By Meher Vamsi and Shaoni Mukherjee

Introduction
Have you ever tried generating images using AI?
If you have, you know the key to a good image is a good detailed prompt.
And I am bad at such detailed visual prompting, so I rely on large language models to generate the detailed prompt and then use that to generate great images.
Here are some examples of the prompts and images I was able to generate:
Prompt: Create a stunning aerial view of Bengaluru, India with the city name written in bold, golden font across the top of the image, with the city skyline and Nandi Hills visible in the background.

Prompt: Design an image of the iconic Vidhana Soudha building in Bengaluru, India, with the city name written in a modern, sans-serif font at the bottom of the image, in a sleek and minimalist style.

Prompt: Generate an image of a bustling street market in Bengaluru, India, with the city name written in a playful, cursive font above the scene, in a warm and inviting style.

In order to achieve these results we are using Flux.1-schnell model for image generation and Llamma 3.1 - 8B - Instruct model for Prompt generation. Both of them are hosted on 1 single H100 machine with the help of MIG(more on this later).
This blog is not another image generation tutorial. Our goal is to create a scalable, secure, and globally accessible (and affordable) AI architecture.
Imagine a business case where a global e-commerce platform requires rapid image customisation for users or a content platform delivering on-demand AI-generated text across continents.
Such a setup has many challenges for a developer. Example:
- GPUs are intimidating and expensive
- DigitalOcean AI Platform tools are bleeding edge and each tool has specific setup requirements
- Securely connecting backend servers with AI inference and agent services
- Routing globally distributed users to nearest server etc
This presentation should give you a starting point to solve each and every problem here.
Prerequisites
Before proceeding with adding the demo, make sure you have the following:
- A DigitalOcean Account.
- Basic knowledge of GPU, cloud networking, VPC, and load-balancing concepts.
- Basic familiarity with Bash, Docker, Python.
- Granted HuggingFace access to Image Generation with Flux.1 model
- Granted HuggingFace access to Llama 3.1-8b-Instruct model
- vLLM is a fast and easy-to-use library for LLM inference and serving.
High Level Design
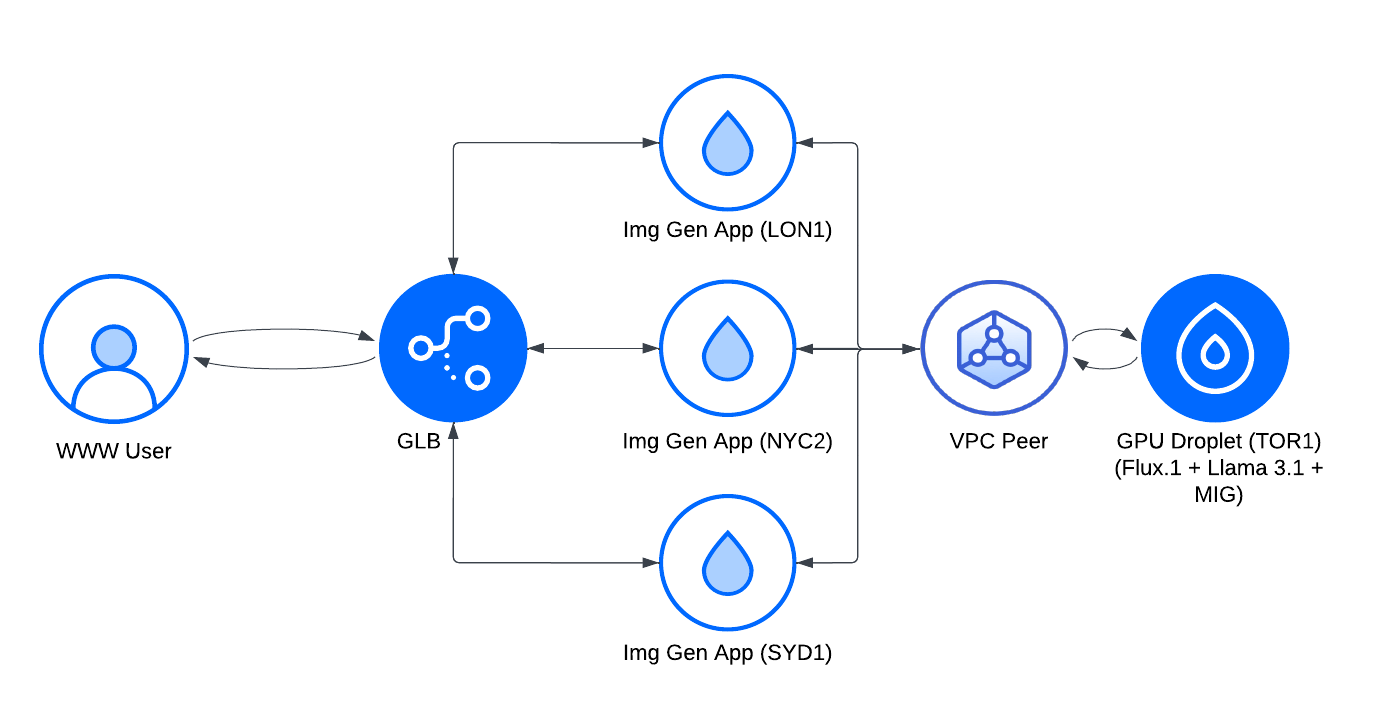
To make this possible, we designed a distributed architecture using DigitalOcean’s infrastructure. We start with a Global Load Balancer (GLB) to manage incoming requests, ensuring that users from any region experience minimal latency.
Next, we have lightweight image generation apps deployed in key regions—London, New York, and Sydney—each with its on cache and ready to connect with our GPU resources as needed. Finally, all these components securely communicate over VPC Peering, channeling complex tasks back to our powerhouse H100 GPU in Toronto, where the prompt and image generation magic happens.
Components
Lightweight Image Generation App
The Image Generation app is a simple Python Flask application with three main components:
-
Detect Location Section: This component makes a dummy request from the browser to the server to determine the user’s location (City and Country) and identify which server region is handling the request. This information is displayed to the user and helps optimize prompt and image generation, as we’ll explain in more detail later.
-
Prompts Dropdown Section: After determining the user’s location, the app first checks a cache for pre-existing prompts associated with that location. If suitable prompts are found in the cache, they are immediately displayed in a dropdown menu, allowing the user to choose a prompt for image generation. If no cached prompts are available, the app sends a request to the LLM (Large Language Model) to generate new prompts, which are then cached for future use and populated in the dropdown for the user to select.
-
Generated Image Section: When the user selects a prompt, the app first checks if an image generated from that specific prompt is already cached on disk. If a cached image exists, it is loaded directly from disk, ensuring a faster response time. If no cached image is available, the app makes an API call to generate a new image, which is then cached for future requests and displayed to the user.
MIG GPU Component
The MIG (Multi-Instance GPU) is a feature of NVIDIA GPUs, such as the H100, that allows a single physical GPU to be partitioned into multiple independent instances. Each instance, called a MIG slice, operates as a fully isolated GPU with its own compute, memory, and bandwidth resources.
This approach not only optimizes GPU utilization but also enables us to deploy both the image generation and prompt generation models side by side.
Step-by-Step Setup
Spin Up the GPU Droplet: Begin by creating a GPU Droplet on DigitalOcean with a single H100 GPU with the pre built OS image for ML development
Enable MIG on the H100 GPU: Once the GPU Droplet is up and running, enable MIG (Multi-Instance GPU) mode on the H100. MIG allows the GPU to be split into multiple, smaller GPU instances, each isolated from the others. This isolation is crucial for running different models in parallel without interference.
sudo nvidia-smi -i 0 -mig 1
Choose the MIG Profile and Create Instances: With MIG enabled, select a profile that suits the requirements of each model you plan to run.
nvidia-smi mig -lgip # will list all the profiles
For example
sudo nvidia-smi mig -cgi 9,9 -C
This command creates 2 MIG instances with a profile providing 40GB of memory, which should be sufficient for both models. The below code will list all MIG instance IDs
nvidia-smi -L
Set Up Docker Containers on Each MIG Instance: For each MIG instance, run a separate Docker container with the respective model.
This setup involves downloading and running two Docker containers for the models: one for image generation (Flux.1-schnell) and one for prompt generation (Llama 3.1 via vLLM).
Deploy Flux.1-schnell for Image Generation: We used the metatonic images and code for deploying a Docker image of Flux.1
# Clone the repo
git clone https://github.com/matatonic/openedai-images-flux
cd openedai-images-flux
# Copy Config file
cp config.default.json config/config.json
# Run the docker image
sudo docker run -d \
-e HUGGING_FACE_HUB_TOKEN="<HF_READ_TOKEN>" \
--runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=<MIG_INSANCE_ID> \
-v ./config:/app/config \
-v ./models:/app/models \
-v ./lora:/app/lora \
-v ./models/hf_home:/root/.cache/huggingface \
-p 5005:5005 \
ghcr.io/matatonic/openedai-images-flux
Deploy Llama 3.1 using vLLM for Prompt Generation: Download and run the Docker container for the prompt generation model using vLLM.
sudo docker run -d --runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=<MIG_INSANCE_ID> \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-e HUGGING_FACE_HUB_TOKEN="<HF_READ_TOKEN>" \
-p 8000:8000 \
--ipc=host \
vllm/vllm-openai:latest \
--model meta-llama/Meta-Llama-3.1-8B-Instruct
Model Access and Communication:
- Each container is accessible through designated ports, allowing the image generation app instances to connect and send requests to either the image model (Flux.1-schnell) or the prompt model (Llama 3.1) as needed.
- The MIG partitioning ensures that both models operate efficiently and concurrently, utilizing the GPU’s resources without interfering with each other.
Regional App Instances
We set up the Lightweight apps in regional locations (London, New York, Sydney) to handle user requests locally, caching frequently accessed prompts and images for faster responses.
- Create Droplets in one region first through the Droplets section of the DO dashboard.
- SSH in and set up the code. For the sake of speed, i have already created a container so all we need is to ensure we have the DO Container registry access and pull the image
# Login to docker registry
sudo docker login registry.digitalocean.com
# Pull the container
sudo docker pull registry.digitalocean.com/<cr_name>/city-image-generator:v2
- At this point, id take a snapshot of the droplet and make it accessible to the other regions i plan to deploy the app
- Come back to the droplet and run the container
# Run the Container
sudo docker run -d -p 80:80 registry.digitalocean.com/<cr_name>/city-image-generator:v2
- Now create other droplets in other regions using the snapshot and run the container.
VPC Peering
VPC Peering ensures secure, low-latency communication between the regional app instances and the GPU server in Toronto over a private network.
- Navigate to the Networking section in the DigitalOcean dashboard.
- You should see the
default vpcfor each region (e.g., London, New York, Sydney, and Toronto). - Use the VPC Peering feature to establish connections between the Toronto VPC and each regional VPC.
- Verify connectivity using simple network tools like
pingorcurlfrom the regional app servers to the GPU server.
Global Load Balancer (GLB)
The GLB distributes incoming user requests to the closest regional app instance, optimizing latency and improving user experience.
- In the Load Balancers section of the Networking part of the dashboard, create a new Global Load Balancer.
- Add your regional app instances as backend targets.
- Configure health checks, timeouts and other Advanced Settings.
- Create Load Balancer
With all components in place, your architecture is fully operational, enabling scalable and secure AI services. The DigitalOcean GUI simplifies much of the setup, allowing you to focus on optimizing the performance and functionality of your AI models.
Conclusion
This demo is a practical starting point for businesses/developers exploring distributed AI solutions, such as e-commerce platforms generating personalized content or AI-driven content platforms serving global audiences. By leveraging DigitalOcean’s products, this setup demonstrates how to balance scalability, security, and cost efficiency in deploying cutting-edge AI services.
References
You can read more about the technologies used in this demo here:
- Nvidia Multi Instance GPUs MIG
- When to use MIG?
- Flux.1 Models
- Llama 3.1 Models
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
