Managing Kubernetes at scale with DigitalOcean
By Eve and Dylan Scott
- Published:
- 7 min read
DigitalOcean has been providing a managed Kubernetes service since 2019. Over those years, our infrastructure has changed a huge amount, notably in the form of a new and improved Containerised Control Plane (CCP) architecture launched in 2021. In this post, we’ll explore the journey we took to the new architecture using an open source project called Cluster API. This was combined with some DigitalOcean ‘’’scrappy magic’’’ to provide a scalable, fault tolerant, managed Kubernetes service for customers. We’ve written about it in the past, but it’s time to dive in and swim through the details.
As the product and team matured, we discovered that the legacy approach to managing and provisioning clusters presented efficiency and reliability challenges, which sometimes turned our DevOps into DevOops. As such we needed to build upon these learnings to improve DOKS as a product offering.
In the beginning, the control plane was run on a single Droplet, of which the accessibility of the control plane was entirely reliant on. If there was a hypervisor crash, or if the Droplet ran out of memory, or otherwise suffered a fault, the entire control plane would go down and often took considerable time to come back up again. In addition to this, it was harder to scale as it could only be done vertically, and we were constrained by available Droplet sizes. Maintaining thousands of these Droplets, their associated operating systems and gubbins was a painful task, when we only really cared about the containers running inside it.
We also wanted to improve our OPH (Oops per hour) metrics within the team. With that in mind, a changeup was much needed. This solution ended up being more like Kubernetes-In-Kubernetes. Let’s start with the first component in our stack, Cluster API.
What is Cluster API?
Cluster API (CAPI) is both a project, and special interest group within Kubernetes which focuses on providing an API for provisioning Kubernetes Clusters in a cloud native fashion. The project part of Cluster API is a declarative API over the top of an existing Kubernetes cluster and provides tooling, apis, and machinery to support the lifecycle of Kubernetes clusters. Think of it like the Kubernetes operator. CAPI is comprised of several components each with a distinct role in the provisioning process:
-
Management Cluster - The management cluster is the Kubernetes cluster responsible for hosting the CAPI components. It is the mothership, the almighty, the base on which all is controlled.
-
Workload Cluster - This is a Kubernetes cluster that is created by the CAPI controller running within the management cluster. In our case, a workload cluster houses applications and services necessary to maintain and operate customer control planes. Workload clusters could run virtually anywhere there is a supported CAPI infrastructure provider. For example, DigitalOcean—other cloud providers are available but we hope you use us!
-
Infrastructure Provider - An infrastructure provider is an extension to the core CAPI providing the cloud specific functionality to create required resources to run your workload cluster. An infrastructure provider is essentially where your workload cluster nodes will live, be it on DigitalOcean as Droplets, or Kubevirt as virtual machines, or in Minikube. The infrastructure provider controls the lifecycle of the nodes that are created (wherever they might be).
-
Bootstrap Provider - Actually initializes Kubernetes on to the resources provisioned by the infrastructure provider. Bootstrap providers are synonymous with other tools such as Kubeadm or KOPS. For instance we use Kubeadm as a bootstrap provider as part of CAPI.
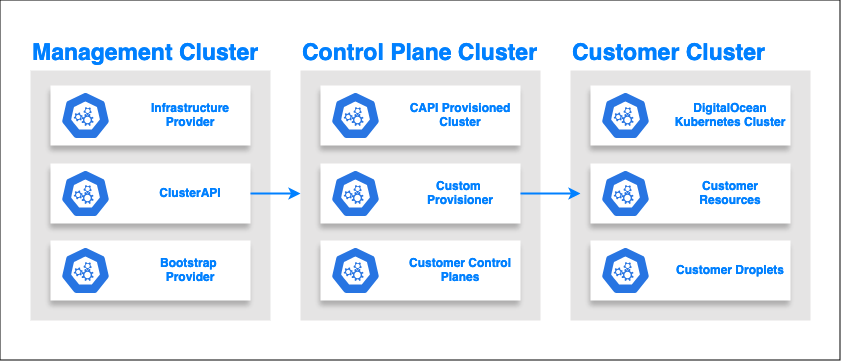
So how does this fit at DigitalOcean within the context of the managed service we provide? We use Cluster API to simplify the complexities of provisioning new Kubernetes clusters as well as providing more structure to ongoing maintenance and upgrades. Cluster API is installed into a management cluster (a plain old K8s cluster) and once installed provisions workload clusters or as we call them - Control Plane Clusters (CPC’s).
From a customer point of view, when a DOKS cluster is created you are not interacting with CAPI directly as we use this to provide the underpinning infrastructure on top of which your clusters live happily. In essence it’s the first layer of Kubernetes that makes up the overall managed service. As you can imagine, maintaining a low level infrastructure layer that underpins higher level abstractions would be near impossible at scale if done by hand. Cluster API to the rescue!
We like Kubernetes with our Kubernetes…
Cluster API only tells half of the DOKS story. The other half of the story can be explained by Control Plane Clusters (CPC) or workload cluster in CAPI terms. This is where things get DigitalOcean specific in the form of an operator called Customer Cluster Controller. If you’re unfamiliar with the Kubernetes Operator Pattern it is a control loop of logic which updates a custom resource to a desired state when changes are made. This code is typically encapsulated inside a controller.
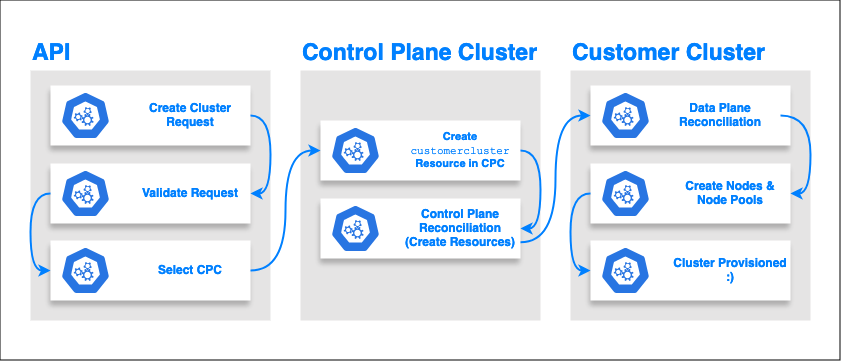
The controller forms the backbone of the service you know (and hopefully!) love. When you request a DOKS cluster behind the scenes a number of things happen:
-
We receive your request via our API and do some basic validations to ensure what you’re asking for makes sense and return an ACK.
-
A CPC will be selected for your cluster using least connection based scheduling - this allows us to equally distribute cluster control planes across a fleet of CPCs to ensure a (mostly) balanced distribution.
-
Asynchronously this request is actually translated to a custom resource inside the chosen CPC representing your cluster. Things such as the requested version, cluster properties such as HA, and node pools. This acts as a trigger to start reconciliation inside the operator making your cluster real.
-
The operator will then start creating the required pods, daemonsets, and certificates that form the basis of your control plane and monitor it until it’s fully available.
-
Once the control plane is available the provisioning is handed to another reconciler to provision the data plane. The data plane is composed of the nodes in your DigitalOcean account and components such as the Kubelet, Cilium, Kube-Proxy etc. The components that live inside the cluster that are managed by DigitalOcean!
-
Finally your cluster is marked as fully provisioned once both the data plane and control plane are functional.
That’s cool! How did that help?
This process is powerful for a number of reasons—first and foremost your control plane is containerised and as such gets all of the management benefits from Kubernetes for free. This often takes care of the fault tolerant and resiliency aspects without additional logic or human intervention. In practice, this means that services are automatically restarted, rescheduled and relocated in the event of a Droplet or hypervisor failure. This is far cry from how things were in the beginning.
By leveraging Kubernetes in Kubernetes (in Kubernetes), scalability is also taken care of.
For example if your Kubernetes API server is suffering from high memory usage from an increase in requests we can use Vertical Pod Autoscaler (VPA) to reactively detect this and increase resources as needed, and scale back down when appropriate. While this does provide significant scalability, the unfortunate reality of the cloud being someone else’s computer (and in this case, ours), means even we have hardware limitations to consider, so the scalability is finite.
Another huge advantage of the CCP architecture was flexibility for the customer. Historically in the Droplet based approach we’d need to provision extra control plane Droplets, wait for these to self bootstrap and join the cluster. This wasn’t a great experience nor really feasible as Droplets are more heavyweight compared to containers and initially prevented us from offering high availability at all! Thankfully that’s no longer the case and enabling HA is a relatively simpler matter of updating deployments and daemonsets to provide additional replicas.
The painful aspects, and what we’ve learnt doing it
We may have underestimated the power of the dark side and thought we had the high ground. This approach presented several challenges which helped our engineers deepen our understanding of low level Kubernetes management. A recurring theme within this was networking, and through this we discovered just how powerful Cilium is.

We really did underestimate Cilium’s power, both in complexity and just how fantastic it really is!
One such example is connectivity between the data plane and the control plane for operations like reading container logs. When the control plane is running within the same subnet as the nodes, fetching logs is a case of the API server making a call to the node and returning them. With the CCP-based architecture this proved challenging, and we ended up needing to run additional components to enable Kubernetes to function as expected.
Another complexity stemming from networking is the multi-tenanted nature of clusters within a CPC,meaning two clusters can coexist quite happily side by side transparently. How do you enforce a positive security model for this to ensure everything is kept secure? With DOKS we achieved this through the use of Cilium and network policies.
When a cluster is provisioned, great care is taken to set up isolating network rules preventing clusters from crossing hard boundaries and keeping your clusters safe both internally and externally.
Finally a significant pain point was acknowledging our approach the first time round wasn’t necessarily the best one! No plan ever survives first implementation and you don’t always hit a home run on the first try. Rather than continuing to develop on the Droplet-based architecture, we opted instead to migrate to a new architecture over time. The painful aspect in this case was essentially re-creating DOKS, taking the knowledge of ‘DOKS V1’ with us.
We’re really happy with the results and are excited to continue delivering more features in future. None of which would be possible without taking a step back to develop a bold change of approach.
Conclusion
While all of this may seem complex, it’s all in the aim to deliver simplicity to the customer which is one of our primary goals. We hope this blog post has been an entertaining read and given you an interesting insight into considerations of running Kubernetes at scale to ultimately provide a great service that you can rely on as a customer.
About the author(s)
BARK BARK BARK BARK BARK BARK BARK BARK BARK BARK BARK BARK
Related Articles

Outperforming Fable 5 at half the price: meet model synthesis, a new server-side tool on DigitalOcean Inference Engine
- July 23, 2026
- 8 min read
Upcoming GPU Pricing Updates
- July 21, 2026
- 2 min read
Scale Faster with Managed Weaviate: Now in Public Preview on DigitalOcean
- July 9, 2026
- 4 min read