AI Technical Writer

Introduction
The rise of text-to-image models marks a transformative shift in the field of artificial intelligence, unlocking new possibilities for creative expression and communication. These models leverage advanced deep learning techniques to generate realistic and contextually relevant images based on textual input. The integration of natural language processing and computer vision has paved the way for applications that can interpret and translate textual descriptions into visually compelling representations. As these models continue to evolve and improve, they hold the potential to revolutionize various industries, including design, entertainment, and education, by providing a seamless bridge between the world of language and imagery.
DeciDiffusion is an open-source, cutting-edge text-to-image latent diffusion model trained on a subset of the LAION dataset and fine-tuned on the LAION-ART dataset. This diffusion model with 1.02 billion parameters surpasses the 1.07 billion parameter Stable Diffusion v1.5 (SD), which is of a similar size, while achieving equivalent quality in image generation with 40% fewer iterations. The model has also proven to be 3X faster than Stable Diffusion v1.5, when run on NVIDIA A10G GPUs. This performance is due to the advanced Neural Architecture Search Technology architecture of the model, which was developed for optimal efficiency.
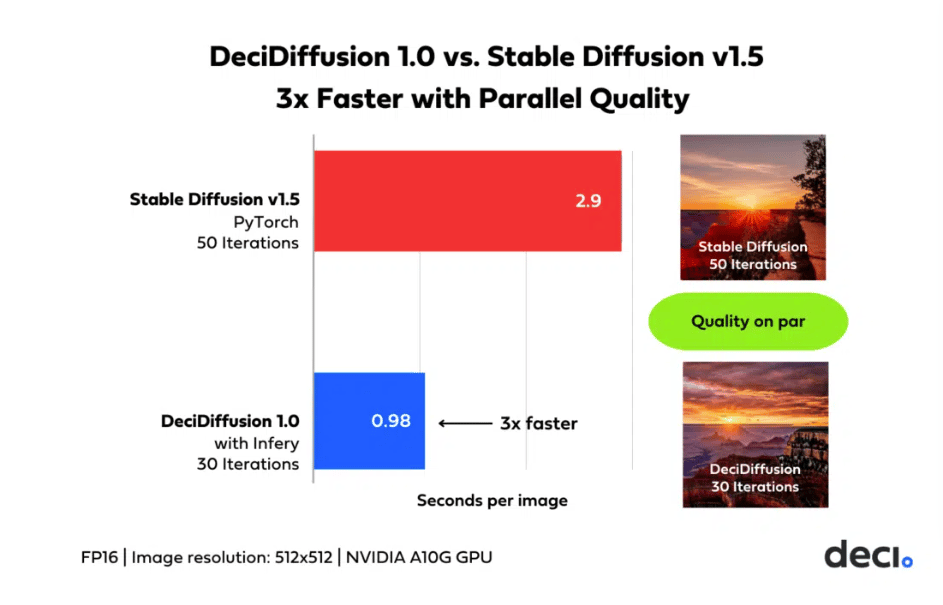
DeciDiffusion performance benchmarking with SD (Source)
DeciDiffusion’s enhanced capabilities are more profound than those of SD. Let us discuss the implications of DeciDiffusion briefly.
The text-to-image generation model holds immense potential in the field of design, art, advertising, content creation, and many other fields. The rise of this technology lies in its seamless ability to effortlessly convert text into vibrant images, representing a significant advancement in AI capabilities. While SD being open source has spurred numerous innovations, it takes a backseat when it comes to the practical challenges in deployment due to its demanding computational requirements, though the rise of Turbo models and distillation may prove that assumption wrong.
These challenges result in noticeable latency and cost issues during training and deployment. In contrast, DeciDiffusion stands out for its superior computational efficiency, ensuring a smoother user experience and an impressive reduction of nearly 66% in production costs. The outcome is a more accessible and feasible landscape for text-to-image generative applications running with the model versus other Latent Diffusion models.
In this article, we will look at what makes DeciDiffusion so powerful and versatile, and then show it with a practical demonstration.
Prerequisites
- Python Environment: Python 3.8 or higher.
- Libraries: PyTorch, Transformers, and Diffusers (latest versions).
- Hardware: NVIDIA GPU (e.g., A100, H100) with CUDA support for accelerated training and inference.
- Basic Knowledge: Understanding of diffusion models, deep learning fundamentals, and model optimization techniques.
Model Architecture
DeciDiffusion 1.0, a text-to-image generation model, builds upon Stable Diffusion’s core architecture, incorporating advancements like the U-Net-NAS design by Deci. This substitution optimizes the model for greater computational efficiency by reducing parameter count while retaining the Variational Autoencoder (VAE) and CLIP’s Text Encoder.
U-Net-NAS
DeciDiffusion is also a latent diffusion model, like Stable Diffusion, however, the architecture is based on U-Net-NAS. Latent diffusion models are probabilistic frameworks capable of producing high-quality images. They initiate the image generation process by transforming random noise into realistic images through a gradual diffusion process. The distinctive feature of these models lies in applying the diffusion process to an encoded latent representation of the image rather than the raw pixel values.
Here are the main steps involved:
- Variational Auto-Encoder (VAE): Variational Autoencoder (VAE) is an AutoEncoder architecture that undergoes regularization of its encoding distribution during training. This regularization ensures favorable properties in its latent space, facilitating the generation of new data. The term “variational” is derived from the strong connection between this regularization and the variational inference method in statistics. In a nutshell, VAEs convert images into latent representations and vice versa. Throughout training, the encoder transforms an image into a latent version, and the decoder reverses this process during both training and inference.
- U-Net: Named after its architectural design, U-Net features a “U” shaped model consisting of convolutional layers and two networks—the encoder followed by the decoder. This model effectively addresses the segmentation questions of “what” and “where.”
- Text Encoder: This encoder is responsible for transforming textual prompts to latent text embeddings which is further used by the U-Net decoder.
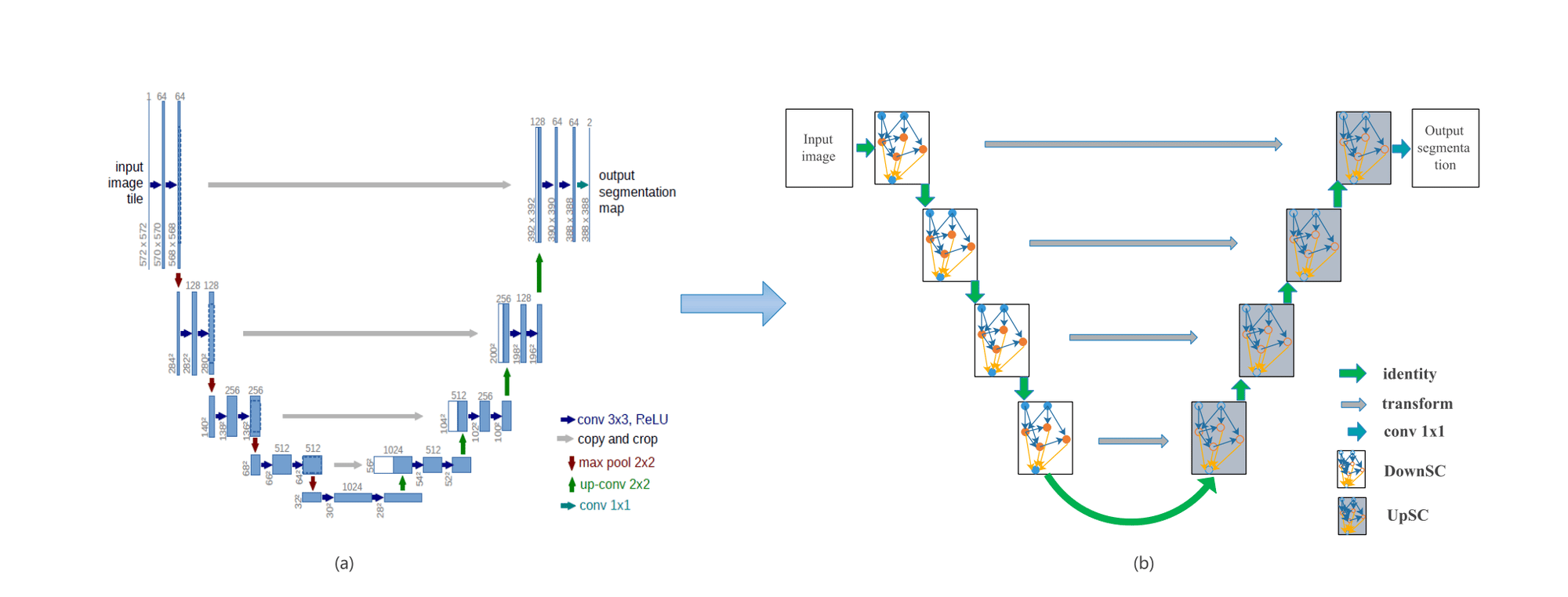
(a) U-Net architecture (b) The U-like backbone of Nas-Unet architecture (Source)
In this architecture two types of cell architectures are defined, called DownSC and UpSC based on U-like backbone. DeciDiffusion stands out for its unique feature: the flexible composition of each block, optimizing the number of ResNet and Attention blocks for peak performance with minimal computations. By adopting the efficient U-Net-NAS in DeciDiffusion, characterized by fewer parameters, the model reduces computational demands, making it a more resource-efficient alternative to Stable Diffusion.
The model has been trained on 4 stages:
- Phase 1: Trained for 1.28 million steps at a resolution of 256x256 using a subset of 320 million samples from LAION-v2, starting from scratch.
- Phase 2: Further training involved 870k steps at a 512x512 resolution on the same dataset to capture finer details.
- Phase 3: Conducted training for 65k steps using Exponential Moving Average (EMA), an additional learning rate scheduler, and incorporating more “qualitative” data.
- Phase 4: Fine-tuning using a 2M sample subset of LAION-ART.
Hardware Requirements for Training
| Category | Phase 1 | Phase 2-4 |
|---|---|---|
| Hardware | 8 × 8 × A100 (80GB) | 8 × 8 × H100 (80GB) |
| Optimizer | AdamW | LAMB |
| Batch Size | 8192 | 6144 |
| Learning Rate | 1e-4 | 5e-3 |
The hardware requirements for training DeciDiffusion were quite high, requiring significant computational power to handle the intensive processing involved. Therefore, we recommend using a GPU Droplet by DigitalOcean to streamline your workflow and optimize performance without investing in costly infrastructure.
DeciDiffusion in action
Follow the steps to use this model and produce some mind-blowing images!
*Install the necessary packages
#install the packages using pip
!pip install --quiet git+https://github.com/huggingface/diffusers.git@d420d71398d9c5a8d9a5f95ba2bdb6fe3d8ae31f
!pip install --quiet ipython-autotime
!pip install --quiet transformers==4.34.1 accelerate==0.24.0 safetensors==0.4.0
!pip install --quiet ipyplot
%load_ext autotime
*Import the Libraries and necessary packages
#import necessary libraries
from diffusers import StableDiffusionPipeline, DiffusionPipeline
import torch
import ipyplot
import time
*Loads the pre-trained checkpoint, “DeciDiffusion-v1-0” for a Stable Diffusion pipeline. Run the model with two prompts. The resulting images are stored in the ‘img’ and ‘img2’ variables.
#set the device and load the pre-trained model
device = 'cuda' if torch.cuda.is_available() else 'cpu'
checkpoint = "Deci/DeciDiffusion-v1-0"
#biuld the decidiffusion pipeline
pipeline = StableDiffusionPipeline.from_pretrained(checkpoint, custom_pipeline=checkpoint, torch_dtype=torch.float16)
pipeline.unet = pipeline.unet.from_pretrained(checkpoint, subfolder='flexible_unet', torch_dtype=torch.float16)
pipeline = pipeline.to(device)
#generate images by passing prompt
img = pipeline(prompt=['A photo of an astronaut riding a horse on Mars']).images[0]
img2 = pipeline(prompt=['A big owl with bright shinning eyes']).images[0]

*Images Produced by DeciDiffusion
Comparison of DeciDiffusion with Stable Diffusion v1.5
Time taken by the SD model to generate the images:

Images Generated by SD. Image creation times were 2.96, 2.93, 2.94, and 2.93 seconds.
Time taken by DeciDiffusion model to generate the images:

Images Generated by DeciDiffusion. Image creation times were 1.11, 1.08, 1.09, and 1.08 seconds.
DeciDiffusion’s improved latency is a result of advancements in its architecture, efficient training techniques enhancing sample efficiency, and the integration of Infery, Deci’s easy-to-use SDK, can increase this even further. This combination results in significant cost savings during inference operations. Firstly, it provides flexibility in hardware selection, enabling a transition from high-end A100/H100 GPUs to the more budget-friendly A10G without sacrificing performance (we still recommend using an A100-80G or H100). Moreover, when compared on the same hardware, DeciDiffusion proves highly cost-effective, with a 66% reduction in cost compared to Stable Diffusion for every 10,000 generated images.
Concluding Thoughts
DeciDiffusion represents a crucial advancement for generative AI applications. This not only optimizes real-time projects in content creation and advertising but also leads to substantial reductions in operational costs. In this article, we compared DeciDiffusion with SD, and it can be concluded that the model is faster and more efficient than SD for both training and use for inference. However, it is worth mentioning that the model is not intended to generate accurate or truthful representations of people or events. Therefore, employing it for such purposes goes beyond its designated capabilities. Also, the model has its limitations. Here are a few of them:
- The model is unable to produce completely photorealistic images. Artifacting is common
- Complex compositions are still a challenge to the model and the autoencoding aspect of the model is still a loss.
- The generation of perfect faces and human figures is, in fact challenge for every diffusion model.
- DeciDiffusion is primarily optimized for English captions and is not effective with other languages.
Nevertheless, the model has its own perks especially when it comes to its computation power and cost effectiveness. Along with this article we have provided two notebooks based on DeciDiffusion and Stable Diffusion. We encourage users to utilize these notebooks in conjunction with the article for an enriched experience.
Model Details and Resource
- Model Developed by: Deci
- Model type: Latent Diffusion-based text-to-image generation model
- Code License: The code in this repository is released under the Apache 2.0 License
- Weights License: The weights are released under the CreativeML Open RAIL+±M License
- DeciDiffusion Hugging Face: https://huggingface.co/Deci/DeciDiffusion-v1-0
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
