By Adil Lheureux
 neural network")
Understanding how neural networks are built is becoming more important as AI research grows. Two main types of structures—feedforward and (recurrent) neural networks—offer different ways of handling information. Neural networks are the backbone of many modern artificial intelligence systems, but not all neural networks are built the same. Two important types are feedforward and or recurrent neural networks.
While both are designed to process information and recognize patterns, they differ significantly in how data moves through them and the types of problems they are best suited to solve. In a feedforward network, information moves in one direction — from input to output — without any loops. These networks are great for tasks like image recognition and basic predictions.
networks, on the other hand, have loops that let them remember past information, making them perfect for things like understanding speech or analyzing time-based data. Knowing the difference between these two types helps us choose the right model for different kinds of AI problems.
In this article, we’ll break down both types, explain how they work, and compare their performance through simple examples and real-world use cases.
Prerequisites
Before diving into this article, it will help if you have:
- A basic understanding of how neural networks work.
- Familiarity with terms like neurons, layers, inputs, and outputs.
- A general idea of machine learning and AI concepts.
First, let’s start with the basics.
What is a Neural Network?
The fundamental building block of deep learning, a neural network is a computational model used to recognize patterns and make predictions or decisions based on data. The main inspiration behind this is the way the human brain functions, it consists of layers of neurons (also called nodes) connected by synapses. These neurons work together to process data and learn from it in a way that allows the network to improve its performance over time.
The structure of a neural network typically includes three main components:
-
Input Layer:
- This is where the neural network receives data.
- Each neuron in the input layer represents one feature or piece of information from the data. For example, in an image classification task, the pixels of an image could be the features input into the network.
-
Hidden Layers:
- These layers sit between the input and output layers and do most of the computation.
- Each neuron in a hidden layer takes input from the neurons of the previous layer, processes the data using mathematical functions, and passes the result to the next layer.
- Hidden layers allow the network to learn complex patterns and relationships in the data. The more hidden layers there are, the deeper the network becomes, allowing it to capture intricate features of the data.
-
Output Layer:
- The final layer of the neural network is where the processed data is transformed into a prediction or classification result.
- For example, in a classification task, the output layer might give the probability of the input data belonging to each class.
The learning process in a neural network involves adjusting the weights of the connections between neurons in order to reduce the difference between the network’s output and the actual result (the error or loss).

How Does a Neural Network Learn?
Let us discuss the working of the neural network:
-
Forward Propagation:
- The data is passed through the network, starting from the input layer, moving through the hidden layers, and finally reaching the output layer. This is called forward propagation.
- In each layer, the neurons perform mathematical operations, often using a function called an activation function to introduce non-linearity to the network. This helps the network learn complex patterns that are not just linear combinations of the input.
-
Backpropagation:
- After the output is generated, the network compares it to the correct output (the target) and calculates the error.
- Backpropagation is the process of sending the error back through the network to adjust the weights of the connections between neurons. The goal is to reduce this error over time, which is done using optimization algorithms like gradient descent.
- This process is repeated many times during training, with the weights being adjusted slightly each time, until the network is able to make predictions that are accurate enough for the task.
Elements of Neural Networks
The neurons that make up the neural network architecture replicate the organic behavior of the brain.
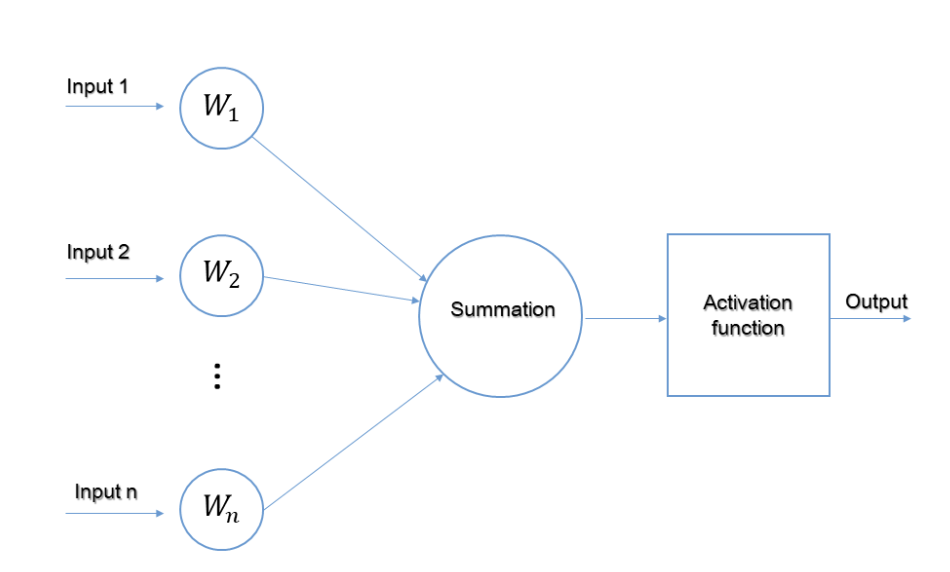
Elementary structure of a single neuron in a Neural Network
Now, we will define the various components related to the neural network and show how we can, starting from this basic representation of a neuron, build some of the most complex architectures.
Input
It is the collection of data (i.e, features) that is input into the learning model. For instance, an array of current atmospheric measurements can be used as the input for a meteorological prediction model.
Weight
Giving importance to features that help the learning process the most is the primary purpose of using weights. By adding scalar multiplication between the input value and the weight matrix, we can increase the effect of some features while lowering it for others. For instance, the presence of a high pitch note would influence the music genre classification model’s choice more than other average pitch notes that are common between genres.
Activation Function
In order to take into account changing linearity with the inputs, the activation function introduces non-linearity into the operation of neurons. Without it, the output would simply be a linear combination of the input values, and the network would not be able to accommodate non-linearity.
The most commonly used activation functions are: Unit step, sigmoid, piecewise linear, and Gaussian.

Illustrations of the common activation functions
Bias
The purpose of bias is to change the value that the activation function generates. Its function is comparable to a constant in a linear function. So, it’s a shift for the activation function output.
Layers
An artificial neural network is made of multiple neural layers stacked on top of one another. Each layer consists of several neurons stacked in a row. We distinguish three types of layers: Input, hidden, and Output.
Input Layer
The input layer of the model receives the data that we introduce to it from external sources like images or a numerical vector. It is the only layer that can be seen in the entire design of a neural network that transmits all of the information from the outside world without any processing.
Hidden Layers
The hidden layers are what make deep learning what it is today. They are intermediary layers that do all the calculations and extract the features of the data. The search for hidden features in data may comprise many interlinked hidden layers. In image processing, for example, the first hidden layers are often in charge of higher-level functions such as the detection of borders, shapes, and boundaries. The later hidden layers, on the other hand, perform more sophisticated tasks, such as classifying or segmenting entire objects.
Output Layer
The final prediction is made by the output layer using data from the preceding hidden layers. It is the layer from which we acquire the final result, hence it is the most important.
In the output layer, classification and regression models typically have a single node. However, it is fully dependent on the nature of the problem at hand and how the model was developed. Some of the most recent models have a two-dimensional output layer. For example, Meta’s new Make-A-Scene model that generates images simply from text at the input.
How do these layers work together?
The input nodes receive data in a form that can be expressed numerically. Each node is assigned a number; the higher the number, the greater the activation. The information is displayed as activation values. The network then spreads this information outward. The activation value is sent from node to node based on connection strengths (weights) to represent inhibition or excitation.
Each node adds the activation values it has received before changing the value by its activation function. The activation travels via the network’s hidden levels before arriving at the output nodes. The input is then meaningfully reflected to the outside world by the output nodes. The error, which is the difference between the projected value and the actual value, is propagated backward by allocating the weights of each node to the proportion of the error that each node is responsible for.
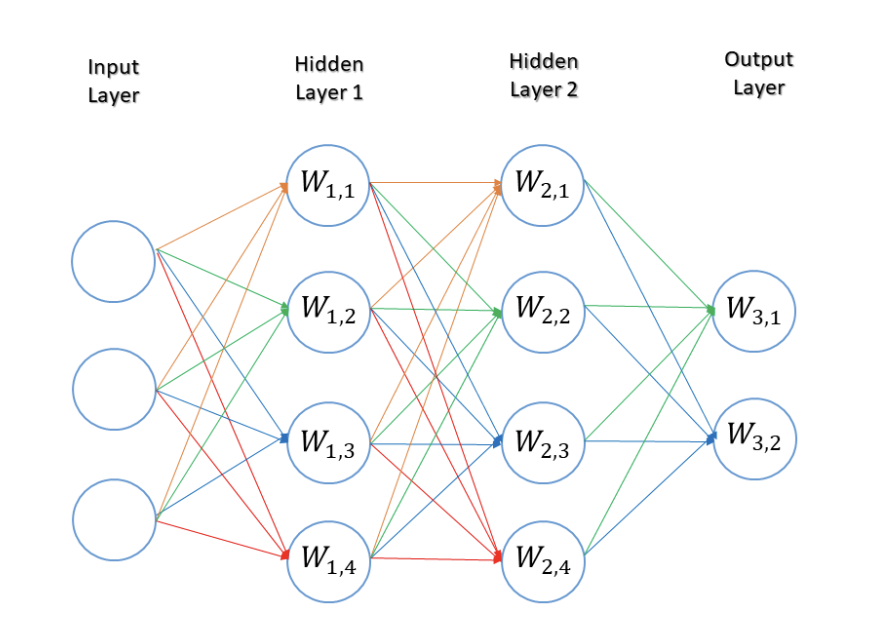
Example of a basic neural network
The neural network in the above example comprises an input layer composed of three input nodes, two hidden layers based on four nodes each, and an output layer consisting of two nodes.
Structure of Feedforward Neural Networks
In a feedforward network, signals can only move in one direction. These networks are considered non-recurrent networks with inputs, outputs, and hidden layers. A layer of processing units receives input data and executes calculations there. Based on a weighted total of its inputs, each processing element performs its computation. The newly derived values are subsequently used as the new input values for the subsequent layer. This process continues until the output has been determined after going through all the layers.
Perceptron (linear and non-linear) and Radial Basis Function networks are examples of feedforward networks. A single-layer perceptron network is the most basic type of neural network. It has a single layer of output nodes, and the inputs are fed directly into the outputs via a set of weights. Each node calculates the total of the products of the weights and the inputs. This neural network structure was one of the first and most basic architectures to be built.

Learning is carried out on a multi-layer feedforward neural network using the back-propagation technique. The properties generated for each training sample are stimulated by the inputs. The hidden layer is simultaneously fed the weighted outputs of the input layer. The weighted output of the hidden layer can be used as input for additional hidden layers, etc. The employment of many hidden layers is arbitrary; often, just one is employed for basic networks.
The units making up the output layer use the weighted outputs of the final hidden layer as inputs to spread the network’s prediction for given samples. Due to their symbolic biological components, the units in the hidden layers and output layer are depicted as neurons or as output units.
Convolutional neural networks (CNNs) are one of the most well-known iterations of the feedforward architecture. They offer a more scalable technique to image classification and object recognition tasks by using concepts from linear algebra, specifically matrix multiplication, to identify patterns within an image.
Below is an example of a CNN architecture that classifies handwritten digits

An Example CNN architecture for a handwritten digit recognition task (source)
Through the use of pertinent filters, a CNN may effectively capture the spatial and temporal dependencies in an image. Because there are fewer factors to consider and the weights can be reused, the architecture provides a better fit to the image dataset. In other words, the network may be trained to better comprehend the level of complexity in the image.
How is a Feedforward Neural Network trained?
The typical algorithm for this type of network is back-propagation. It is a technique for adjusting a neural network’s weights based on the error rate recorded in the previous epoch (i.e., iteration). By properly adjusting the weights, you may lower error rates and improve the model’s reliability by broadening its applicability.
The gradient of the loss function for a single weight is calculated by the neural network’s back propagation algorithm using the chain rule. In contrast to a native direct calculation, it efficiently computes one layer at a time. Although it computes the gradient, it does not specify how the gradient should be applied. It broadens the scope of the delta rule’s computation.

Illustration of the back-propagation algorithm
Structure of Neural Networks
A feedback network, such as a recurrent neural network (RNN), features feedback paths, which allow signals to use loops to travel in both directions. Neuronal connections can be made in any way. Since this kind of network contains loops, it transforms into a non-linear dynamic system that evolves during training continually until it achieves an equilibrium state.
In research, RNNs are the most prominent type of feedback networks. They are an artificial neural network that forms connections between nodes into a directed or undirected graph along a temporal sequence. It can display temporal dynamic behavior as a result of this. RNNs may process input sequences of different lengths by using their internal state, which can represent a form of memory. They can therefore be used for applications like speech recognition or handwriting recognition.

Example of a feedback neural network
How is a Feedback Neural Network trained?
Back-propagation through time or BPTT is a common algorithm for this type of networks. It is a gradient-based method for training specific recurrent neural network types. And, it is considered as an expansion of feedforward networks’ back-propagation with an adaptation for the recurrence present in the feedback networks.
CNN vs RNN
As was already mentioned, CNNs are not built like an RNN. RNNs send results back into the network, whereas CNNs are feedforward neural networks that employ filters and pooling layers.
Application-wise, CNNs are frequently employed to model problems involving spatial data, such as images. When processing temporal, sequential data, like text or image sequences, RNNs perform better.
These differences can be grouped in the table below:
| Convolution Neural Networks (CNNs) | Recurrent Neural Networks (RNNs) | |
|---|---|---|
| Architecture | Feedforward neural network | Feedback neural network |
| Layout | Multiple layers of nodes, including convolutional layers | Information flows in different directions, simulating a memory effect |
| Data type | Image data | Sequence data |
| Input/Output | The size of the input and output is fixed (i.e, input image with fixed size and outputs the classification) | The size of the input and output may vary (i.e, receiving different texts and generating different translations, for example) |
| Use cases | Image classification, recognition, medical imagery, image analysis, face detection | Text translation, natural language processing, language translation, sentiment analysis |
| Drawbacks | Large training data | Slow and complex training procedures |
| Description | CNN employs neuronal connection patterns. They are inspired by the arrangement of the individual neurons in the animal visual cortex, which allows them to respond to overlapping areas of the visual field. | Time-series information is used by recurrent neural networks. For instance, a user’s previous words could influence the model prediction on what he can says next. |
Architecture examples: AlexNet
Alex Krizhevsky developed AlexNet, a significant Convolutional Neural Network (CNN) architecture. This network comprised eight layers: five convolutional layers (some followed by max-pooling) and three fully connected layers. AlexNet notably employed the non-saturating ReLU activation function, which proved more efficient in training compared to tanh and sigmoid. Widely regarded as a pivotal work in computer vision, the publication of AlexNet spurred extensive subsequent research leveraging CNNs and GPUs for accelerated deep learning. By 2022, the AlexNet paper had received over 69,000 citations.

AlexNet Architecture with Pyramid Pooling and Supervision (source)
LeNet
Yann LeCun suggested the convolutional neural network topology known as LeNet. One of the first convolutional neural networks, LeNet-5, aided in the advancement of deep learning. LeNet, a prototype of the first convolutional neural network, possesses the fundamental components of a convolutional neural network, including the convolutional layer, pooling layer, and fully connected layer, providing the groundwork for its future advancement. LeNet-5 is composed of seven layers, as depicted in the figure.

Structure of LeNet-5 (source)
Long short-term memory (LSTM)
LSTM networks are one of the prominent examples of RNNs. These architectures can analyze complete data sequences in addition to single data points. For instance, LSTM can be used to perform tasks like unsegmented handwriting identification, speech recognition, language translation and robot control.
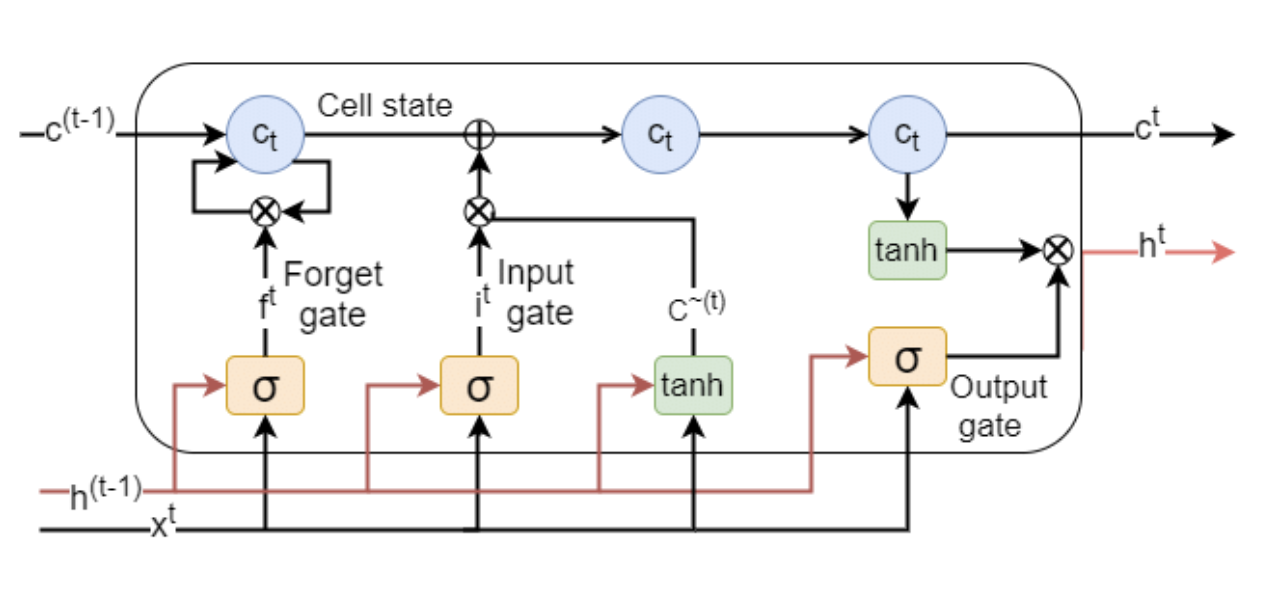
Long Short Term Memory (LSTM) cell (source)
LSTM networks are constructed from cells (see figure above), the fundamental components of an LSTM cell are generally : forget gate, input gate, output gate and a cell state.
Gated recurrent units (GRU)
This RNN derivative is comparable to LSTMs since it attempts to solve the short-term memory issue that characterizes RNN models. The GRU has fewer parameters than an LSTM because it doesn’t have an output gate, but it is similar to an LSTM with a forget gate. It was discovered that GRU and LSTM performed similarly on some music modeling, speech signal modeling, and natural language processing tasks. GRUs have demonstrated superior performance on several smaller, less frequent datasets.

Diagram of the gated recurrent unit cell (Source)
Use cases
Depending on the application, a feedforward structure may work better for some models while a feedback design may perform effectively for others. Here are a few instances where choosing one architecture over another was preferable.
Forecasting currency exchange rates
In a study on modeling the Japanese yen exchange rates, the feedforward model proved to be remarkably straightforward and simple to apply. Despite this simplicity, the model demonstrated strong accuracy in predicting both price levels and price direction for out-of-sample data. Interestingly, the feedforward model outperformed the recurrent network in forecast performance. This could be due to the inherent challenges of models, which often face confusion or instability as they require data to flow both from forward to backward and vice versa.
Recognition of Partially Occluded Objects
There is a widespread perception that feedforward processing is used in object identification. Recurrent top-down connections for occluded stimuli may be able to reconstruct lost information in input images. The Frankfurt Institute for Advanced Studies’ AI researchers looked into this topic. They have demonstrated that for occluded object detection, recurrent neural network architectures exhibit notable performance improvements. Similar findings were reported in the Journal of Cognitive Neuroscience. The experiment and model simulations conducted by the authors emphasize the limitations of the feedforward model in vision tasks. They argue that object recognition is a dynamic and highly interactive process that depends on the collaboration of multiple brain areas, highlighting the complexity beyond simple feedforward processing.
Image classification
In some instances, simple feedforward architectures outperform recurrent networks when combined with appropriate training approaches. For instance, ResMLP, an architecture for image classification that is solely based on multi-layer perceptrons. A research project showed the performance of such a structure when used with data-efficient training. It was demonstrated that a straightforward residual architecture with residual blocks made up of a feedforward network with a single hidden layer and a linear patch interaction layer can perform surprisingly well on ImageNet classification benchmarks if used with a modern training method like the ones introduced for transformer-based architectures.
Text classification
As previously discussed, RNNs are the most successful models for text classification problems. A study proposed three distinct information-sharing strategies to represent text with shared and task-specific layers. All of these tasks are jointly trained over the entire network. The proposed RNN models showed high performance for text classification, according to experiments on four benchmark text classification tasks.
Another paper proposed an LSTM-based sentiment categorization method for text data. This LSTM technique demonstrated sentiment categorization performance with an accuracy rate of 85%, which is considered high for sentiment analysis models.
Conclusion
To put it simply, different tools are required to solve various challenges. It’s crucial to understand and describe the problem you’re trying to tackle when you first begin using machine learning. It takes a lot of practice to become competent enough to construct something on your own; therefore, increasing knowledge in this area will facilitate implementation procedures.
In this post, we looked at the differences between feedforward and feedback neural network topologies. Then we explored two examples of these architectures that have moved the field of AI forward: convolutional neural networks (CNNs) and recurrent neural networks (RNNs). We then gave examples of each structure along with real-world use cases.
Resources
- https://link.springer.com/article/10.1007/BF00868008
- https://arxiv.org/pdf/2104.10615.pdf
- https://dl.acm.org/doi/10.1162/jocn_a_00282
- https://arxiv.org/pdf/2105.03404.pdf
- https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- https://www.ijcai.org/Proceedings/16/Papers/408.pdf
- https://www.ijert.org/research/text-based-sentiment-analysis-using-lstm-IJERTV9IS050290.pdf
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.