.
Data reliability
When using RAG, you may face challenges with the reliability of the data provided to the system. If outdated or incorrect information is supplied to the knowledge base or training dataset, it might lead to inaccurate responses. For example, while building an analytics tool, if the data source is not regularly updated, the insights generated might be based on old information, affecting decision-making.
Latency issues
During the document retrieval and ranking process, RAG searches for relevant data from multiple sources, which takes time, especially if the sources are large or require API calls to third-party databases. Once the documents are retrieved, ranking them based on relevance might slow the process since complex ranking algorithms (like TF-IDF or BERT) are used. For instance, retrieving multiple external records for validation in fraud detection tools may delay response times, making it difficult to act on critical threats in real-time.
Managing unstructured data
Users are responsible for converting unstructured data (such as images, audio, or raw text) into structured formats—like text, JSON, or feature vectors—to become part of the external knowledge source used in the retrieval process. This task might involve complex steps, including OCR for scanned documents, speech-to-text for audio, or image recognition for visuals, all of which might introduce potential inaccuracies and require careful handling.
For example, a developer building a customer support analytics tool or bug-reporting system that processes user reviews would need to manage data inconsistencies and preprocessing challenges. OCR for scanned documents can introduce errors, such as misinterpreted characters, while raw user reviews may contain informal language that’s difficult to standardize. These inconsistencies make it challenging to convert the data into a structured format suitable for ranking, which might lead to inaccurate evaluations or require additional steps to clean and format the data properly.
Retrieval augmented generation FAQs
What is retrieval augmented generation (RAG) and why was it developed? RAG is a technique that combines information retrieval and text generation, allowing AI systems to access updated information from external knowledge sources rather than relying solely on pre-trained data. It was introduced in 2020 to address limitations of earlier models like GPT-2, which could not access updated information and were less adaptable to changes like product launches or policy updates.
How does the RAG process work technically? RAG first retrieves relevant documents from external sources like web pages or proprietary datasets using a vector database where data is pre-processed into vector embeddings that capture semantic meanings. Then generative models like GPT or BART use this retrieved information to produce coherent and relevant responses, combining existing knowledge bases with generative capabilities for more informed outputs.
What are the main benefits of using RAG systems? RAG improves accuracy by grounding responses in retrieved documents rather than relying solely on pre-trained knowledge and significantly reduces AI hallucinations by anchoring outputs to factual sources. It also handles specialized topics better by pulling from domain-specific documents when training data might be limited, and offers scalable knowledge integration that grows with your knowledge base size.
In what situations is RAG particularly valuable? RAG is excellent for applications requiring up-to-date information like news or scientific research, where it can fetch current details from trusted databases. It’s particularly valuable in educational platforms for delivering accurate, fact-checked answers to student queries, and in technical or niche domains where the model’s training data might be limited, such as retrieving medical papers for healthcare-related queries.
Accelerate your AI projects with DigitalOcean Gradient GPU Droplets
Accelerate your AI/ML, deep learning, high-performance computing, and data analytics tasks with DigitalOcean Gradient GPU Droplets. Scale on demand, manage costs, and deliver actionable insights with ease. Zero to GPU in just 2 clicks with simple, powerful virtual machines designed for developers, startups, and innovators who need high-performance computing without complexity.
Key features:
-
Powered by NVIDIA H100, H200, RTX 6000 Ada, L40S, and AMD MI300X GPUs
-
Save up to 75% vs. hyperscalers for the same on-demand GPUs
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
-
HIPAA-eligible and SOC 2 compliant with enterprise-grade SLAs
Sign up today and unlock the possibilities of DigitalOcean Gradient GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
