Tutorial
So erstellen Sie ein neuronales Netz zum Übersetzen der Gebärdensprache ins Englische

Der Autor hat Code.org ausgewählt, um im Rahmen des Programms Write for DOnations eine Spende zu erhalten.
Einführung
Computer Vision (deutsch: computerbasiertes Sehen) ist ein Teilbereich der Informatik, mit dem ein höherrangiges Verstehen von Bildern und Videos ermöglicht werden soll. Damit werden Technologien wie lustige Video-Chat-Filter, die Gesichtserkennung Ihres Mobilgeräts und selbstfahrende Autos unterstützt.
In diesem Tutorial nutzen Sie Computer Vision, um einen Übersetzer für die amerikanische Gebärdensprache zu entwickeln, der mithilfe Ihrer Webcam arbeitet. Während des Tutorial werden Sie OpenCV, eine Computer-Vision-Bibliothek, PyTorch zum Einrichten eines tiefen neuronalen Netzes und onnx zum Exportieren Ihres neuronalen Netzes verwenden. Zudem werden Sie eine Computer-Vision-Anwendung erstellen und dabei folgende Konzepte anwenden:
- Sie verwenden dieselbe dreistufige Methode, die auch im Tutorial How To Apply Computer Vision to Build an Emotion-Based Dog Filter (So wenden Sie Computer Vision beim Erstellen eines emotionsbasierten Hundefilters an) genutzt wird: Vorverarbeitung eines Datensatzes, Trainieren eines Modells und Bewertung des Modells.
- Außerdem werden Sie jeden dieser einzelnen Schritte erweitern: Sie nutzen Data Augmentation (Datenanreicherung) für den Umgang mit gedrehten oder nicht zentrierten Händen, Sie ändern die Learning Rate Schedules (Zeitpläne für die Lernrate), um die Modellgenauigkeit zu verbessern, und Sie exportieren Modelle für eine höhere Inferenzgeschwindigkeit.
- Überdies werden Sie auch verwandte Konzepte im maschinellen Lernen erkunden.
Am Ende dieses Tutorials verfügen Sie über einen Übersetzer für die amerikanische Gebärdensprache sowie über ein umfassendes Know-how über das Deep Learning. Sie können auch auf den kompletten Quellcode für dieses Projekt zugreifen.
Voraussetzungen
Um dieses Tutorial zu absolvieren, benötigen Sie Folgendes:
- Eine lokale Entwicklungsumgebung für Python 3 mit mindestens 1 GB RAM. Unter How to Install and Set Up a Local Programming Environment for Python 3 (Installieren und Einrichten einer lokalen Programmierumgebung für Python 3) finden Sie Informationen darüber, wie Sie die benötigten Konfigurationen vornehmen.
- Eine funktionierende Webcam zur Nutzung der Bilderkennung in Echtzeit.
- (Empfohlen) Build an Emotion-Based Dog Filter (Erstellen eines emotionsbasierten Hundes); dieses Tutorial wird zwar nicht explizit verwendet, aber es wird dasselbe Wissen vermittelt und darauf aufgebaut.
Schritt 1 – Erstellen des Projekts und Installieren von Abhängigkeiten
Wir wollen einen Arbeitsbereich für dieses Projekt erstellen und die Abhängigkeiten installieren, die wir benötigen.
Beginnen Sie mit den Linux-Distributionen, indem Sie Ihre Systempaketverwaltung vorbereiten und das Python3 virtualenv-Paket installieren. Verwenden Sie Folgendes:
Wir nennen unseren Arbeitsbereich SignLanguage (Gebärdensprache):
Navigieren Sie zum Verzeichnis SignLanguage:
Erstellen Sie dann eine neue virtuelle Umgebung für das Projekt:
Aktivieren Sie Ihre Umgebung:
Installieren Sie anschließend PyTorch, ein Deep-Learning-Framework für Python, das wir in diesem Tutorial verwenden werden.
Auf macOS installieren Sie Pytorch mit dem folgenden Befehl:
Auf Linux und Windows verwenden Sie die folgenden Befehle für einen reinen CPU-Build:
Installieren Sie nun vorgefertigte Binärdateien für OpenCV, numpy und onnx, die als Bibliotheken für Computer Vision, lineare Algebra, den Export des KI-Modells und die Ausführung des KI-Modells dienen. OpenCV bietet Hilfsfunktionen wie Bilddrehung und numpy bietet Hilfsfunktionen für lineare Algebra an, z. B. eine Matrixinversion:
Auf Linux-Distributionen müssen Sie libSM.so installieren:
Wenn die Abhängigkeiten installiert wurden, erstellen wir die erste Version unseres Gebärdensprachenübersetzers: einen Gebärdensprachen-Classifier.
Schritt 2 — Vorbereiten des Datensatzes für die Klassifikation der Gebärdensprache
In diesen nächsten drei Abschnitten erstellen Sie einen Gebärdensprachen-Classifier mithilfe eines neuronalen Netzes. Ihr Ziel besteht darin, ein Modell zu erstellen, das ein Bild einer Hand als Eingabe annimmt und einen Buchstaben ausgibt.
Für das Erstellen eines Klassifizierungsmodells für das maschinelle Lernen sind Sie die folgenden drei Schritte erforderlich:
- Vorbearbeiten der Daten: Wenden Sie one-hot encoding (One-Hot-Kodierung) auf Ihre Labels an und umschließen Sie Ihre Daten mit PyTorch-Tensoren. Trainieren Sie Ihr Modell auf angereicherten Daten, um es auf „unübliche“ Eingabedaten vorzubereiten, z. B. eine außermittige oder eine gedrehte Hand.
- Legen Sie das Modell fest und trainieren Sie es: Richten Sie ein neuronales Netz mit PyTorch ein. Legen Sie die Hyperparameter für das Training fest (z. B. wie lange das Training dauern soll) und führen Sie ein stochastisches Gradientenverfahren durch. Variieren Sie zudem einen bestimmten Hyperparameter für das Training: Learning Rate Schedule. Dadurch wird die Modellgenauigkeit erhöht.
- Führen Sie eine Vorhersage mit dem Modell aus: Bewerten Sie das neuronale Netz anhand Ihrer Validierungsdaten, um dessen Genauigkeit zu erfassen. Exportieren Sie dann das Modell in ein Format namens ONNX, um höhere Inferenzgeschwindigkeiten zu erreichen.
In diesem Abschnitt des Tutorials führen Sie Schritt 1 von 3 durch. Sie werden die Daten herunterladen, ein Dataset-Objekt erstellen, das wiederholt auf Ihre Daten angewendet wird, und abschließend noch die Data Augmentation anwenden. Am Ende dieses Schritts verfügen Sie über ein Programm, mit dem Sie auf Bilder und Labels in Ihrem Datensatz zugreifen können, um Ihr Modell zu füttern.
Laden Sie zuerst den Datensatz in Ihr aktuelles Arbeitsverzeichnis herunter:
Anmerkung: Auf makOS ist wget standardmäßig nicht verfügbar. Installieren Sie dazu HomeBrew, indem Sie diesem DigitalOcean Tutorial folgen. Führen Sie dann brew install wget aus.
Entzippen Sie die Zip-Datei, die das Verzeichnis data/ enthält:
Erstellen Sie eine neue Datei namens step_2_dataset.py:
Importieren Sie wie zuvor die erforderlichen Hilfsfunktionen und erstellen Sie die Klasse, die Ihre Daten enthalten soll. Erstellen Sie die Trainings- und Testdaten zum Zwecke der Datenverarbeitung. Sie implementieren die Dataset-Schnittstelle von PyTorch, damit Sie die integrierte Daten-Pipeline von PyTorch laden und für den Datensatz Ihrer Gebärdensprachenklassifikation verwenden können:
Löschen Sie den Platzhalter pass in der Klasse SignLanguageMNIST. Fügen Sie an seiner Stelle eine Methode hinzu, um ein Label Mapping zu generieren:
Die Labels reichen von 0 bis 25. Die Buchstaben J (9) und Z (25) sind jedoch ausgeschlossen. Das bedeutet, dass es nur 24 gültige Label-Werte gibt. Damit der Satz aller von 0 ausgehenden Label-Werte zusammenhängend ist, werden alle Labels [0, 23] zugeordnet. Dieses Mapping von den Datensätzen [0, 23] bis zu den Buchstabenindizes [0, 25] wird mithilfe der Methode get_label_mapping herbeigeführt.
Als Nächstes fügen Sie eine Methode hinzu, um Labels und Beispielproben aus einer CSV-Datei zu extrahieren. Im Folgenden wird davon ausgegangen, dass jede Zeile mit dem label startet, auf das 784-Pixelwerte folgen. Diese 784 Pixelwerte repräsentieren ein 28x28 Bild:
Eine Erklärung darüber, wie diese 784 Werte ein Bild repräsentieren, finden Sie unter Build an Emotion-Based Dog Filter, Step 4 (Erstellen eines emotionsbasierten Hundes, Schritt 4).
Beachten Sie, dass jede Zeile im csv.reader-Iterable eine Liste von Zeichenfolgen ist; die Aufrufe int und map(int, ...) wandeln alle Zeichenfolgen in Ganzzahlen um. Fügen Sie direkt unter unserer statischen Methode eine Funktion hinzu, die unseren Datenbehälter initialisieren wird:
Diese Funktion startet mit dem Laden von Samples und Labels. Dann umschließt sie die Daten mit NumPy-Arrays. Die mittlere und Standardabweichung wird kurz im folgenden Abschnitt __getitem__ erklärt.
Fügen Sie direkt nach der Funktion __init__ eine Funktion __len__ hinzu. Diese Methode wird für das Dataset benötigt, um zu ermitteln, wann das Iterieren über die Daten beendet werden muss.
Fügen Sie abschließend die Methode __getitem__ hinzu, die ein Wörterbuch zurückgibt, das das Sample und das Label enthält:
Sie verwenden eine Technik namens Data Augmentation, bei der Samples während des Trainings gestört werden, um die Robustheit des Modells gegenüber diesen Störungen zu erhöhen. Hierfür wird insbesondere das Bild über RandomResizedCrop in variierenden Werten und an verschiedenen Stellen eingezoomt. Beachten Sie, dass sich das Einzoomen nicht auf die finale Gebärdensprachenklasse auswirken sollte. So wird das Label nicht transformiert. Sie normalisieren die Eingaben zusätzlich, damit die Bildwerte wie erwartet auf den Bereich [0, 1] neu skaliert werden anstatt auf [0, 255]; verwenden Sie bei der Normalisierung den Datensatz _mean und _std, um dies zu erreichen.
Ihre abgeschlossene Klasse SignLanguageMNIST sieht wie folgt aus:
Wie zuvor überprüfen Sie unsere Datensatz-Hilfsfunktionen, indem Sie den Datensatz SignLanguageMNIST laden. Fügen Sie am Ende Ihrer Datei hinter der Klasse SignLanguageMNIST den folgenden Code hinzu:
Dieser Code initialisiert den Datensatz mithilfe der Klasse SignLanguageMNIST. Für die Trainings- und Validierungssätze wird dann der Datensatz mit einem DataLoader umschlossen. Dadurch wird der Datensatz für den späteren Gebrauch in ein Iterable umgewandelt.
Nun überprüfen Sie, ob die Datensatz-Hilfsfunktionen funktionieren. Erstellen Sie einen Sample-Datensatz-Loader mithilfe von DataLoader und drucken Sie das erste Element dieses Loaders aus. Fügen Sie Folgendes am Ende der Datei hinzu:
Sie können überprüfen, ob Ihre Datei mit der Datei step_2_dataset in diesem (repository) übereinstimmt. Beenden Sie Ihren Editor und führen Sie das Skript mit Folgendem aus:
Dadurch werden folgende Tensoren paarweise ausgegeben. Unsere Datenpipeline gibt zwei Samples und zwei Labels aus. Dies zeigt an, dass unsere Datenpipeline eingerichtet ist und bereit ist, fortzufahren:
Output{'image': tensor([[[[ 0.4337, 0.5022, 0.5707, ..., 0.9988, 0.9646, 0.9646],
[ 0.4851, 0.5536, 0.6049, ..., 1.0502, 1.0159, 0.9988],
[ 0.5364, 0.6049, 0.6392, ..., 1.0844, 1.0844, 1.0673],
...,
[-0.5253, -0.4739, -0.4054, ..., 0.9474, 1.2557, 1.2385],
[-0.3369, -0.3369, -0.3369, ..., 0.0569, 1.3584, 1.3242],
[-0.3712, -0.3369, -0.3198, ..., 0.5364, 0.5364, 1.4783]]],
[[[ 0.2111, 0.2796, 0.3481, ..., 0.2453, -0.1314, -0.2342],
[ 0.2624, 0.3309, 0.3652, ..., -0.3883, -0.0629, -0.4568],
[ 0.3309, 0.3823, 0.4337, ..., -0.4054, -0.0458, -1.0048],
...,
[ 1.3242, 1.3584, 1.3927, ..., -0.4054, -0.4568, 0.0227],
[ 1.3242, 1.3927, 1.4612, ..., -0.1657, -0.6281, -0.0287],
[ 1.3242, 1.3927, 1.4440, ..., -0.4397, -0.6452, -0.2856]]]]), 'label': tensor([[24.],
[11.]])}
Sie haben nun sichergestellt, dass Ihre Datenpipeline funktioniert. Damit ist der erste Schritt – die Verarbeitung Ihrer Daten – abgeschlossen. Nun beinhaltet sie Data Augmentation für eine erhöhte Modellstabilität. Als Nächstes definieren Sie das neuronale Netz und den Optimierer.
Schritt 3 – Erstellen und Trainieren des Gebärdensprachen-Classifiers mittels Deep Learning
Mit einer funktionierenden Datenpipeline definieren Sie nun ein Modell und trainieren es anhand der Daten. Insbesondere erstellen Sie ein neuronales Netz mit sechs Schichten, definieren einen Verlust, einen Optimierer und optimieren abschließend die Verlustfunktion für die Voraussagen mit Ihrem neuronalen Netz. Am Ende dieses Schritts verfügen Sie über einen funktionierenden Gebärdensprachen-Klassifizierer.
Erstellen Sie eine neue Datei namens step_3_train.py:
Importieren Sie die erforderlichen Dienstprogramme:
Definieren Sie ein neuronales PyTorch-Netz, das drei Convolutional Layers (faltende Schichten) enthält, gefolgt von drei vollständig zusammenhängenden Schichten. Fügen Sie dies am Ende Ihres bestehenden Skripts hinzu:
Initialisieren Sie nun das neuronale Netz, definieren Sie eine Verlustfunktion und legen Sie Hyperparameter zur Optimierung fest, indem Sie am Ende des Skripts den folgenden Code hinzufügen:
Schließlich trainieren Sie es für zwei Epochen:
Sie definieren eine Epoche, die eine Iteration des Trainings ist, bei der jedes Trainings-Sample genau einmal verwendet wurde. Am Ende der Hauptfunktion werden die Modellparameter in einer Datei namens „checkpoint.pth“ gespeichert.
Fügen Sie am Ende Ihres Skripts den folgenden Code hinzu, um Bild und Label aus dem Datensatz-Loader zu extrahieren und dann jede mit einer PyTorch Variable zu umschließen:
Dieser Code führt auch die Vorwärtsrechnung und dann die Fehlerrückführung über den Verlust und das neuronale Netz aus.
Fügen Sie am Ende Ihrer Datei Folgendes hinzu, um die Funktion main aufzurufen:
Prüfen Sie nochmals, ob Ihre Datei dem Folgenden entspricht:
Speichern und schließen Sie sie. Starten Sie dann unser Proof-of-Concept-Training, indem Sie Folgendes ausführen:
Während das neuronale Netz trainiert wird, sehen Sie ein Ergebnis, das dem Folgenden ähnelt:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
[1, 0] loss: 0.254097
[1, 100] loss: 0.208116
[1, 200] loss: 0.196270
[1, 300] loss: 0.183676
[1, 400] loss: 0.169824
[1, 500] loss: 0.157704
[1, 600] loss: 0.151408
[1, 700] loss: 0.136470
[1, 800] loss: 0.123326
Um die Verluste niedrig zu halten, können Sie die Anzahl der Epochen auf 5, 10 oder sogar 20 erhöhen. Nach einer bestimmten Trainingszeit wird sich der Netzverlust trotz einer Steigerung der Trainingszeit nicht mehr verringern. Geben Sie einen Learning Rate Schedule vor, der die Lernrate im Laufe der Zeit verringert, um das Problem zu umgehen, das mit der zunehmenden Trainingszeit einhergeht. Wenn Sie verstehen wollen, warum das funktioniert, sehen Sie sich die Visualisierung von Distill an unter „Why Momentum Really Works“ („Warum das Momentum wirklich funktioniert“).
Ändern Sie Ihre Funktion main mit den folgenden zwei Zeilen ab, definieren Sie einen Scheduler und rufen Sie scheduler.step auf. Ändern Sie außerdem die Anzahl der Epochen in 12:
Überprüfen Sie, ob Ihre Datei mit der Datei aus Schritt 3 in diesem Repository übereinstimmt. Die Ausführung des Trainings dauert etwa 5 Minuten. Ihre Ausgabe wird in etwa wie folgt aussehen:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
...
[11, 0] loss: 0.000302
[11, 100] loss: 0.007548
[11, 200] loss: 0.009005
[11, 300] loss: 0.008193
[11, 400] loss: 0.007694
[11, 500] loss: 0.008509
[11, 600] loss: 0.008039
[11, 700] loss: 0.007524
[11, 800] loss: 0.007608
Der erhaltene Verlust beträgt 0,007608, was 3 Größenordnungen kleiner als der anfängliche Verlust von 3,20 ist. Damit wird der zweite Schritt unseres Workflows abgeschlossen, in dem wir das neuronale Netz eingerichtet und trainiert haben. Doch auch ein kleiner Verlust hat eine Bedeutung, wenn auch nur eine sehr kleine. Um die Leistung des Modells in Perspektive zu setzen, werden wir seine Genauigkeit berechnen – der Prozentsatz der Bilder, die das Modell richtig klassifiziert hat.
Schritt 4 – Bewerten des Gebärdensprachen-Classifiers
Sie werden nun Ihren Gebärdensprachen-Klassifizierer bewerten, indem Sie seine Genauigkeit im Validierungssatz berechnen, ein Satz von Bildern, die das Modell während des Trainings nicht gesehen hat. Dadurch erhalten wir ein besseres Bild über die Leistung des Modells als durch den endgültigen Verlustwert. Zudem fügen Sie Dienstprogramme hinzu, um unser trainiertes Modell am Ende des Trainings zu speichern, und laden unser vorab trainiertes Modell, während die Inferenz durchgeführt wird.
Erstellen Sie eine neue Datei namens step_4_evaluate.py.
Importieren Sie die erforderlichen Hilfsfunktionen:
Definieren Sie als Nächstes eine Hilfsfunktion, um die Leistung des neuronalen Netzes zu bewerten. Die folgende Funktion vergleicht den vom neuronalen Netz vorhergesagten Buchstaben mit dem tatsächlichen Buchstaben:
outputs ist eine Liste von Klassenwahrscheinlichkeiten für jedes Sample. Beispielsweise können Outputs für ein einziges Sample [0,1, 0,3, 0,4,] betragen. labels ist eine Liste von Label-Klassen. Die Label-Klasse kann beispielsweise 3 sein.
Y = ... wandelt die Labels in ein NumPy-Array um. Als Nächstes konvertiert Yhat = np.argmax(...) die Wahrscheinlichkeiten der Klasse outputs in vorausgesagte Klassen. Die Liste der Klassenwahrscheinlichkeiten [0,1, 0,3, 0,4, 0,2] würde die vorausgesagte Klasse 2 ergeben, da der Indexwert 2 von 0,4 der größte Wert ist.
Da Y und Yhat nun Klassen sind, können Sie sie vergleichen. Yhat == Y prüft, ob die vorhergesagte Klasse mit der Label-Klasse übereinstimmt, und np.sum(...) ist ein Trick, der die Anzahl der truth-y-Werte berechnet. Anders ausgedrückt: np.sum gibt die Anzahl der Samples aus, die richtig klassifiziert wurden.
Fügen Sie die zweite Funktion batch_evaluate hinzu, die die erste Funktion evaluate auf alle Bilder anwendet:
Batch ist eine Gruppe von Bildern, die als ein einzelner Tensor gespeichert werden. Zuerst erhöhen Sie die Gesamtzahl der Bilder, die Sie evaluieren (n) um die Anzahl der Bilder in diesem Batch. Als Nächstes führen Sie in dem neuronalen Netz eine Inferenz mit diesem Batch von Bildern aus, outputs = net(...). Die Typenprüfung if isinstance(...) konvertiert die Ergebnisse in einen NumPy-Array bei Bedarf. Schließlich verwenden Sie evaluate, um die Anzahl der richtig klassifizierten Samples zu berechnen. Am Ende der Funktion berechnen Sie den prozentualen Anteil der Samples, die Sie richtig klassifiziert haben, score / n.
Fügen Sie abschließend das folgende Skript hinzu, um die vorherigen Hilfsfunktionen zu nutzen:
Dadurch wird ein vorab trainiertes neuronales Netz geladen und seine Leistung auf dem bereitgestellten Gebärdensprachen-Datensatz bewertet. Das Skript gibt hier insbesondere Genauigkeit über die Bilder aus, die Sie für das Training verwendet haben, und einen separaten Satz von Bildern, die Sie für Testzwecke aufgehoben haben und die validation set heißen.
Als Nächstes exportieren Sie das PyTorch in eine ONNX-Binärdatei. Diese Binärdatei kann dann in der Produktion verwendet werden, um mit Ihrem Modell eine Inferenz auszuführen. Am wichtigsten ist, dass der Code, der diese Binärdatei ausführt, keine Kopie der ursprünglichen Netzwerkdefinition benötigt. Fügen Sie am Ende der Funktion validate Folgendes hinzu:
Dadurch wird das ONNX-Modell exportiert, das exportierte Modell überprüft und dann eine Inferenz mit dem exportierten Modell ausgeführt. Überprüfen Sie nochmals, ob Ihre Datei mit der Datei aus Schritt 4 in diesem Repository übereinstimmt.
Führen Sie Folgendes aus, um den Checkpoint vom letzten Schritt zu verwenden und zu evaluieren:
Dadurch erhalten Sie eine ähnliche Ausgabe wie die Folgende, die nicht nur bestätigt, dass Ihr exportiertes Modell funktioniert, sondern auch Ihr ursprüngliches PyTorch-Modell bestätigt:
Output========== PyTorch ==========
Training accuracy: 99.9
Validation accuracy: 97.4
========== ONNX ==========
Training accuracy: 99.9
Validation accuracy: 97.4
Ihr neuronales Netz erreicht eine Trainingsgenauigkeit von 99,9 % und eine Validierungsgenauigkeit von 97,4 %. Diese Lücke zwischen Trainings- und Validierungsgenauigkeit deutet auf eine Überanpassung Ihres Modells hin. Das heißt, dass Ihr Modell die Trainingsdaten gespeichert hat, anstatt generalisierbare Muster zu erlernen. Weiterführende Informationen zu den Implikationen und Ursachen der Überanpassung finden Sie in Understanding Bias-Variance Tradeoffs (Das Spannungsfeld von Verzerrungsvarianzen verstehen).
Nun haben wir einen Gebärdensprachen-Klassifizierer fertiggestellt. Im Grunde genommen kann unser Modell die Gebärden fast immer korrekt erkennen und voneinander unterscheiden. Da dies bereits ein recht gutes Modell ist, fahren wir nun mit der letzten Stufe unserer Anwendung fort. Wir werden diesen Gebärdensprachen-Classifier in einer Webcam-Anwendung in Echtzeit einsetzen.
Schritt 5 – Verknüpfen der Kameraaufzeichnungen
Ihr nächstes Ziel besteht darin, die Kamera des Computers mit Ihrem Gebärdensprachen-Klassifizierer zu verknüpfen. Sie erfassen die Eingangsdaten der Kamera, klassifizieren die angezeigte Gebärdensprache und melden dann die klassifizierte Gebärde an den Benutzer zurück.
Erstellen Sie nun ein Python-Skript für die Gesichtserkennung. Erstellen Sie die Datei step_6_camera.py mit nano oder Ihrem bevorzugten Texteditor:
Fügen Sie in der Datei den folgenden Code hinzu:
Dieser Code importiert OpenCV, die Ihre Bildprogramme enthält, und die ONNX-Laufzeit. Das ist alles, was Sie mit Ihrem Modell in der Inferenz ausführen müssen. Der Rest des Codes ist eine typische Python-Programmvorgabe.
Ersetzen Sie nun pass in der Funktion main durch den folgenden Code, der einen Gebärdensprachen-Classifier mit den zuvor trainierten Parametern initialisiert. Fügen Sie zudem ein Mapping zwischen den Indizes und den Buchstaben sowie den Bildstatistiken hinzu:
Sie werden Elemente dieses Testskripts aus der offiziellen OpenCV verwenden. Aktualisieren Sie insbesondere den Körper der Funktion main. Zuerst initialisieren Sie ein VideoCapture-Objekt, das so eingestellt ist, dass es Live-Einspeisungen von der Kamera Ihres Computers erfassen kann. Platzieren Sie das ans Ende der Funktion main:
Fügen Sie dann eine while-Schleife hinzu, die bei jedem Zeitschritt von der Kamera liest:
Schreiben Sie eine Hilfsfunktion, die das zentrale Cropping für das Kamerabild übernimmt. Platzieren Sie diese Funktion vor main:
Führen Sie als Nächstes das zentrale Cropping für das Kamerabild durch, konvertieren Sie es in Graustufen, normalisieren Sie es and ändern Sie die Größe auf 28x28. Platzieren Sie dies in die while-Schleife innerhalb der Funktion main:
Führen Sie noch innerhalb der while-Schleife eine Inferenz mit der ONNX-Laufzeit aus. Konvertieren Sie die Ausgaben in einen Klassenindex und dann in einen Buchstaben:
Zeigen Sie den vorhergesagten Buchstaben innerhalb des Bildrahmens und das Bild wieder dem Benutzer an:
Fügen Sie am Ende der while-Schleife diesen Code hinzu, um zu prüfen, ob der Benutzer das Zeichen q wählt und falls das der Fall ist, beenden Sie die Anwendung. Diese Zeile hält das Programm für 1 Millisekunde an. Fügen Sie Folgendes hinzu:
Lösen Sie abschließend die Aufnahme aus und schließen Sie alle Fenster. Platzieren Sie sie außerhalb der while-Schleife, um die Funktion main zu beenden.
Überprüfen Sie nochmals, ob Ihre Datei mit dem folgenden oder diesem Repository übereinstimmt:
Schließen Sie Ihre Datei und führen Sie das Skript aus.
Sobald das Skript ausgeführt wird, wird ein Fenster mit der Live-Einspeisung der Webcam angezeigt. Der vorhergesagte Gebärdensprachenbuchstabe wird oben links angezeigt. Halten Sie die Hand hoch und machen Sie Ihre Lieblingsgebärde, um Ihren Classifier in Aktion zu sehen. Hier sind einige Beispiel-Ergebnisse, die den Buchstaben L und D zeigen.

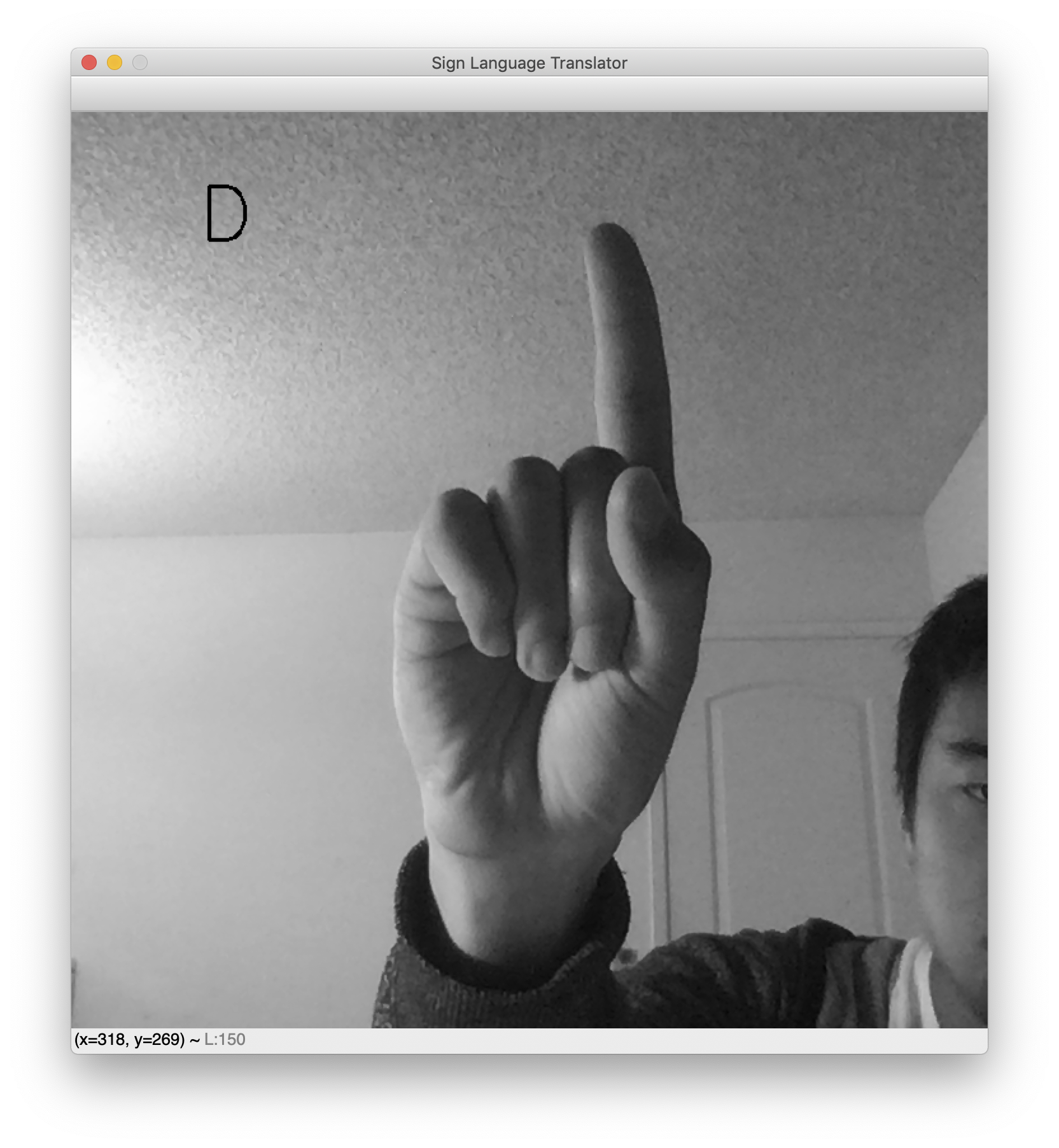
Beachten Sie während des Tests, dass der Hintergrund für diesen Übersetzer ziemlich klar sein muss, damit er funktioniert. Dies bringt die Sauberkeit des Datensatzes leider mit sich. Würde der Datensatz Bilder von Handzeichen mit verschiedenen Hintergründen enthalten, hätte das Netz kein Problem mit rauschenden Hintergründen. Der Datensatz bietet jedoch leere Hintergründe und ziemlich zentrierte Hände. Die Webcam funktioniert daher am besten, wenn die Hand ebenfalls zentriert ist und sich vor einem leeren Hintergrund befindet.
Damit ist die Übersetzungsanwendung für die Gebärdensprache vollendet.
Zusammenfassung
In diesem Tutorial haben Sie einen Übersetzer für die amerikanische Gebärdensprache mittels Computer Vision und einem Modell für maschinelles Lernen entwickelt. Sie haben vor allem neue Aspekte des Trainings eines Modells für maschinelles Lernen gesehen – genauer gesagt Data Augmentation für die Modellstabilität, Learning Rate Schedules für geringere Verluste und Exportvorgänge von KI-Modellen mithilfe von ONNX zu Produktionszwecken. Dies führte schlussendlich zu der Schaffung einer Echtzeit-Computer-Vision-Anwendung, die Gebärdensprache mithilfe einer Pipeline, die Sie erstellt haben, in Buchstaben übersetzt. Es sollte allerdings bedacht werden, dass der finale Klassifizierer instabil ist. Glücklicherweise gibt es jedoch Methoden, die man einzeln oder auch zusammen einsetzen kann, um gegen diese Instabilität vorzugehen. Diese stellen wir nachfolgend vor. Die folgenden Themen beinhalten weiterführende Erläuterungen zu Verbesserung Ihrer Anwendung:
- Generalisierung: Hierbei handelt es sich keineswegs um einen Unterbereich von Computer Vision, sondern um ein beständiges Problem, das im Grunde bei jedem Aspekt zum Thema maschinelles Lernen auftritt. Siehe Understanding Bias-Variance Tradeoffs (Das Spannungsfeld von Verzerrungsvarianzen verstehen)
- Domain Adaptation (Domänenanpassung): Angenommen, Ihr Modell ist für Domäne A trainiert (z. B. sonnige Umgebungen). Können Sie das Modell in diesem Fall auf Domäne B umstellen (z. B. wolkige Umgebungen)?
- Adversarial Examples (gegnerische Beispiele): Angenommen ein Kontrahent erstellt absichtlich Bilder, um Ihr Modell zu täuschen. Wie können Sie solche Bilder gestalten? Wie können Sie gegen solche Bilder vorgehen?
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!

Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.