By Carlos Mucuho and Matt Abrams

The author selected the Free and Open Source Fund to receive a donation as part of the Write for DOnations program.
Introduction
Web scraping, also known as web crawling, uses bots to extract, parse, and download content and data from websites.
You can scrape data from a few dozen web pages using a single machine, but if you have to retrieve data from hundreds or even thousands of web pages, you might want to consider distributing the workload.
In this tutorial you will use Puppeteer to scrape books.toscrape, a fictional bookstore that functions as a safe place for beginners to learn web scraping and for developers to validate their scraping technologies. At the time of writing this, there are 1000 books on books.toscrape and therefore 1000 web pages that you could scrape. However, in this tutorial, you will only scrape the first 400. To scrape all these web pages in a short amount of time, you will build and deploy a scalable app containing the Express web framework and the Puppeteer browser controller to a Kubernetes cluster. To interact with your scraper, you will then build an app containing axios, a promise-based HTTP client, and lowdb, a small JSON database for Node.js.
When you complete this tutorial, you will have a scalable scraper capable of simultaneously extracting data from multiple pages. With the default settings and a three-node cluster, for instance, it will take less than 2 minutes to scrape 400 pages on books.toscrape. After scaling your cluster, it will take about 30 seconds.
Warning: The ethics and legality of web scraping are very complex and continually evolving. They also differ based on your location, the data’s location, and the website in question. This tutorial scrapes a special website, books.toscrape.com, explicitly designed to test scraper applications. Scraping any other domain falls outside the scope of this tutorial.
Prerequisites
To follow this tutorial, you will need a machine with:
- Docker installed. Follow our tutorial on how to install and use Docker for instructions. Docker’s website provides installation instructions for other operating systems like macOS and Windows.
- An account at Docker Hub for storing your Docker image.
- A Kubernetes 1.17+ cluster with your connection configuration set as the
kubectldefault. To create a Kubernetes cluster on DigitalOcean, read our Kubernetes Quickstart. To connect to the cluster, read How to Connect to a DigitalOcean Kubernetes Cluster. kubectlinstalled. Follow this tutorial on getting started with Kubernetes: A kubectl Cheat Sheet to install it.- Node.js installed on your development machine. This tutorial was tested on Node.js version 12.18.3 and npm version 6.14.6. Follow this guide to install Node.js on macOS, or follow this guide to install Node.js on various Linux distributions.
- If you are using DigitalOcean Kubernetes, then you will also need a Personal Access Token. To create one, you can follow our guide on how to create a Personal Access Token. Save this token in a safe place; it provides full access to your account.
Step 1 — Analyzing the Target Website
Before writing any code, navigate to books.toscrape in a web browser. Examine how data is structured and why concurrent scraping is an optimal solution.
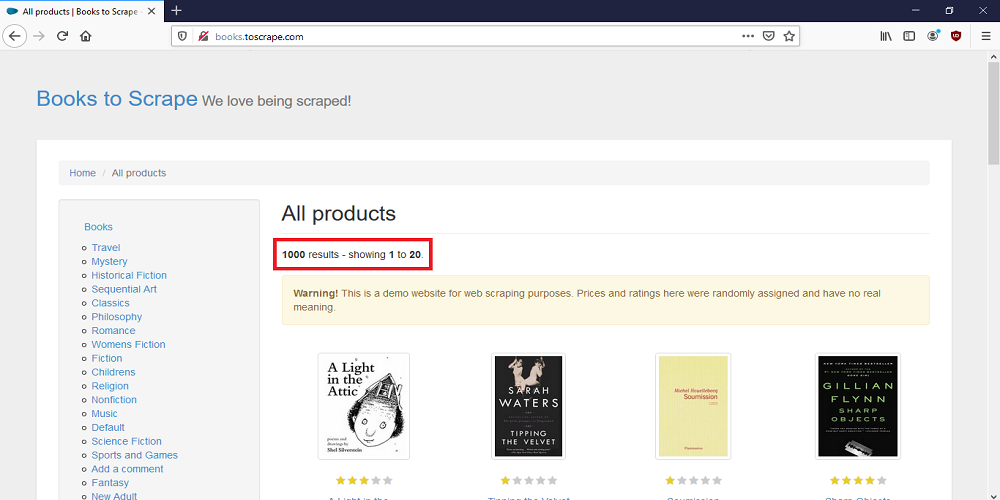
Note that there are 1,000 books on this website, but each page only displays 20 books.
Scroll to the bottom of the page.

The content on this website is paginated, and there are 50 total pages. Because each page shows 20 books and you only want to scrape the first 400 books, you will only retrieve the title, price, rating, and URL for every book displayed on the first 20 pages.
The whole process should take less than 1 minute.
Open your browser’s dev tools and inspect the first book on the page. You will see the following content:

Every book is inside the <section> tag, and each book is listed under its own <li> tag. Inside each <li> tag there is an <article> tag with a class attribute equal to product_pod. This is the element that we want to scrape.
After getting the metadata for every book on the first 20 pages and storing it, you will have a local database containing 400 books. However, since more detailed information about the book exists on its own page, you will need to navigate 400 additional pages using the URL inside each book’s metadata. You will then retrieve the missing book details that you want and add this data to your local database. The missing data that you are going to retrieve are the description, the UPC (Universal Book Code), the number of reviews, and the book’s availability. Going through 400 pages using a single machine can take more than 7 minutes, and this is why you will need Kubernetes to divide the work across multiple machines.
Now click in the link for the first book on the homepage, which will open that book’s details page. Open your browser’s dev tools again and inspect the page.

The missing information that you want to extract is, again, inside an <article> tag with a class attribute equal to product_page.
To interact with our scraper in the cluster, you will need to create a client application capable of sending HTTP requests to our Kubernetes cluster. You will first code the server side and then the client side of this project.
In this section, you have reviewed what information your scraper will retrieve and why you need to deploy this scraper to a Kubernetes cluster. In the next section, you will create the directories for the client and server applications.
Step 2 — Creating the Project Root Directory
In this step, you will create your project’s directory structure. Then you will initialize a Node.js project for your client and server applications.
Open a terminal window and create a new directory called concurrent-webscraper:
- mkdir concurrent-webscraper
Navigate into the directory:
- cd ./concurrent-webscraper
Now create three subdirectories named server, client, and k8s:
- mkdir server client k8s
Navigate into the server directory:
- cd ./server
Create a new Node.js project. Running npm’s init command will create a package.json file, which will help you manage your dependencies and metadata.
Run the initialization command:
- npm init
To accept the default values, press ENTER to all the prompts; alternately, you can personalize your responses. You can read more about npm’s initialization settings in Step One of our tutorial, How To Use Node.js Modules with npm and package.json.
Open the package.json file and edit it:
- nano package.json
You need to modify the main property, add some information to the scripts directive, and then create a dependencies directive.
Replace the contents inside the file with the highlighted code:
{
"name": "server",
"version": "1.0.0",
"description": "",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"body-parser": "^1.19.0",
"express": "^4.17.1",
"puppeteer": "^3.0.0"
}
}
Here you changed the main and scripts properties, and you also edited the dependencies property. Because the server application will run inside a Docker container, you do not need to run the npm install command, which usually follows initialization and automatically adds each dependency to package.json.
Save and close the file.
Navigate to your client directory:
- cd ../client
Create another Node.js project:
- npm init
Follow the same procedure to accept the default settings or customize your responses.
Open the package.json file and edit it:
- nano package.json
Replace the contents inside the file with the highlighted code:
{
"name": "client",
"version": "1.0.0",
"description": "",
"main": "main.js",
"scripts": {
"start": "node main.js"
},
"author": "",
"license": "ISC"
}
Here you changed the main and scripts properties.
This time, use npm to install the necessary dependencies:
- npm install axios lowdb --save
In this block of code, you have installed axios and lowdb. axios is a promise based HTTP client for the browser and Node.js. You will use this module to send asynchronous HTTP requests to REST endpoints in our scraper to interact with it; lowdb is a small JSON database for Node.js and the browser, which you will use to store your scraped data.
In this step, you created a project directory and initialized a Node.js project for your application server that will contain the scraper; you then did the same for your client application that will interact with the application server. You also created a directory for your Kubernetes configuration files. In the next step, you will start building the application server.
Step 3 — Building the First Scraper File
In this step and Step 4, you are going to create the scraper on the server side. This application will consist of two files: puppeteerManager.js and server.js. The puppeteerManager.js file will create and manage browser sessions, and the server.js file will receive requests to scrape one or multiple web pages. In turn, these requests will call a method inside puppeteerManager.js that will scrape a given web page and return the scraped data. In this step, you will create the puppeteerManager.js file. In Step 4, you will create the server.js file.
First, return to the server directory and create a file called puppeteerManager.js.
Navigate to the server folder:
- cd ../server
Create and open the puppeteerManager.js file using your preferred text editor:
- nano puppeteerManager.js
Your puppeteerManager.js file will contain a class called PuppeteerManager, and this class will create and manage a Puppeteer browser instance. You will first create this class and then add a constructor to it.
Add the following code to your puppeteerManager.js file:
class PuppeteerManager {
constructor(args) {
this.url = args.url
this.existingCommands = args.commands
this.nrOfPages = args.nrOfPages
this.allBooks = [];
this.booksDetails = {}
}
}
module.exports = { PuppeteerManager }
In this first block of code, you have created the PuppeteerManager class and added a constructor to it.
The constructor expects to receive an object containing the following properties:
url: This property will hold a string, which will be the address of the page that you want to scrape.commands: This property will hold an array, which provides instructions for the browser. For example, it will direct the browser to click a button or parse a specificDOMelement. Eachcommandhas the following properties:description,locatorCss, andtype.descriptiontells you what thecommanddoes,locatorCssfinds the appropriate element in theDOM, andtypechooses the specific action.nrOfPages: This property will hold an integer, which your application will use to determine how many timescommandsshould repeat. books.toscrape.com, for instance, only shows 20 books per page, so to get all 400 books on all 20 pages, you will use this property to repeat the existingcommands20 times.
In this code block, you also assigned the received object properties to the constructor variables url, existingCommands, and nrOfPages. You then created two additional variables: allBooks and booksDetails. You will use the variable allBooks to store the metadata for all retrieved books and the variable booksDetails to store the missing book details for a given, individual book.
You are now ready to add a few methods to the PuppeteerManager class. This class will have the following methods: runPuppeteer(), executeCommand(), sleep(), getAllBooks(), and getBooksDetails(). Because these methods form the core of your scraper application, it is worth examining them one by one.
Coding the runPuppeteer() Method
The first method inside the PuppeteerManager class is runPuppeteer(). This will require the Puppeteer module and launch your browser instance.
At the bottom of the PuppeteerManager class, add the following code:
. . .
async runPuppeteer() {
const puppeteer = require('puppeteer')
let commands = []
if (this.nrOfPages > 1) {
for (let i = 0; i < this.nrOfPages; i++) {
if (i < this.nrOfPages - 1) {
commands.push(...this.existingCommands)
} else {
commands.push(this.existingCommands[0])
}
}
} else {
commands = this.existingCommands
}
console.log('commands length', commands.length)
}
In this block of code, you created the runPuppeteer() method. First, you required the puppeteer module and then created a variable that starts with an empty array called commands. Using conditional logic, you stated that if the number of pages to scrape is greater than one, the code should loop through the nrOfPages, and add the existingCommands for each page to the commands array. However, when it reaches the last page, it doesn’t add the very last command in the existingCommands array to the commands array because the last command clicks the next page button.
The next step is to create a browser instance.
At the bottom of the runPuppeteer() method that you just created, add the following code:
. . .
async runPuppeteer() {
. . .
const browser = await puppeteer.launch({
headless: true,
args: [
"--no-sandbox",
"--disable-gpu",
]
});
let page = await browser.newPage()
. . .
}
In this block of code, you created a browser instance using the built-in puppeteer.launch() method. You are designating that the instance run in headless mode. This is the default option and necessary for this project because you are running the application on Kubernetes. The next two arguments are standard when creating a browser without a graphical user interface. Lastly, you created a new page object using Puppeteer’s browser.newPage() method. The .launch() method returns a Promise, which requires the await keyword.
You are now ready to add some behavior to your new page object, including how it will navigate a URL.
At the bottom of the runPuppeteer() method, add the following code:
. . .
async runPuppeteer() {
. . .
await page.setRequestInterception(true);
page.on('request', (request) => {
if (['image'].indexOf(request.resourceType()) !== -1) {
request.abort();
} else {
request.continue();
}
});
await page.on('console', msg => {
for (let i = 0; i < msg._args.length; ++i) {
msg._args[i].jsonValue().then(result => {
console.log(result);
})
}
});
await page.goto(this.url);
. . .
}
In this block of code, the page object intercepts all requests using Puppeteer’s page.setRequestInterception() method, and if the request is to load an image, it prevents the image from loading, thus decreasing the time needed to load a web page. Then the page object intercepts any attempt to display a message in the browser context using Puppeteer’s page.on('console') event. The page then navigates to a given url using the page.goto() method.
Now add some more behaviors to your page object that will control how it finds elements in the DOM and runs commands on them.
At the bottom of the runPuppeteer() method add the following code:
. . .
async runPuppeteer() {
. . .
let timeout = 6000
let commandIndex = 0
while (commandIndex < commands.length) {
try {
console.log(`command ${(commandIndex + 1)}/${commands.length}`)
let frames = page.frames()
await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
await this.executeCommand(frames[0], commands[commandIndex])
await this.sleep(1000)
} catch (error) {
console.log(error)
break
}
commandIndex++
}
console.log('done')
await browser.close()
}
In this block of code, you created two variables, timeout and commandIndex. The first variable will limit the amount of time that the code will wait for an element on a web page, and the second variable controls how you will loop through the commands array.
Inside the while loop, the code goes through every command in the commands array. First, you are creating an array of all frames attached to the page using the page.frames() method. It searches for a DOM element in a frame object of a page using the frame.waitForSelector() method and the locatorCss property. If an element is found, it calls the executeCommand() method and passes the frame and the command object as parameters. After the executeCommand returns, it calls the sleep() method, which makes the code wait 1 second before executing the next command. Finally, when there are no more commands, the browser instance closes.
This completes your runPuppeteer() method. At this point, your puppeteerManager.js file should look like this:
class PuppeteerManager {
constructor(args) {
this.url = args.url
this.existingCommands = args.commands
this.nrOfPages = args.nrOfPages
this.allBooks = [];
this.booksDetails = {}
}
async runPuppeteer() {
const puppeteer = require('puppeteer')
let commands = []
if (this.nrOfPages > 1) {
for (let i = 0; i < this.nrOfPages; i++) {
if (i < this.nrOfPages - 1) {
commands.push(...this.existingCommands)
} else {
commands.push(this.existingCommands[0])
}
}
} else {
commands = this.existingCommands
}
console.log('commands length', commands.length)
const browser = await puppeteer.launch({
headless: true,
args: [
"--no-sandbox",
"--disable-gpu",
]
});
let page = await browser.newPage()
await page.setRequestInterception(true);
page.on('request', (request) => {
if (['image'].indexOf(request.resourceType()) !== -1) {
request.abort();
} else {
request.continue();
}
});
await page.on('console', msg => {
for (let i = 0; i < msg._args.length; ++i) {
msg._args[i].jsonValue().then(result => {
console.log(result);
})
}
});
await page.goto(this.url);
let timeout = 6000
let commandIndex = 0
while (commandIndex < commands.length) {
try {
console.log(`command ${(commandIndex + 1)}/${commands.length}`)
let frames = page.frames()
await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
await this.executeCommand(frames[0], commands[commandIndex])
await this.sleep(1000)
} catch (error) {
console.log(error)
break
}
commandIndex++
}
console.log('done')
await browser.close();
}
}
Now you are ready to code the second method for puppeteerManager.js: executeCommand().
Coding the executeCommand() Method
After creating the runPuppeteer() method, it is now time to create the executeCommand() method. This method is responsible for deciding what actions Puppeteer should perform, like clicking a button or parsing one or multiple DOM elements.
At the bottom of the PuppeteerManager class add the following code:
. . .
async executeCommand(frame, command) {
await console.log(command.type, command.locatorCss)
switch (command.type) {
case "click":
break;
case "getItems":
break;
case "getItemDetails":
break;
}
}
In this code block, you created the executeCommand() method. This method expects two arguments, a frame object that will contain page elements and a command object that will contain commands. This method consists of a switch statement with the following cases: click, getItems, and getItemDetails.
Define the click case.
Replace break; underneath case "click": with the following code:
async executeCommand(frame, command) {
. . .
case "click":
try {
await frame.$eval(command.locatorCss, element => element.click());
return true
} catch (error) {
console.log("error", error)
return false
}
. . .
}
Your code will trigger the click case when command.type equals click. This block of code is responsible for clicking the next button to move through the paginated list of books.
Now program the next case statement.
Replace break; underneath case "getItems": with the following code:
async executeCommand(frame, command) {
. . .
case "getItems":
try {
let books = await frame.evaluate((command) => {
function wordToNumber(word) {
let number = 0
let words = ["zero","one","two","three","four","five"]
for(let n=0;n<words.length;words++){
if(word == words[n]){
number = n
break
}
}
return number
}
try {
let parsedItems = [];
let items = document.querySelectorAll(command.locatorCss);
items.forEach((item) => {
let link = 'http://books.toscrape.com/catalogue/' + item.querySelector('div.image_container a').getAttribute('href').replace('catalogue/', '')<^>
let starRating = item.querySelector('p.star-rating').getAttribute('class').replace('star-rating ', '').toLowerCase().trim()
let title = item.querySelector('h3 a').getAttribute('title')
let price = item.querySelector('p.price_color').innerText.replace('£', '').trim()
let book = {
title: title,
price: parseInt(price),
rating: wordToNumber(starRating),
url: link
}
parsedItems.push(book)
})
return parsedItems;
} catch (error) {
console.log(error)
}
}, command).then(result => {
this.allBooks.push.apply(this.allBooks, result)
console.log('allBooks length ', this.allBooks.length)
})
return true
} catch (error) {
console.log("error", error)
return false
}
. . .
}
The getItems case will trigger when command.type is equal to getItems. You are using the frame.evaluate() method to switch the browser context and then create a function called wordToNumber(). This function will convert the starRating of a book from a string to an integer. The code will then use the document.querySelectorAll() method to parse and match the DOM and retrieve the metadata of the books displayed in the given frame of a web page. Once the metadata is retrieved, the code will add it to the allBooks array.
Now you can define the final case statement.
Replace break; underneath case "getItemDetails" with the following code:
async executeCommand(frame, command) {
. . .
case "getItemDetails":
try {
this.booksDetails = JSON.parse(JSON.stringify(await frame.evaluate((command) => {
try {
let item = document.querySelector(command.locatorCss);
let description = item.querySelector('.product_page > p:nth-child(3)').innerText.trim()
let upc = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(1) > td:nth-child(2)')
.innerText.trim()
let nrOfReviews = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(7) > td:nth-child(2)')
.innerText.trim()
let availability = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(6) > td:nth-child(2)')
.innerText.replace('In stock (', '').replace(' available)', '')
let details = {
description: description,
upc: upc,
nrOfReviews: parseInt(nrOfReviews),
availability: parseInt(availability)
}
return details;
} catch (error) {
console.log(error)
return error
}
}, command)))
console.log(this.booksDetails)
return true
} catch (error) {
console.log("error", error)
return false
}
}
The getItemDetails case will trigger when command.type is equal to getItemDetails. You used the frame.evaluate() and .querySelector() methods again to switch the browser context and to parse the DOM. But this time, you retrieved the missing details for each book in a given frame of a web page. You then assigned these missing details to the booksDetails object.
This completes your executeCommand() method. Your puppeteerManager.js file will now look like this:
class PuppeteerManager {
constructor(args) {
this.url = args.url
this.existingCommands = args.commands
this.nrOfPages = args.nrOfPages
this.allBooks = [];
this.booksDetails = {}
}
async runPuppeteer() {
const puppeteer = require('puppeteer')
let commands = []
if (this.nrOfPages > 1) {
for (let i = 0; i < this.nrOfPages; i++) {
if (i < this.nrOfPages - 1) {
commands.push(...this.existingCommands)
} else {
commands.push(this.existingCommands[0])
}
}
} else {
commands = this.existingCommands
}
console.log('commands length', commands.length)
const browser = await puppeteer.launch({
headless: true,
args: [
"--no-sandbox",
"--disable-gpu",
]
});
let page = await browser.newPage()
await page.setRequestInterception(true);
page.on('request', (request) => {
if (['image'].indexOf(request.resourceType()) !== -1) {
request.abort();
} else {
request.continue();
}
});
await page.on('console', msg => {
for (let i = 0; i < msg._args.length; ++i) {
msg._args[i].jsonValue().then(result => {
console.log(result);
})
}
});
await page.goto(this.url);
let timeout = 6000
let commandIndex = 0
while (commandIndex < commands.length) {
try {
console.log(`command ${(commandIndex + 1)}/${commands.length}`)
let frames = page.frames()
await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
await this.executeCommand(frames[0], commands[commandIndex])
await this.sleep(1000)
} catch (error) {
console.log(error)
break
}
commandIndex++
}
console.log('done')
await browser.close();
}
async executeCommand(frame, command) {
await console.log(command.type, command.locatorCss)
switch (command.type) {
case "click":
try {
await frame.$eval(command.locatorCss, element => element.click());
return true
} catch (error) {
console.log("error", error)
return false
}
case "getItems":
try {
let books = await frame.evaluate((command) => {
function wordToNumber(word) {
let number = 0
let words = ["zero","one","two","three","four","five"]
for(let n=0;n<words.length;words++){
if(word == words[n]){
number = n
break
}
}
return number
}
try {
let parsedItems = [];
let items = document.querySelectorAll(command.locatorCss);
items.forEach((item) => {
let link = 'http://books.toscrape.com/catalogue/' + item.querySelector('div.image_container a').getAttribute('href').replace('catalogue/', '')
let starRating = item.querySelector('p.star-rating').getAttribute('class').replace('star-rating ', '').toLowerCase().trim()
let title = item.querySelector('h3 a').getAttribute('title')
let price = item.querySelector('p.price_color').innerText.replace('£', '').trim()
let book = {
title: title,
price: parseInt(price),
rating: wordToNumber(starRating),
url: link
}
parsedItems.push(book)
})
return parsedItems;
} catch (error) {
console.log(error)
}
}, command).then(result => {
this.allBooks.push.apply(this.allBooks, result)
console.log('allBooks length ', this.allBooks.length)
})
return true
} catch (error) {
console.log("error", error)
return false
}
case "getItemDetails":
try {
this.booksDetails = JSON.parse(JSON.stringify(await frame.evaluate((command) => {
try {
let item = document.querySelector(command.locatorCss);
let description = item.querySelector('.product_page > p:nth-child(3)').innerText.trim()
let upc = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(1) > td:nth-child(2)')
.innerText.trim()
let nrOfReviews = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(7) > td:nth-child(2)')
.innerText.trim()
let availability = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(6) > td:nth-child(2)')
.innerText.replace('In stock (', '').replace(' available)', '')
let details = {
description: description,
upc: upc,
nrOfReviews: parseInt(nrOfReviews),
availability: parseInt(availability)
}
return details;
} catch (error) {
console.log(error)
return error
}
}, command)))
console.log(this.booksDetails)
return true
} catch (error) {
console.log("error", error)
return false
}
}
}
}
You are now ready to create the third method for your PuppeteerManager class: sleep().
Coding the sleep() Method
With the executeCommand() method created, your next step is to create the sleep() method. This method will make your code wait a specific amount of time before executing the next line of code. This is essential for reducing the crawl rate. Without this precaution, the scraper could, for example, click a button on page A and then search for an element on page B before page B even loads.
At the bottom of the PuppeteerManager class add the following code:
. . .
sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms))
}
You are passing an integer to the sleep() method. This integer is the amount of time in milliseconds that the code should wait.
Now code the final two methods inside the PuppeteerManager class: getAllBooks() and getBooksDetails().
Coding the getAllBooks() and getBooksDetails() Methods
After creating the sleep() method, create the getAllBooks() method. A function inside the server.js file will call this function. getAllBooks() is responsible for calling runPuppeteer(), getting the books displayed on a number of given pages, and then returning the retrieved books to the function that called it in the server.js file.
At the bottom of the PuppeteerManager class add the following code:
. . .
async getAllBooks() {
await this.runPuppeteer()
return this.allBooks
}
Note how this block uses another Promise.
Now you can create the final method: getBooksDetails(). Like getAllBooks(), a function inside server.js will call this function. getBooksDetails() however, is responsible for retrieving the missing details for each book. It will also return these details to the function that called it in the server.js file.
At the bottom of the PuppeteerManager class add the following code:
. . .
async getBooksDetails() {
await this.runPuppeteer()
return this.booksDetails
}
You have now finished coding your puppeteerManager.js file.
After adding the five methods described in this section, your completed file will look like this:
class PuppeteerManager {
constructor(args) {
this.url = args.url
this.existingCommands = args.commands
this.nrOfPages = args.nrOfPages
this.allBooks = [];
this.booksDetails = {}
}
async runPuppeteer() {
const puppeteer = require('puppeteer')
let commands = []
if (this.nrOfPages > 1) {
for (let i = 0; i < this.nrOfPages; i++) {
if (i < this.nrOfPages - 1) {
commands.push(...this.existingCommands)
} else {
commands.push(this.existingCommands[0])
}
}
} else {
commands = this.existingCommands
}
console.log('commands length', commands.length)
const browser = await puppeteer.launch({
headless: true,
args: [
"--no-sandbox",
"--disable-gpu",
]
});
let page = await browser.newPage()
await page.setRequestInterception(true);
page.on('request', (request) => {
if (['image'].indexOf(request.resourceType()) !== -1) {
request.abort();
} else {
request.continue();
}
});
await page.on('console', msg => {
for (let i = 0; i < msg._args.length; ++i) {
msg._args[i].jsonValue().then(result => {
console.log(result);
})
}
});
await page.goto(this.url);
let timeout = 6000
let commandIndex = 0
while (commandIndex < commands.length) {
try {
console.log(`command ${(commandIndex + 1)}/${commands.length}`)
let frames = page.frames()
await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
await this.executeCommand(frames[0], commands[commandIndex])
await this.sleep(1000)
} catch (error) {
console.log(error)
break
}
commandIndex++
}
console.log('done')
await browser.close();
}
async executeCommand(frame, command) {
await console.log(command.type, command.locatorCss)
switch (command.type) {
case "click":
try {
await frame.$eval(command.locatorCss, element => element.click());
return true
} catch (error) {
console.log("error", error)
return false
}
case "getItems":
try {
let books = await frame.evaluate((command) => {
function wordToNumber(word) {
let number = 0
let words = ["zero","one","two","three","four","five"]
for(let n=0;n<words.length;words++){
if(word == words[n]){
number = n
break
}
}
return number
}
try {
let parsedItems = [];
let items = document.querySelectorAll(command.locatorCss);
items.forEach((item) => {
let link = 'http://books.toscrape.com/catalogue/' + item.querySelector('div.image_container a').getAttribute('href').replace('catalogue/', '')
let starRating = item.querySelector('p.star-rating').getAttribute('class').replace('star-rating ', '').toLowerCase().trim()
let title = item.querySelector('h3 a').getAttribute('title')
let price = item.querySelector('p.price_color').innerText.replace('£', '').trim()
let book = {
title: title,
price: parseInt(price),
rating: wordToNumber(starRating),
url: link
}
parsedItems.push(book)
})
return parsedItems;
} catch (error) {
console.log(error)
}
}, command).then(result => {
this.allBooks.push.apply(this.allBooks, result)
console.log('allBooks length ', this.allBooks.length)
})
return true
} catch (error) {
console.log("error", error)
return false
}
case "getItemDetails":
try {
this.booksDetails = JSON.parse(JSON.stringify(await frame.evaluate((command) => {
try {
let item = document.querySelector(command.locatorCss);
let description = item.querySelector('.product_page > p:nth-child(3)').innerText.trim()
let upc = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(1) > td:nth-child(2)')
.innerText.trim()
let nrOfReviews = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(7) > td:nth-child(2)')
.innerText.trim()
let availability = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(6) > td:nth-child(2)')
.innerText.replace('In stock (', '').replace(' available)', '')
let details = {
description: description,
upc: upc,
nrOfReviews: parseInt(nrOfReviews),
availability: parseInt(availability)
}
return details;
} catch (error) {
console.log(error)
return error
}
}, command)))
console.log(this.booksDetails)
return true
} catch (error) {
console.log("error", error)
return false
}
}
}
sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms))
}
async getAllBooks() {
await this.runPuppeteer()
return this.allBooks
}
async getBooksDetails() {
await this.runPuppeteer()
return this.booksDetails
}
}
module.exports = { PuppeteerManager }
In this step you used the module Puppeteer to create the puppeteerManager.js file. This file forms the core of your scraper. In the next section you will create the server.js file.
Step 4 — Building the Second Scraper File
In this step, you will create the server.js file — the second half of your application server. This file will receive requests containing the information that will direct what data to scrape, and then return that data to the client.
Create the server.js file and open it:
- nano server.js
Add the following code:
const express = require('express');
const bodyParser = require('body-parser')
const os = require('os');
const PORT = 5000;
const app = express();
let timeout = 1500000
app.use(bodyParser.urlencoded({ extended: true }))
app.use(bodyParser.json())
let browsers = 0
let maxNumberOfBrowsers = 5
In this code block, you required the modules express and body-parser. These modules are necessary to create an application server capable of handling HTTP requests. The express module will create an application server, and the body-parser module will parse incoming request bodies in a middleware before getting the contents of the body. You then required the os module, which will retrieve the name of the machine running your application. After that, you specified a port for the application and created the variables browsers and maxNumberOfBrowsers. These variables will help manage the number of browser instances that the server can create. In this case, the application is limited to creating five browser instances, which means that the scraper will be able to retrieve data from five pages simultaneously.
Our web server will have the following routes: /, /api/books, and /api/booksDetails.
At the bottom of your server.js file define the / route with the following code:
. . .
app.get('/', (req, res) => {
console.log(os.hostname())
let response = {
msg: 'hello world',
hostname: os.hostname().toString()
}
res.send(response);
});
You will use the / route to check if your application server is running. A GET request sent to this route will return an object containing two properties: msg, which will only say “hello world,” and hostname, which will identify the machine where an instance of the application server is running.
Now define the /api/books route.
At the bottom of your server.js file, add the following code:
. . .
app.post('/api/books', async (req, res) => {
req.setTimeout(timeout);
try {
let data = req.body
console.log(req.body.url)
while (browsers == maxNumberOfBrowsers) {
await sleep(1000)
}
await getBooksHandler(data).then(result => {
let response = {
msg: 'retrieved books ',
hostname: os.hostname(),
books: result
}
console.log('done')
res.send(response)
})
} catch (error) {
res.send({ error: error.toString() })
}
});
The /api/books route will ask the scraper to retrieve the book-related metadata on a given web page. A POST request to this route will check if the number of browsers running equals the maxNumberOfBrowsers, and if it isn’t, it will call the method getBooksHandler(). This method will create a new instance of the PuppeteerManager class and retrieve the book’s metadata. Once it has retrieved the metadata, it returns in the response body to the client. The response object will contain a string, msg, that reads retrieved books , an array, books, that contains the metadata, and another string, hostname, that will return the name of the machine/container/pod where the application is running.
We have one last route to define: /api/booksDetails.
Add the following code to the bottom of your server.js file:
. . .
app.post('/api/booksDetails', async (req, res) => {
req.setTimeout(timeout);
try {
let data = req.body
console.log(req.body.url)
while (browsers == maxNumberOfBrowsers) {
await sleep(1000)
}
await getBookDetailsHandler(data).then(result => {
let response = {
msg: 'retrieved book details',
hostname: os.hostname(),
url: req.body.url,
booksDetails: result
}
console.log('done', response)
res.send(response)
})
} catch (error) {
res.send({ error: error.toString() })
}
});
Sending a POST request to the /api/booksDetails route will ask the scraper to retrieve the missing information for a given book. The application server will check if the number of browsers running is equal to the maxNumberOfBrowsers. If it is, it will call the sleep() method and wait 1 second before checking again, and if it isn’t equal, it will call the method getBookDetailsHandler(). Like the getBooksHandler() method, this method will create a new instance of the PuppeteerManager class and retrieve the missing information.
The program will then return the retrieved data in the response body to the client. The response object will contain a string, msg, saying retrieved book details, a string, hostname, that will return the name of the machine running the application, and another string, url, containing the project page’s URL. It will also contain an array, booksDetails, containing all the missing information for a book.
Your web server will also have the following functions : getBooksHandler(), getBookDetailsHandler(), and sleep().
Start with the getBooksHandler() function.
At the bottom of your server.js file, add the following code:
. . .
async function getBooksHandler(arg) {
let pMng = require('./puppeteerManager')
let puppeteerMng = new pMng.PuppeteerManager(arg)
browsers += 1
try {
let books = await puppeteerMng.getAllBooks().then(result => {
return result
})
browsers -= 1
return books
} catch (error) {
browsers -= 1
console.log(error)
}
}
The getBooksHandler() function will create a new instance of the PuppeteerManager class. It will increase the number of browsers running by one, pass the object containing the necessary information to retrieve the books, and then call the getAllBooks() method. After the data is retrieved, it decreases the number of browsers running by one and then returns the newly retrieved data to the /api/books route.
Now add the following code to define the getBookDetailsHandler() function:
. . .
async function getBookDetailsHandler(arg) {
let pMng = require('./puppeteerManager')
let puppeteerMng = new pMng.PuppeteerManager(arg)
browsers += 1
try {
let booksDetails = await puppeteerMng.getBooksDetails().then(result => {
return result
})
browsers -= 1
return booksDetails
} catch (error) {
browsers -= 1
console.log(error)
}
}
The getBookDetailsHandler() function will create a new instance of the PuppeteerManager class. It functions just like the getBooksHandler() function except it handles the missing metadata for each book and returns it to the /api/booksDetails route.
At the bottom of your server.js file add the following code to define the sleep() function:
function sleep(ms) {
console.log(' running maximum number of browsers')
return new Promise(resolve => setTimeout(resolve, ms))
}
The sleep() function makes the code wait for a specific amount of time when the number of browsers is equal to the maxNumberOfBrowsers. We pass an integer to this function, and this integer represents the amount of time in milliseconds that the code should wait until it can check if browsers is equal to the maxNumberOfBrowsers.
Your file is now complete.
After creating all the necessary routes and functions, the server.js file will look like this:
const express = require('express');
const bodyParser = require('body-parser')
const os = require('os');
const PORT = 5000;
const app = express();
let timeout = 1500000
app.use(bodyParser.urlencoded({ extended: true }))
app.use(bodyParser.json())
let browsers = 0
let maxNumberOfBrowsers = 5
app.get('/', (req, res) => {
console.log(os.hostname())
let response = {
msg: 'hello world',
hostname: os.hostname().toString()
}
res.send(response);
});
app.post('/api/books', async (req, res) => {
req.setTimeout(timeout);
try {
let data = req.body
console.log(req.body.url)
while (browsers == maxNumberOfBrowsers) {
await sleep(1000)
}
await getBooksHandler(data).then(result => {
let response = {
msg: 'retrieved books ',
hostname: os.hostname(),
books: result
}
console.log('done')
res.send(response)
})
} catch (error) {
res.send({ error: error.toString() })
}
});
app.post('/api/booksDetails', async (req, res) => {
req.setTimeout(timeout);
try {
let data = req.body
console.log(req.body.url)
while (browsers == maxNumberOfBrowsers) {
await sleep(1000)
}
await getBookDetailsHandler(data).then(result => {
let response = {
msg: 'retrieved book details',
hostname: os.hostname(),
url: req.body.url,
booksDetails: result
}
console.log('done', response)
res.send(response)
})
} catch (error) {
res.send({ error: error.toString() })
}
});
async function getBooksHandler(arg) {
let pMng = require('./puppeteerManager')
let puppeteerMng = new pMng.PuppeteerManager(arg)
browsers += 1
try {
let books = await puppeteerMng.getAllBooks().then(result => {
return result
})
browsers -= 1
return books
} catch (error) {
browsers -= 1
console.log(error)
}
}
async function getBookDetailsHandler(arg) {
let pMng = require('./puppeteerManager')
let puppeteerMng = new pMng.PuppeteerManager(arg)
browsers += 1
try {
let booksDetails = await puppeteerMng.getBooksDetails().then(result => {
return result
})
browsers -= 1
return booksDetails
} catch (error) {
browsers -= 1
console.log(error)
}
}
function sleep(ms) {
console.log(' running maximum number of browsers')
return new Promise(resolve => setTimeout(resolve, ms))
}
app.listen(PORT);
console.log(`Running on port: ${PORT}`);
In this step, you finished creating the application server. In the next step, you will create an image for the application server and then deploy it to your Kubernetes cluster.
Step 5 — Building the Docker Image
In this step, you will create a Docker image containing your scraper application. In Step 6 you will deploy that image to a Kubernetes cluster.
To create a Docker image of your application, you will need to create a Dockerfile and then build the container.
Make sure you are still in the ./server folder.
Now create the Dockerfile and open it:
- nano Dockerfile
Write the following code inside Dockerfile:
FROM node:10
RUN apt-get update
RUN apt-get install -yyq ca-certificates
RUN apt-get install -yyq libappindicator1 libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6
RUN apt-get install -yyq gconf-service lsb-release wget xdg-utils
RUN apt-get install -yyq fonts-liberation
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 5000
CMD [ "node", "server.js" ]
Most of the code in this block is standard command line code for a Dockerfile. You built the image from a node:10 image. Next, you used the RUN command to install the necessary packages to run Puppeteer in a Docker container, and then you created the app directory. You copied your scraper’s package.json file to the app directory and installed the dependencies specified inside the package.json file. Lastly, you bundled the app source, exposed the app on port 5000, and selected server.js as the entry file.
Now create a .dockerignore file and open it. This will keep sensitive and unnecessary files out of version control.
Create the file using your preferred text editor:
- nano .dockerignore
Add the following content to the file:
node_modules
npm-debug.log
After creating the Dockerfile and the .dockerignore file, you can build the Docker image of the application and push it to a repository in your Docker Hub account. Before pushing the image, check that you are signed in to your Docker Hub account.
Sign in to Docker Hub:
- docker login --username=your_username --password=your_password
Build the image:
- docker build -t your_username/concurrent-scraper .
Now it’s time to test the scraper. In this test, you will send a request to each route.
First, start the app:
- docker run -p 5000:5000 -d your_username/concurrent-scraper
Now use curl to send a GET request to the / route:
- curl http://localhost:5000/
By sending a GET request to the / route, you should receive a response containing a msg saying hello world and a hostname. This hostname is the id of your Docker container. You should see an output similar to this, but with your machine’s unique ID:
Output{"msg":"hello world","hostname":"0c52d53f97d3"}
Now send a POST request to the /api/books route to get the metadata of all the books displayed on one web page:
- curl --header "Content-Type: application/json" --request POST --data '{"url": "http://books.toscrape.com/index.html" , "nrOfPages":1 , "commands":[{"description": "get items metadata", "locatorCss": ".product_pod","type": "getItems"},{"description": "go to next page","locatorCss": ".next > a:nth-child(1)","type": "Click"}]}' http://localhost:5000/api/books
By sending a POST request to the /api/books route you will receive a response containing a msg saying retrieved books , a hostname similar to the one in the previous request, and a books array containing all 20 books displayed on the first page of the books.toscrape website. You should see an output like this, but with your machine’s unique ID:
Output{"msg":"retrieved books ","hostname":"0c52d53f97d3","books":[{"title":"A Light in the Attic","price":null,"rating":0,"url":"http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html"},{"title":"Tipping the Velvet","price":null,"rating":0,"url":"http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html"}, [ . . . ] }]}
Now send a POST request to the /api/booksDetails route to get the missing information for a random book:
- curl --header "Content-Type: application/json" --request POST --data '{"url": "http://books.toscrape.com/catalogue/slow-states-of-collapse-poems_960/index.html" , "nrOfPages":1 , "commands":[{"description": "get item details", "locatorCss": "article.product_page","type": "getItemDetails"}]}' http://localhost:5000/api/booksDetails
By sending a POST request to the /api/booksDetails route you will receive a response containing a msg saying retrieved book details, a booksDetails object containing the missing details of this book, a url containing the address of the product’s page, as well as a hostname like the one in the previous requests. You will see an output like this:
Output{"msg":"retrieved book details","hostname":"0c52d53f97d3","url":"http://books.toscrape.com/catalogue/slow-states-of-collapse-poems_960/index.html","booksDetails":{"description":"The eagerly anticipated debut from one of Canada’s most exciting new poets In her debut collection, Ashley-Elizabeth Best explores the cultivation of resilience during uncertain and often trying times [...]","upc":"b4fd5943413e089a","nrOfReviews":0,"availability":17}}
If your curl commands don’t return the correct responses, make sure that the code in the files puppeteerManager.js and server.js match the final code blocks in the previous two steps. Also, make sure that the Docker container is running and that it didn’t crash. You can do that by trying to run the Docker image without the -d option (this option makes the Docker image run in the detached mode), then send an HTTP request to one of the routes.
If you still encounter errors when trying to run the Docker image, try stopping all running containers and running the scraper image without the -d option.
First stop all containers:
- docker stop $(docker ps -a -q)
Then run the Docker command without the -d flag:
- docker run -p 5000:5000 your_username/concurrent-scraper
If you don’t encounter any errors, clean the terminal window:
- clear
Now that you have successfully tested the image, you can send it to your repository. Push the image to a repository in your Docker Hub account:
- docker push your_username/concurrent-scraper:latest
With your scraper application now available as an image on Docker Hub, you are ready to deploy to Kubernetes. This will be your next step.
Step 6 — Deploying the Scraper to Kubernetes
With your scraper image built and pushed to your repository, you are now ready for deployment.
First, use kubectl to create a new namespace called concurrent-scraper-context:
- kubectl create namespace concurrent-scraper-context
Set concurrent-scraper-context as the default context:
- kubectl config set-context --current --namespace=concurrent-scraper-context
To create your application’s deployment, you will need to create a file called app-deployment.yaml, but first, you must navigate to the k8s directory inside your project. This is where you will store all your Kubernetes files.
Go to the k8s directory inside your project:
- cd ../k8s
Create the app-deployment.yaml file and open it:
- nano app-deployment.yaml
Write the following code inside app-deployment.yaml. Make sure to replace your_DockerHub_username with your unique username:
apiVersion: apps/v1
kind: Deployment
metadata:
name: scraper
labels:
app: scraper
spec:
replicas: 5
selector:
matchLabels:
app: scraper
template:
metadata:
labels:
app: scraper
spec:
containers:
- name: concurrent-scraper
image: your_DockerHub_username/concurrent-scraper
ports:
- containerPort: 5000
Most of the code in the preceding block is standard for a Kubernetes deployment file. First, you set the name of your app deployment to scraper, then you set the number of pods to 5, and then you set the name of your container to concurrent-scraper. After that, you specified the image that you want to use to build your app as your_DockerHub_username/concurrent-scraper, but you will use your actual Docker Hub username. Lastly, you specified that you want your app to use port 5000.
After creating the deployment file, you are ready to deploy the app to the cluster.
Deploy the app:
- kubectl apply -f app-deployment.yaml
You can monitor the status of your deployment by running the following command:
- kubectl get deployment -w
After running the command, you will see an output like this:
OutputNAME READY UP-TO-DATE AVAILABLE AGE
scraper 0/5 5 0 7s
scraper 1/5 5 1 23s
scraper 2/5 5 2 25s
scraper 3/5 5 3 25s
scraper 4/5 5 4 33s
scraper 5/5 5 5 33s
It will take a couple of seconds for all deployments to start running, but once they are, you will have five instances of your scraper running. Each instance can scrape five pages simultaneously, so you will be able to scrape 25 pages simultaneously, thus reducing the time needed to scrape all 400 pages.
To access your app from outside the cluster, you will need to create a service. This service will be a load balancer, and it will require a file called load-balancer.yaml.
Create the load-balancer.yaml file and open it:
- nano load-balancer.yaml
Write the following code inside load-balancer.yaml:
apiVersion: v1
kind: Service
metadata:
name: load-balancer
labels:
app: scraper
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 5000
protocol: TCP
selector:
app: scraper
Most of the code in the preceding block is standard for a service file. First, you set the name of your service to load-balancer. You specified the service type, and then you made the service accessible on port 80. Lastly, you specified that this service is for the app, scraper.
Now that you have created your load-balancer.yaml file, deploy the service to the cluster.
Deploy the service:
- kubectl apply -f load-balancer.yaml
Run the following command to monitor the status of your service:
- kubectl get services -w
After running this command, you will see an output like this, but it will take a few seconds for the external IP to appear:
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
load-balancer LoadBalancer 10.245.91.92 <pending> 80:30802/TCP 10s
load-balancer LoadBalancer 10.245.91.92 161.35.252.69 80:30802/TCP 69s
Your service’s EXTERNAL-IP and CLUSTER-IP will differ from the ones above. Make a note of your EXTERNAL-IP. You will use it in the next section.
In this step, you deployed the scraper application to your Kubernetes cluster. In the next step, you will create a client application to interact with your newly deployed application.
Step 7 — Creating the Client Application
In this step, you will build your client application, which will require the following three files: main.js, lowdbHelper.js, and books.json. The main.js file is the main file of your client application. It sends requests to your application server and then saves the retrieved data using a method that you will create inside the lowdbHelper.js file. The lowdbHelper.js file saves data in a local file and retrieves the data in it. The books.json file is the local file where you will save all your scraped data.
First return to your client directory:
- cd ../client
Because they are smaller than main.js, you will create the lowdbHelper.js and books.json files first.
Create and open a file called lowdbHelper.js:
- nano lowdbHelper.js
Add the following code to the lowdbHelper.js file:
const lowdb = require('lowdb')
const FileSync = require('lowdb/adapters/FileSync')
const adapter = new FileSync('books.json')
In this code block, you have required the module lowdb and then required the adapter FileSync, which you need to save and read data. You then direct the program to store data in a JSON file called books.json.
Add the following code to the bottom of the lowdbHelper.js file:
. . .
class LowDbHelper {
constructor() {
this.db = lowdb(adapter);
}
getData() {
try {
let data = this.db.getState().books
return data
} catch (error) {
console.log('error', error)
}
}
saveData(arg) {
try {
this.db.set('books', arg).write()
console.log('data saved successfully!!!')
} catch (error) {
console.log('error', error)
}
}
}
module.exports = { LowDbHelper }
Here you have created a class called LowDbHelper. This class contains the following two methods: getData() and saveData(). The first will retrieve the books saved inside the books.json file, and the second will save your books to the same file.
Your completed lowdbHelper.js will look like this:
const lowdb = require('lowdb')
const FileSync = require('lowdb/adapters/FileSync')
const adapter = new FileSync('books.json')
class LowDbHelper {
constructor() {
this.db = lowdb(adapter);
}
getData() {
try {
let data = this.db.getState().books
return data
} catch (error) {
console.log('error', error)
}
}
saveData(arg) {
try {
this.db.set('books', arg).write()
//console.log('data saved successfully!!!')
} catch (error) {
console.log('error', error)
}
}
}
module.exports = { LowDbHelper }
Now that you have created the lowdbHelper.js file, it’s time to create the books.json file.
Create the books.json file and open it:
- nano books.json
Add the following code:
{
"books": []
}
The books.json file consists of an object with a property called books. The initial value of this property is an empty array. Later, when you retrieve the books, this is where your program will save them.
Now that you have created the lowdbHelper.js and the books.json files, you will create the main.js file.
Create main.js and open it:
- nano main.js
Add the following code to main.js:
let axios = require('axios')
let ldb = require('./lowdbHelper.js').LowDbHelper
let ldbHelper = new ldb()
let allBooks = ldbHelper.getData()
let server = "http://your_load_balancer_external_ip_address"
let podsWorkDone = []
let booksDetails = []
let errors = []
In this chunk of code, you have required the lowdbHelper.js file and a module called axios. You will use axios to send HTTP requests to your scraper; the lowdbHelper.js file will save retrieved books, and the allBooks variable will store all books saved in the books.json file. Before retrieving any book, this variable will hold an empty array; the server variable will store the EXTERNAL-IP of the load balancer that you created in the previous section. Make sure to replace this with your unique IP. The podsWorkDone variable will track the number of pages that each instance of your scraper has handled. The booksDetails variable will store the details retrieved for individual books, and the errors variable will track any errors that may occur when trying to retrieve the books.
Now we need to build some functions for each part of the scraper process.
Add the next code block to the bottom of the main.js file:
. . .
function main() {
let execute = process.argv[2] ? process.argv[2] : 0
execute = parseInt(execute)
switch (execute) {
case 0:
getBooks()
break;
case 1:
getBooksDetails()
break;
}
}
You are now creating a function called main(), which consists of a switch statement that will call either the getBooks() or getBooksDetails() function based on a passed input.
Replace the break; beneath getBooks() with the following code:
. . .
function getBooks() {
console.log('getting books')
let data = {
url: 'http://books.toscrape.com/index.html',
nrOfPages: 20,
commands: [
{
description: 'get items metadata',
locatorCss: '.product_pod',
type: "getItems"
},
{
description: 'go to next page',
locatorCss: '.next > a:nth-child(1)',
type: "Click"
}
],
}
let begin = Date.now();
axios.post(`${server}/api/books`, data).then(result => {
let end = Date.now();
let timeSpent = (end - begin) / 1000 + "secs";
console.log(`took ${timeSpent} to retrieve ${result.data.books.length} books`)
ldbHelper.saveData(result.data.books)
})
}
Here you have created a function called getBooks(). This code assigns the object containing the necessary information to scrape all 20 pages to a variable called data. The first command in the commands array of this object retrieves all 20 books displayed on a page, and the second command clicks the next button on a page, thus making the browser navigate to the next page. This means that the first command will repeat 20 times, and the second 19 times. A POST request sent using axios to the /api/books route will send this object to your application server, and the scraper will then retrieve the basic metadata for every book displayed on the first 20 pages of the books.toscrape website. It then saves the retrieved data using the LowDbHelper class inside the lowdbHelper.js file.
Now code the second function, which will handle the more specific book data on individual pages.
Replace the break; beneath getBooksDetails() with the following code:
. . .
function getBooksDetails() {
let begin = Date.now()
for (let j = 0; j < allBooks.length; j++) {
let data = {
url: allBooks[j].url,
nrOfPages: 1,
commands: [
{
description: 'get item details',
locatorCss: 'article.product_page',
type: "getItemDetails"
}
]
}
sendRequest(data, function (result) {
parseResult(result, begin)
})
}
}
The getBooksDetails() function will go through the allBooks array, which holds all the books, and for each book inside this array, and create an object that will contain the information needed to scrape a page. After creating this object, it will then pass it to the sendRequest() function. Then it will use the value that the sendRequest() function returns and pass this value to a function called parseResult().
Add the following code to the bottom of the main.js file:
. . .
async function sendRequest(payload, cb) {
let book = payload
try {
await axios.post(`${server}/api/booksDetails`, book).then(response => {
if (Object.keys(response.data).includes('error')) {
let res = {
url: book.url,
error: response.data.error
}
cb(res)
} else {
cb(response.data)
}
})
} catch (error) {
console.log(error)
let res = {
url: book.url,
error: error
}
cb({ res })
}
}
Now you are creating a function called sendRequest(). You will use this function to send all 400 requests to your application server containing your scraper. The code assigns the object containing the necessary information to scrape a page to a variable called book. You then send this object in a POST request to the /api/booksDetails route on your application server. The response is sent back to the getBooksDetails() function.
Now create the parseResult() function.
Add the following code to the bottom of the main.js file:
. . .
function parseResult(result, begin){
try {
let end = Date.now()
let timeSpent = (end - begin) / 1000 + "secs ";
if (!Object.keys(result).includes("error")) {
let wasSuccessful = Object.keys(result.booksDetails).length > 0 ? true : false
if (wasSuccessful) {
let podID = result.hostname
let podsIDs = podsWorkDone.length > 0 ? podsWorkDone.map(pod => { return Object.keys(pod)[0]}) : []
if (!podsIDs.includes(podID)) {
let podWork = {}
podWork[podID] = 1
podsWorkDone.push(podWork)
} else {
for (let pwd = 0; pwd < podsWorkDone.length; pwd++) {
if (Object.keys(podsWorkDone[pwd]).includes(podID)) {
podsWorkDone[pwd][podID] += 1
break
}
}
}
booksDetails.push(result)
} else {
errors.push(result)
}
} else {
errors.push(result)
}
console.log('podsWorkDone', podsWorkDone, ', retrieved ' + booksDetails.length + " books, ",
"took " + timeSpent + ", ", "used " + podsWorkDone.length + " pods", " errors: " + errors.length)
saveBookDetails()
} catch (error) {
console.log(error)
}
}
parseResult() receives the result of the function sendRequest() containing missing book details. It then parses the result and retrieves the hostname of the pod that handled the request and assigns it to the podID variable. It checks if this podID is already part of the podsWorkDone array; if it isn’t, it will add the podId to the podsWorkDone array and set the number of work done to 1. But if it is, it will increase the number of work done by this pod by 1. The code will then add the result to the booksDetails array, output the overall progress of the getBooksDetails() function, and then call the saveBookDetails() function.
Now add the following code to build the saveBookDetails() function:
. . .
function saveBookDetails() {
let books = ldbHelper.getData()
for (let b = 0; b < books.length; b++) {
for (let d = 0; d < booksDetails.length; d++) {
let item = booksDetails[d]
if (books[b].url === item.url) {
books[b].booksDetails = item.booksDetails
break
}
}
}
ldbHelper.saveData(books)
}
main()
saveBookDetails() gets all the books stored in the books.json file using the LowDbHelper class and assigns it to a variable called books. It then loops through the books and booksDetails arrays to see if it finds elements in both arrays with the same url property. If it does, it will add the booksDetails property of the element in the booksDetails array and assign it to the element in the books array. Then it will overwrite the contents of the books.json file with the contents of the books array looped in this function. After creating the saveBookDetails() function, the code will call the main() function to make this file usable. Otherwise, executing this file wouldn’t produce the desired outcome.
Your completed main.js file will look like this:
let axios = require('axios')
let ldb = require('./lowdbHelper.js').LowDbHelper
let ldbHelper = new ldb()
let allBooks = ldbHelper.getData()
let server = "http://your_load_balancer_external_ip_address"
let podsWorkDone = []
let booksDetails = []
let errors = []
function main() {
let execute = process.argv[2] ? process.argv[2] : 0
execute = parseInt(execute)
switch (execute) {
case 0:
getBooks()
break;
case 1:
getBooksDetails()
break;
}
}
function getBooks() {
console.log('getting books')
let data = {
url: 'http://books.toscrape.com/index.html',
nrOfPages: 20,
commands: [
{
description: 'get items metadata',
locatorCss: '.product_pod',
type: "getItems"
},
{
description: 'go to next page',
locatorCss: '.next > a:nth-child(1)',
type: "Click"
}
],
}
let begin = Date.now();
axios.post(`${server}/api/books`, data).then(result => {
let end = Date.now();
let timeSpent = (end - begin) / 1000 + "secs";
console.log(`took ${timeSpent} to retrieve ${result.data.books.length} books`)
ldbHelper.saveData(result.data.books)
})
}
function getBooksDetails() {
let begin = Date.now()
for (let j = 0; j < allBooks.length; j++) {
let data = {
url: allBooks[j].url,
nrOfPages: 1,
commands: [
{
description: 'get item details',
locatorCss: 'article.product_page',
type: "getItemDetails"
}
]
}
sendRequest(data, function (result) {
parseResult(result, begin)
})
}
}
async function sendRequest(payload, cb) {
let book = payload
try {
await axios.post(`${server}/api/booksDetails`, book).then(response => {
if (Object.keys(response.data).includes('error')) {
let res = {
url: book.url,
error: response.data.error
}
cb(res)
} else {
cb(response.data)
}
})
} catch (error) {
console.log(error)
let res = {
url: book.url,
error: error
}
cb({ res })
}
}
function parseResult(result, begin){
try {
let end = Date.now()
let timeSpent = (end - begin) / 1000 + "secs ";
if (!Object.keys(result).includes("error")) {
let wasSuccessful = Object.keys(result.booksDetails).length > 0 ? true : false
if (wasSuccessful) {
let podID = result.hostname
let podsIDs = podsWorkDone.length > 0 ? podsWorkDone.map(pod => { return Object.keys(pod)[0]}) : []
if (!podsIDs.includes(podID)) {
let podWork = {}
podWork[podID] = 1
podsWorkDone.push(podWork)
} else {
for (let pwd = 0; pwd < podsWorkDone.length; pwd++) {
if (Object.keys(podsWorkDone[pwd]).includes(podID)) {
podsWorkDone[pwd][podID] += 1
break
}
}
}
booksDetails.push(result)
} else {
errors.push(result)
}
} else {
errors.push(result)
}
console.log('podsWorkDone', podsWorkDone, ', retrieved ' + booksDetails.length + " books, ",
"took " + timeSpent + ", ", "used " + podsWorkDone.length + " pods,", " errors: " + errors.length)
saveBookDetails()
} catch (error) {
console.log(error)
}
}
function saveBookDetails() {
let books = ldbHelper.getData()
for (let b = 0; b < books.length; b++) {
for (let d = 0; d < booksDetails.length; d++) {
let item = booksDetails[d]
if (books[b].url === item.url) {
books[b].booksDetails = item.booksDetails
break
}
}
}
ldbHelper.saveData(books)
}
main()
You have now created the client application and are ready to interact with the scraper in your Kubernetes cluster. In the next step, you will use this client application and the application server to scrape all 400 books.
Step 8 — Scraping the Website
Now that you have created the client application and the server-side scraper application it’s time to scrape the books.toscrape website. You will first retrieve the metadata for all 400 books. Then you will retrieve the missing details for every single book on its page and monitor how many requests each pod has handled in real-time .
In the ./client directory, run the following command. This will retrieve the basic metadata for all 400 books and save it to your books.json file:
- npm start 0
You will receive the following output:
Outputgetting books
took 40.323secs to retrieve 400 books
Retrieving the metadata for the books displayed on all 20 pages took 40.323 seconds, although this value may differ depending on your internet speed.
Now you want to retrieve the missing details for every book stored in the books.json file while also monitoring the number of requests that each pod handles.
Run npm start again to retrieve the details:
- npm start 1
You will receive an output like this but with different pod IDs:
Output. . .
podsWorkDone [ { 'scraper-59cd578ff6-z8zdd': 69 },
{ 'scraper-59cd578ff6-528gv': 96 },
{ 'scraper-59cd578ff6-zjwfg': 94 },
{ 'scraper-59cd578ff6-nk6fr': 80 },
{ 'scraper-59cd578ff6-h2n8r': 61 } ] , retrieved 400 books, took 56.875secs , used 5 pods, errors: 0
Retrieving the missing details for all 400 books using Kubernetes took less than 60 seconds. Each pod containing the scraper scraped at least 60 pages. This represents a massive performance increase over using one machine.
Now double the number of pods in your Kubernetes cluster to accelerate the retrieval even more:
- kubectl scale deployment scraper --replicas=10
It will take a few moments before the pods are available, so wait at least 10 seconds before running the next command.
Rerun npm start to get the missing details:
- npm start 1
You will receive an output similar to the following but with different pod IDs:
Output. . .
podsWorkDone [ { 'scraper-59cd578ff6-z8zdd': 38 },
{ 'scraper-59cd578ff6-6jlvz': 47 },
{ 'scraper-59cd578ff6-g2mxk': 36 },
{ 'scraper-59cd578ff6-528gv': 41 },
{ 'scraper-59cd578ff6-bj687': 36 },
{ 'scraper-59cd578ff6-zjwfg': 47 },
{ 'scraper-59cd578ff6-nl6bk': 34 },
{ 'scraper-59cd578ff6-nk6fr': 33 },
{ 'scraper-59cd578ff6-h2n8r': 38 },
{ 'scraper-59cd578ff6-5bw2n': 50 } ] , retrieved 400 books, took 34.925secs , used 10 pods, errors: 0
After doubling the number of pods, the time needed to scrape all 400 pages reduced almost by half. It took less than 35 seconds to retrieve all the missing details.
In this section, you sent 400 requests to the application server deployed in your Kubernetes cluster and scraped 400 individual URLs in a short amount of time. You also increased the number of pods in your cluster to improve performance even more.
Conclusion
In this guide, you used Puppeteer, Docker, and Kubernetes to build a concurrent web scraper capable of rapidly scraping 400 web pages. To interact with the scraper, you built a Node.js app that uses axios to send multiple HTTP requests to the server containing the scraper.
Puppeteer includes many additional features. If you want to learn more, check out Puppeteer’s official documentation. To learn more about Node.js, check out our tutorial series on how to code in Node.js.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
A geologist turned programmer
Supporting the open-source community one tutorial at a time. Former Technical Editor at DigitalOcean. Expertise in topics including Ubuntu 22.04, Ubuntu 20.04, CentOS, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
change to
npm install axios lowdb=1.0.0 --save
lowdb was updated in May and requires breaking changes (ESM)
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.