AI Technical Writer

In this guide, we’ll show you how to quickly set up and use DigitalOcean’s one-click, pre-configured Hugging Face Llama 3.1 model on a DigitalOcean GPU Droplet. We’ll walk you through the simple process so you can get started right away. We’ll also cover what makes Llama 3.1 unique compared to previous Llama models and understand three fundamental concepts from Hugging Face: Transformers, Pipelines, and Tokenizers.
Introduction
In July 2024, Meta launched Llama 3.1 with its three variants: 405B, 70B, and 8B. The biggest model in this release is the 405B model pre-trained on ~15 trillion tokens, which can now compete with the top AI models. It excels in general knowledge, math, tool use, and multilingual translation, which means it can handle complex tasks just as well as leading AI models.
What makes Llama 3.1 special is how it opens up new opportunities for AI innovation. The 405B model can help generate synthetic data and train smaller models more efficiently, which we haven’t seen at this scale in open-source AI before.
Along with the 405B model, Llama 3.1 also introduces upgraded 8B and 70B models. These versions now support multiple languages, have a longer context length of 128K tokens, and show improved reasoning skills. This makes them perfect for tasks like summarizing long texts, building multilingual chatbots, and creating coding assistants.
Meta has updated the license for these models to support developers. We can now use the outputs from Llama models to improve other models, hence more freedom to innovate. As always, staying true to the spirit of open source, these models can be downloaded from llama.meta.com and Hugging Face or start using them right away.
Prerequisites
- Make sure to get access to a high-performance GPU (e.g., NVIDIA A100, H100) for efficient model inference and training.
- Basic knowledge of Python.
- Understanding of transformers, datasets, and accelerate libraries from Hugging Face (pip install transformers datasets accelerate).
- Familiarity with deep learning concepts and using pre-trained models.
- Experience with PyTorch and Hugging Face’s transformers library is recommended.
Llama 3.1
Llama 3.1 has been extensively tested on over 150 benchmark datasets covering many languages. A detailed human evaluation was performed to see how Llama 3.1 compares to other models in real-world situations. The results show that the primary model is on par with top models like GPT-4, GPT-4o, and Claude 3.5 Sonnet across various tasks. Even the smaller models performed well against other open and closed models with a similar number of parameters.
1-Click Models powered by Hugging Face
DigitalOcean recently announced 1-click model powered by Hugging Face. This feature lets users deploy popular generative AI models directly on DigitalOcean GPU Droplets, making it easier and faster to launch AI applications. With 1-Click Models, users can deploy AI models in just a few minutes. This new integration streamlines AI deployment, combining the simplicity of DigitalOcean with Hugging Face’s robust platform.
How To Quickly Setup Pre-configured Hugging Face AI Models on DigitalOcean GPU Droplets
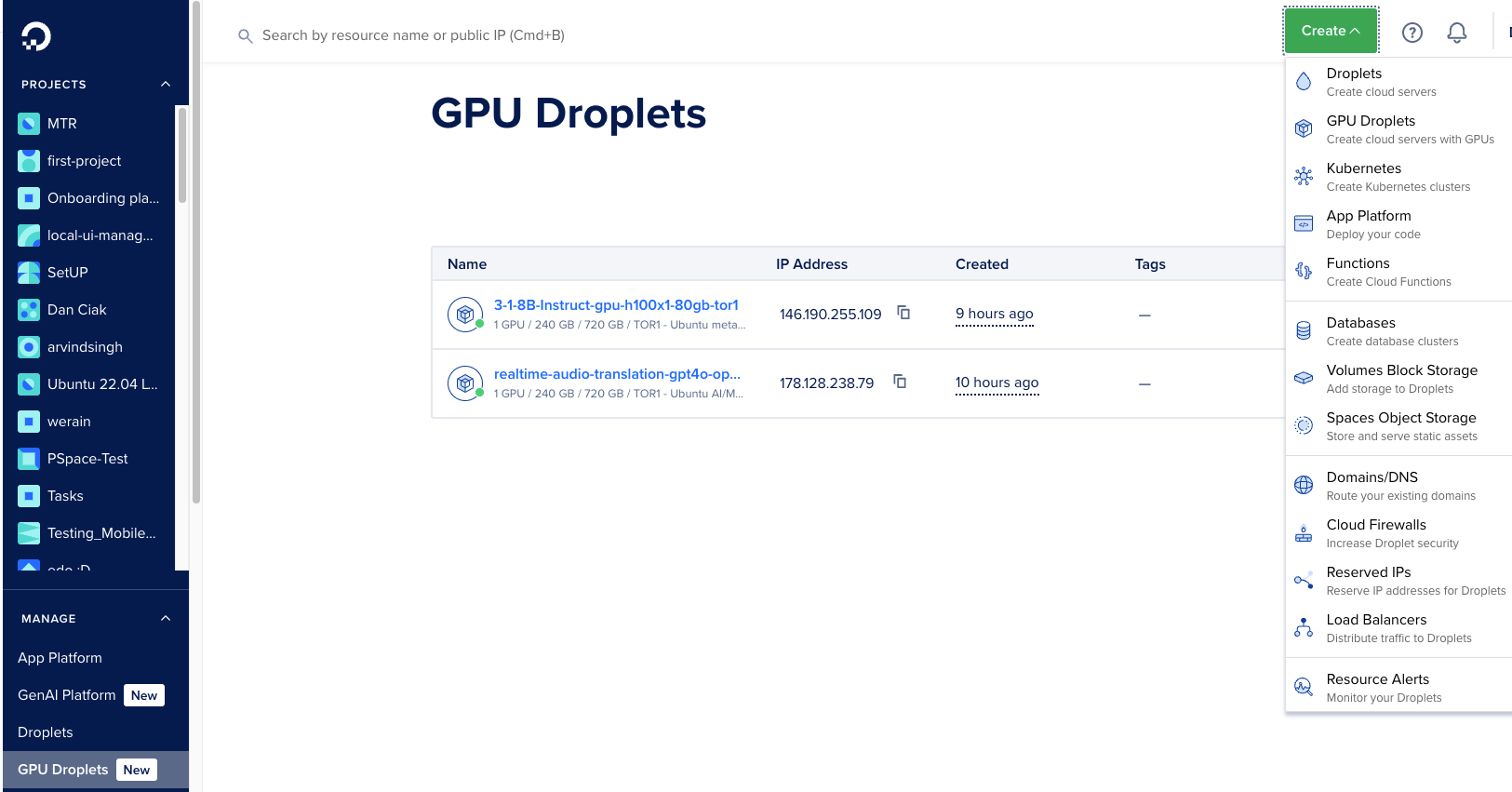
- First, we will sign up for a DigitalOcean account and access the dashboard. Next, we will click “GPU Droplet” or select “Create” to launch a GPU Droplet.
- Choose a data center region for the GPU Droplet by selecting one of the two available regions. Currently, DigitalOcean offers only these two regions, but more will be available worldwide.

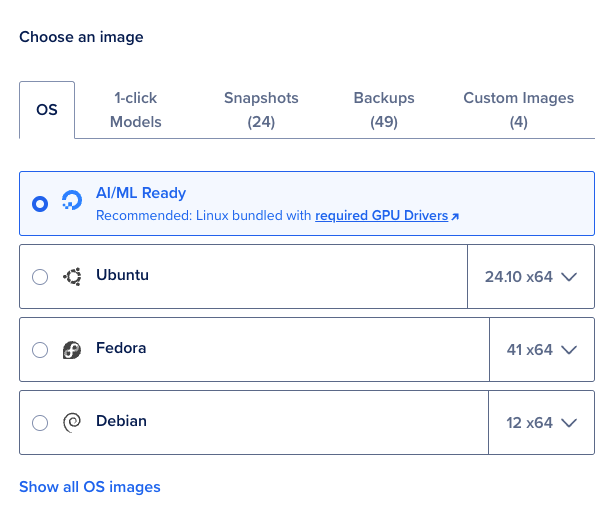
- Next, we will select an image that is set to “OS” by default. Be sure to change it to “1-click Models.” This will allow us to choose a popular model that is pre-configured by Hugging Face to run on a GPU Droplet.
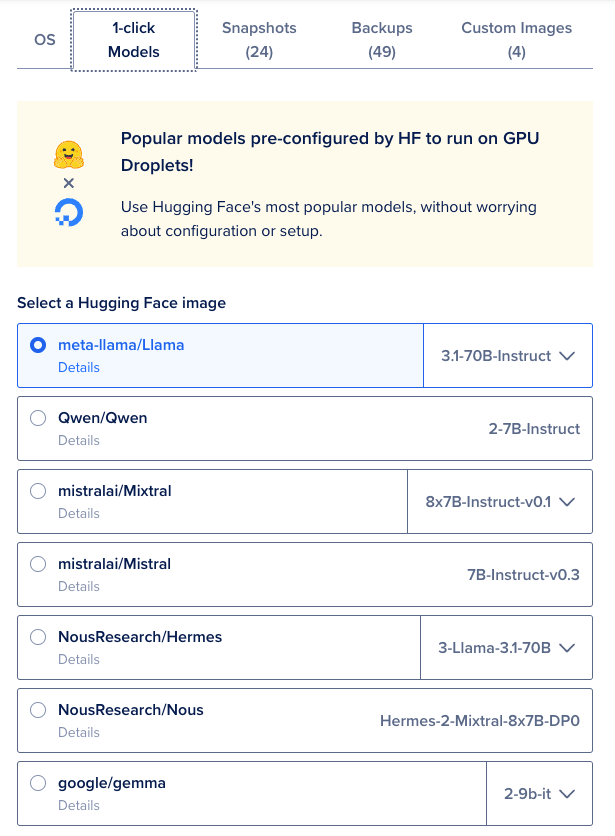
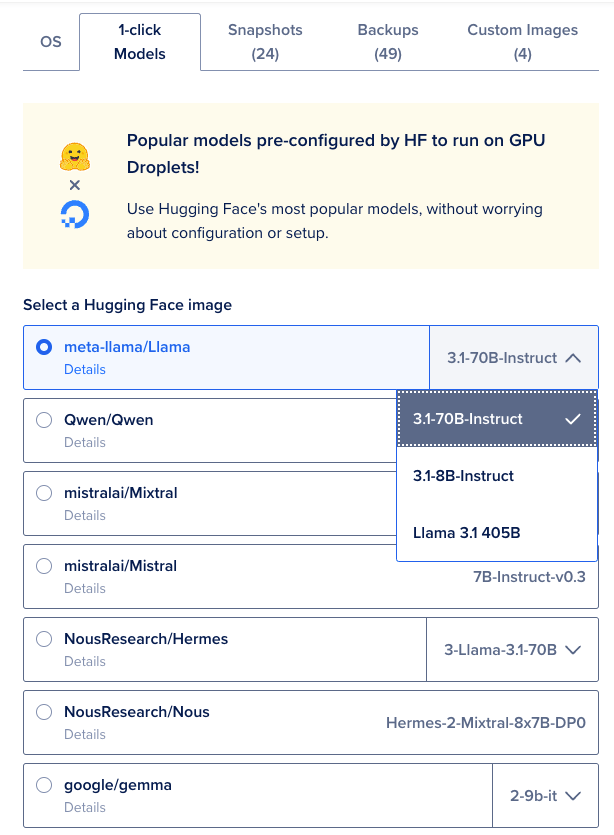
- Select “meta-llama/Llama” and choose the model version using the dropdown menu next to it.
- Scroll down to choose the GPU plan. Currently, DigitalOcean offers the NVIDIA H100x8, which comes with 8 GPUs—640 GB VRAM—160 vCPU—1920 GB RAM, or you can pick a single NVIDIA H100, which comes with 1 GPU—80 GB VRAM—20 vCPU—240 GB RAM.
- Next, let’s add the SSH key for authentication. We have included a link to an article that explains how to do this. Feel free to check out the article to learn more about the process.
- All that remains is to select a unique name and click “Create GPU Droplet.” Once completed, we will see a green status indicator showing that the droplet has been successfully created.
- Next, navigate to the “Connection Details” tab, which displays the IPv4 address. This address will enable us to connect to the GPU Droplet. Click the copy button to copy the address. Then, select the “Web Console” option to open the web console.
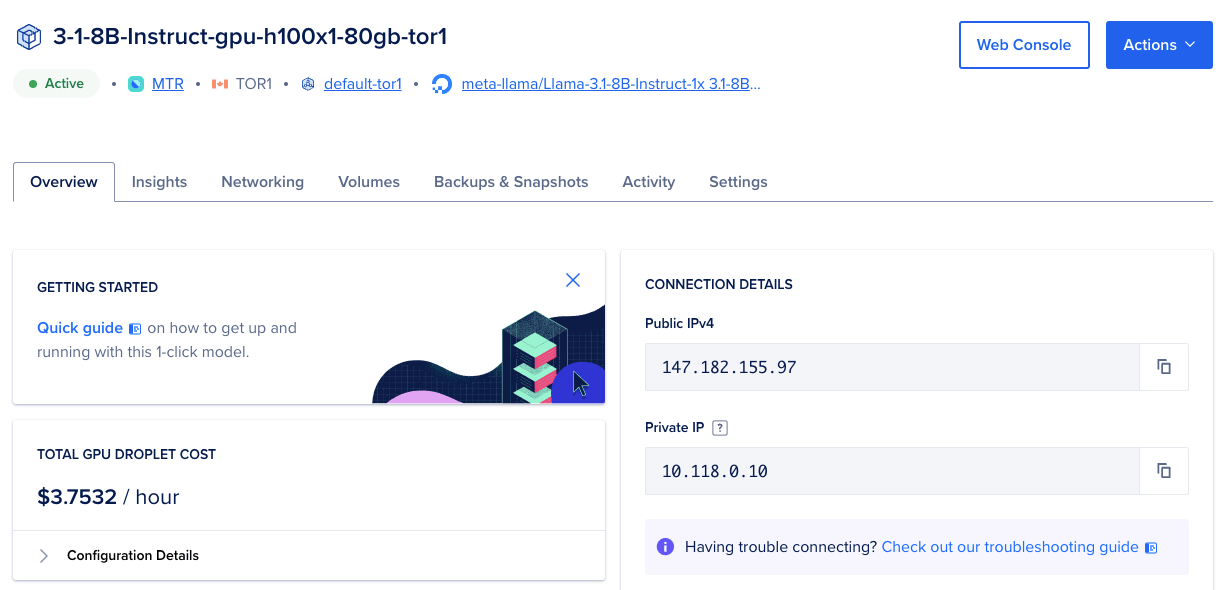
- Before proceeding, let’s open another tab and navigate to the URL ai-models to find the AI 1-Click Models we have installed. Locate the model we are using, Llama 3.1-8B-Instruct, and click on it to view its details.

- Scroll down to find the curl command. This command will enable us to make a local API call to interact with the model. We will copy and paste this command into a notepad.
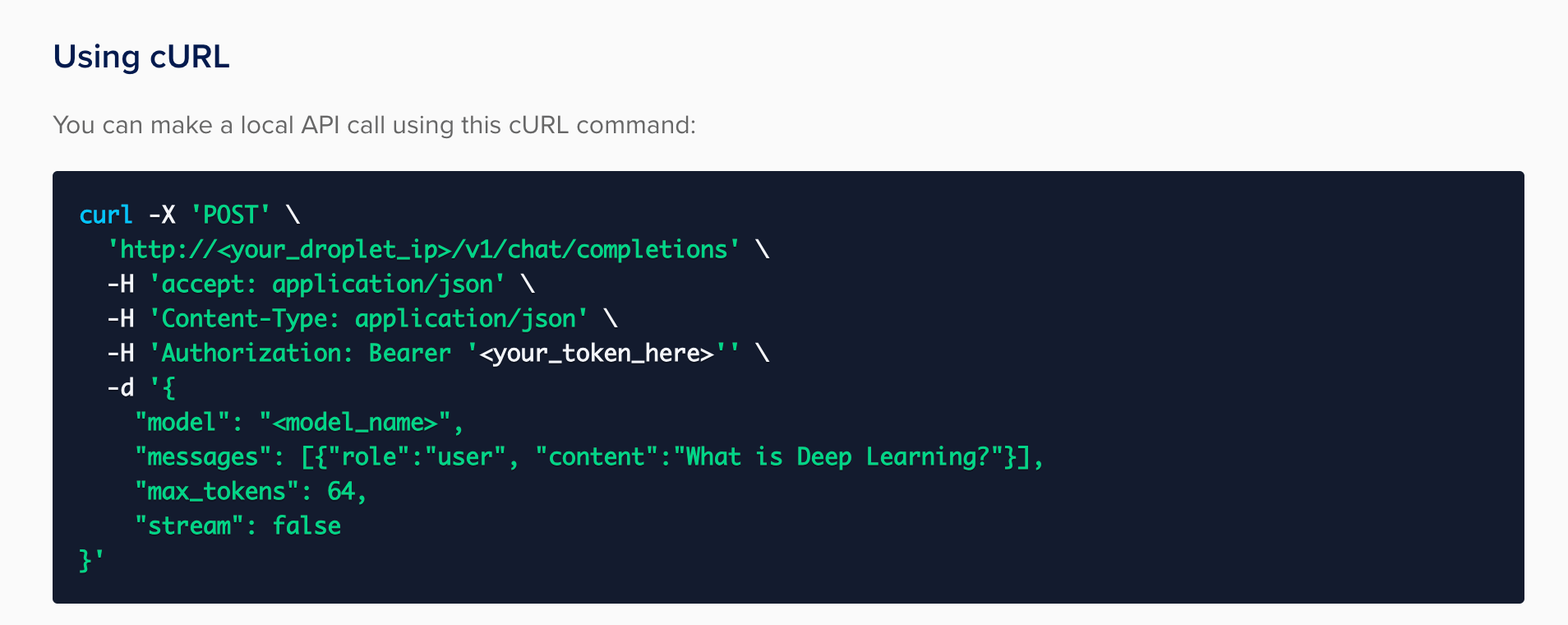
- In the curl command, we will add a -v option before the -X and replace droplet_ip with the copied IPv4 address.
- Additionally, delete the entire line that mentions “model”: “<model_name>”, and move that line up in the document. We’ll leave this here for now and proceed to the web console.
- Copy the “Bearer Token” from our web console. We will add this token to our curl command to interact with the 1-Click Models.
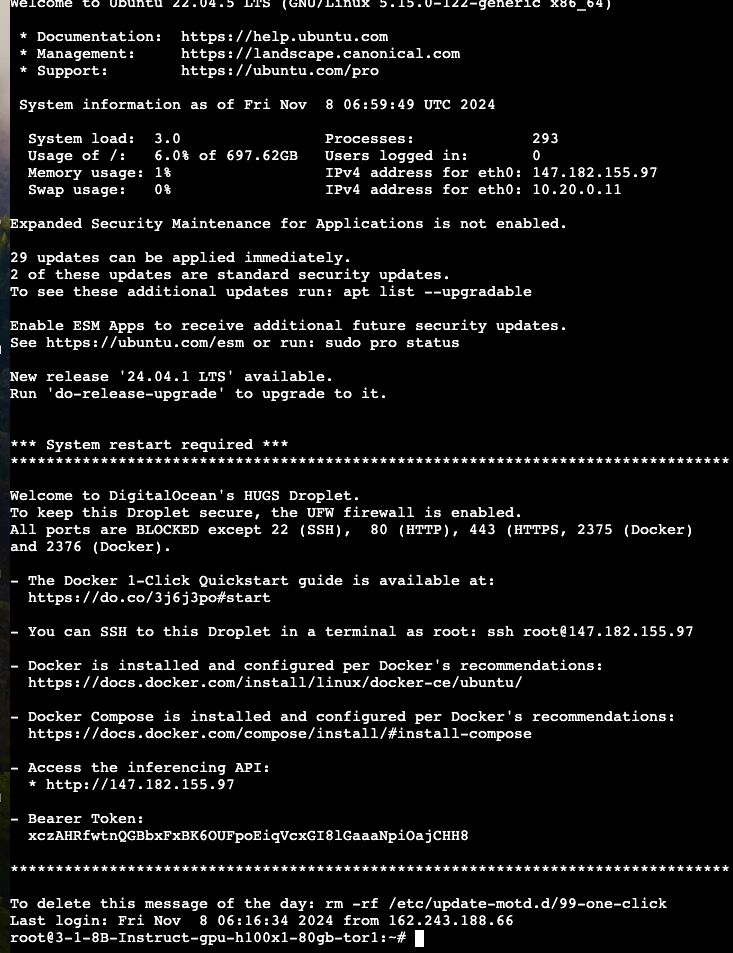
- Next, open the notepad where we copied the curl command and paste the “Bearer Token” into -H ‘Authorization: Bearer token.’
curl -v -X 'POST' \
'http://147.182.1xx.00/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer 'xczAHRfwtnQGBbxFxBK6OUFpoEiqVcxGI8lGaaaNpiOajCHH8'' \
-d '{
"messages": [{"role":"user", "content":"What is deep learning?”}],
"max_tokens": 64,
"stream": false
}'
- Copy the complete curl command, paste it into the terminal, and hit enter. You can also modify the question as needed.
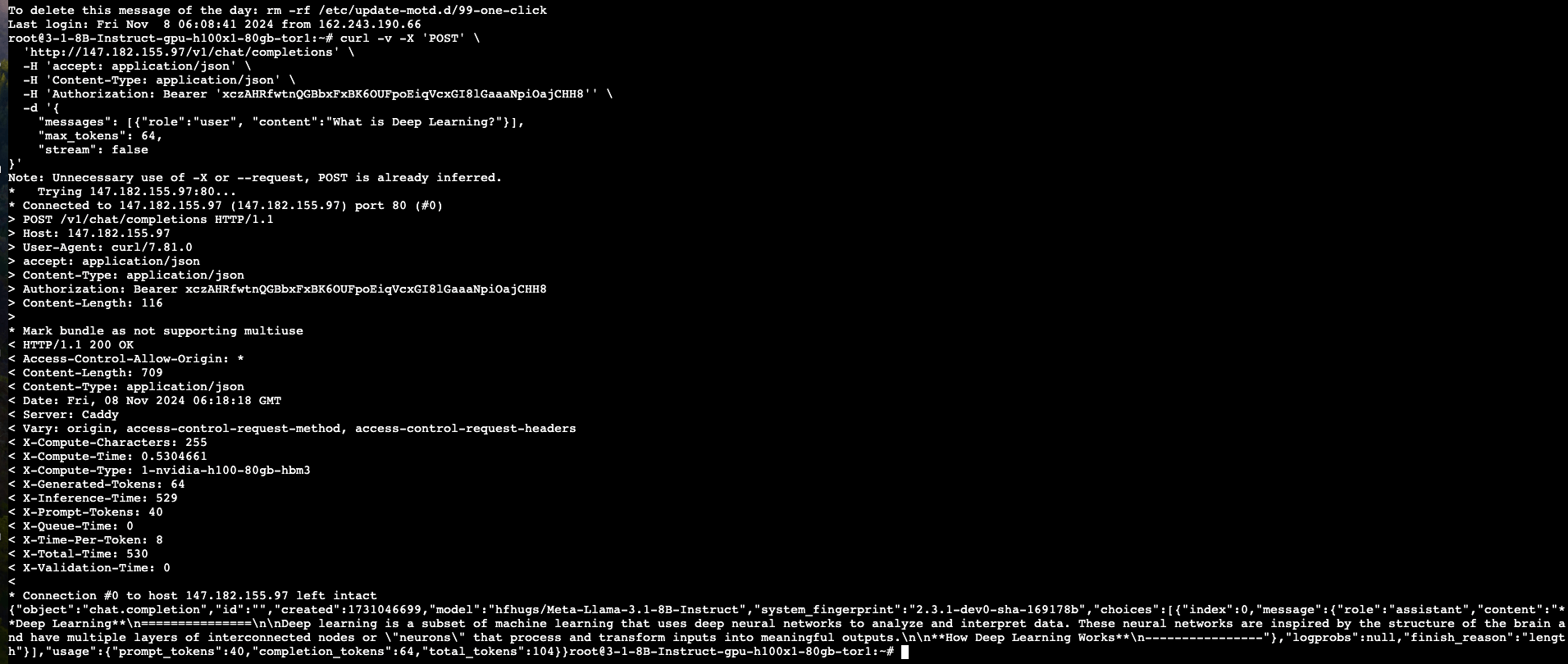
The AI model will now reply to our query and provide the answer.
Python
We also have the option to use the Hugging Face_hub.InferenceClient from the Hugging Face Hub Python SDK, the OpenAI Python SDK, or any other SDK that supports an OpenAI-compatible interface capable of consuming the Messages API.
Run the following snippet to replicate the functionality of the cURL command, allowing you to send requests to the Messages API.
import os
from Hugging Face_hub import InferenceClient
client = InferenceClient(base_url="http://localhost:8080", api_key=os.getenv("BEARER_TOKEN"))
chat_completion = client.chat.completions.create(
messages=[
{"role":"user","content":"What is Deep Learning?"},
],
temperature=0.7,
top_p=0.95,
max_tokens=128,
)
Getting Started with Language Models on Hugging Face
Hugging Face has become the go-to platform for working with state-of-the-art language models (LMs), offering an extensive repository of pre-trained models, tools, and frameworks. Hugging Face is an open-source platform designed for AI research and development. Their Transformers library is widely used for working with pre-trained models across tasks like text generation, classification, translation, summarization, and more.
Using Hugging Face Transformers, we can quickly integrate state-of-the-art models into any AI project with just a few lines of code.
Hugging Face Transformers Library
Hugging Face Transformers is a popular open-source library that provides tools for working with large language models.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, TextStreamer
from transformers import pipeline
import torch
base_model = "meta-llama/Llama-3.1-8B"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
The code above uses the Hugging Face Transformers library to load a pre-trained model and tokenizer for the “meta-llama/Llama-3.2-1B-Instruct” model from the Hugging Face model repository. First, the AutoTokenizer and AutoModelForCausalLM classes are imported from the Transformers library, which allows easy access to pre-trained models for various natural language processing (NLP) tasks.
The AutoTokenizer.from_pretrained(base_model) loads the tokenizer for the Llama 3.2 model, which converts text into tokens that the model can process. The AutoModelForCausalLM.from_pretrained() function loads the model itself, configured to use efficient memory settings (low_cpu_mem_usage=True) and optimized for faster inference (torch_dtype=torch.float16). Hugging Face’s Transformers library simplifies this process by providing pre-trained models and easy-to-use tools for deploying AI models in various environments.
Now, here we are using AutoModelForCausalLM.
Given a sequence of sentence, a Causal language model predicts the next word based on the preceding words. This model is designed to understand language by looking at the context of previous tokens (words or sub-words) and using that context to generate or predict the next token in the sequence.
Pipeline
Pipelines are high-level abstractions that simplify the process of using these pre-trained models for common tasks such as NLP, computer vision, and audio processing. A pipeline allows users to easily perform tasks like text generation, translation, summarization, image classification, etc. Pipeline manages the model and handles all the necessary steps, such as tokenizing the input and processing the output in human-readable form.
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
Now, we can pass a series of text in a pipeline and call it with a list.
pipe = pipeline("text-classification")
pipe(["This restaurant is awesome", "This restaurant is awful"])
[{‘label’: ‘POSITIVE’, ‘score’: 0.9998743534088135}, {‘label’: ‘NEGATIVE’, ‘score’: 0.9996669292449951}]
Tokenizer
Next, we will understand the tokenizer, a crucial component in natural language processing (NLP) models that convert raw text into a format the model can understand. Since most machine learning models, particularly language models, do not work directly with human-readable text, the tokenizer breaks the text into smaller units—called tokens—which can then be processed by the model.
# Specify the device (e.g., "cuda" for GPU or "cpu" for CPU)
device = "cuda" # change to "cpu" if you want to use a CPU
# Tokenize the text and move it to the specified device
text = "Hello, how are you?"
tokens = tokenizer(text, return_tensors=”pt”).to(device)
# Print the shape of the input_ids tensor
print(tokens[“input_ids”].shape)
torch.Size([1, 6])
tokens["input_ids"]
tensor([[15496, 616, 703, 389, 345]])
The model uses These token IDs to process the input text and generate predictions.
Llama 3.1 with Hugging Face
We will first install the necessary packages.
!pip install transformers
!pip install Hugging Facehub
!pip install torch
!pip install accelerate
Login to Hugging Face and generate the access token also, make sure to get access to the Llama 3.1 model.
import os
os.environ['HF_TOKEN']="hf_accesstoken"
os.environ['Hugging FaceHUB_API_TOKEN']="hf_apitoken"
Loading the model and Running Inference with Llama 3.1
import transformers
import torch
model_id = "meta-llama/Llama-3.1-8B"
pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
pipeline("Hey how are you doing today?")
What is new with Llama 3.1?
The Llama 3.1 405B model is trained on over 15 trillion tokens. Here’s a simple breakdown of its architecture and how it was built:
-
Model Type:
-
It uses a standard decoder-only Transformer architecture. This straightforward design focuses on stability, avoiding complex approaches like mixture-of-experts models.
-
Training Scale:
-
To train a model this large, Meta used over 16,000 NVIDIA H100 GPUs.
-
The training process was optimized to handle this huge scale efficiently, allowing the model to be trained faster.
-
Data Improvements: For Llama 3.1, the quantity and quality of training data were significantly improved compared to previous versions.
-
This included better data pre-processing, curation, and filtering, ensuring the model learns from the highest-quality data possible.
-
An iterative post-training procedure was used, involving multiple rounds of supervised fine-tuning and preference optimization to boost model performance.
-
Optimization for Inference:
-
The model was quantized from 16-bit (BF16) to 8-bit (FP8) numerics. This reduces the computational load, allowing the massive 405B model to run on a single server node. It makes large-scale deployment more efficient and cost-effective.
-
Scalability and Flexibility:
-
The design choices focused on making the model scalable and easy to work with, allowing improvements to be easily applied to smaller models in the Llama 3.1 lineup.
Llama 3.1 uses a stable and efficient Transformer architecture, optimized training techniques, and improved data quality to deliver state-of-the-art performance, especially in large-scale deployments. Multiple rounds of fine-tuning were performed on top of the pre-trained model to create the final chat models. This process included Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO). Furthermore, advanced filtering techniques ensured only the best data was used. For instance, Llama 3.1 handles short-context benchmarks well, even with a longer 128K context window. It also delivers helpful answers while integrating safety measures.
Concluding Thoughts
In this article, we learned how to start working with One-click models using GPU Droplet and get started with Llama 3.1. However, we encourage our readers to try out the other models available in the platform. Llama 3.1 is a significant step and is an improved model for any AI task. With models ranging up to 405B parameters and a 128K context window, Llama 3.1 excels in multilingual understanding, complex reasoning, and real-world applications. One of the key advantages is the open-source availability, which allows developers to utilize this technology for various use cases. DigitalOcean’s one-click model makes it incredibly easy to use Llama 3.1, enabling developers to build and innovate with large language models with minimal setup.
Resources
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
