By Alvin Wan and Kathryn Hancox

El autor seleccionó a Code Org para recibir una donación como parte del programa Write for DOnations.
Introducción
La visión artificial es un subcampo de la informática que pretende extraer una comprensión superior de imágenes y videos. Esto impulsa tecnologías como los filtros de videos divertidos en los chats, el autenticador facial de su dispositivo móvil y los vehículos autónomos.
En este tutorial, utilizará la visión artificial para compilar un traductor del lenguaje de señas americano para su cámara web. A medida que trabaja con el tutorial, utilizará OpenCV, una biblioteca de visión artificial, PyTorch para crear una red neuronal profunda y onnx para exportar su red neuronal. Al compilar una aplicación de visión artificial, también aplicará los siguientes conceptos:
- Seguirá el mismo método de tres pasos que se utilizó en el tutorial Cómo aplicar la visión artificial a la compilación de un filtro de emociones caninas: preprocesar una base de datos, entrenar un modelo y evaluar el modelo.
- También ampliará cada uno de estos pasos: empleará data augmentation para abordar los casos de manos no centradas o rotadas, modificar la programación de la tasa de aprendizaje para mejorar la precisión del modelo y exportar los modelos para acelerar la velocidad de inferencia.
- En el camino, también explorará los conceptos relacionados al aprendizaje automático.
Al final de este tutorial, tendrá tanto un traductor del lenguaje de señas americano como el conocimiento profundo fundamental del know-how. También puede acceder al código fuente completo de este proyecto.
Requisitos previos
Para completar este tutorial, necesitará lo siguiente:
- Un entorno de desarrollo local para Python 3 con al menos 1 GB de RAM. Puede seguir el tutorial Cómo instalar y configurar un entorno de programación local para Python 3 para configurar todo lo que necesite.
- Una cámara web funcional para detectar imágenes en tiempo real.
- (Recomendado) Compilar un filtro de emociones caninas; si bien este tutorial no se utiliza explícitamente, se refuerzan y se construye sobre esas mismas ideas.
Paso 1: Clonar el proyecto e instalar las dependencias
Vamos a crear un espacio de trabajo para este proyecto e instalaremos las dependencias que necesitaremos.
En las distribuciones de Linux, comience preparando el administrador de paquetes de su sistema e instale el paquete virtualenv de Python3. Utilice:
- apt-get update
- apt-get upgrade
- apt-get install python3-venv
Denominaremos a nuestro espacio de trabajo SignLanguage:
- mkdir ~/SignLanguage
Diríjase al directorio SignLanguage:
- cd ~/SignLanguage
Luego, cree un nuevo entorno virtual para el proyecto:
- python3 -m venv signlanguage
Active su entorno:
- source signlanguage/bin/activate
A continuación, instale PyTorch, un framework de aprendizaje profundo para Python que utilizaremos en este tutorial.
En macOS, instale Pytorch con el siguiente comando:
- python -m pip install torch==1.2.0 torchvision==0.4.0
En Linux y Windows, utilice los siguientes comandos para una compilación solo de CPU:
- pip install torch==1.2.0+cpu torchvision==0.4.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
- pip install torchvision
Ahora, instale los binarios previamente identificados para OpenCV, numpy y onnx, que son bibliotecas para visión artificial, álgebra lineal, exportación de modelos de IA y ejecución de modelos de IA, respectivamente. OpenCV ofrece utilidades como las rotaciones de imágenes y numpy ofrece utilidades de álgebra lineal, como la inversión de una matriz:
- python -m pip install opencv-python==3.4.3.18 numpy==1.14.5 onnx==1.6.0 onnxruntime==1.0.0
En las distribuciones de Linux, deberá instalar libSM.so:
- apt-get install libsm6 libxext6 libxrender-dev
Una vez instaladas las dependencias, crearemos la primera versión de nuestro traductor de lenguaje de señas: un clasificador de lenguaje de señas.
Paso 2: Preparar el conjunto de datos de clasificación del lenguaje de señas
En las siguientes tres secciones, compilará un clasificador de lenguaje de señas utilizando una red neuronal. Su objetivo es producir un modelo que acepte la imagen de una mano como entrada y devuelva una letra como resultado.
Se necesitan los tres siguientes pasos para compilar un modelo de clasificación del aprendizaje automático:
- Preprocesar la base de datos: aplique la codificación One-hot a sus etiquetas y ajuste sus datos en los tensores de PyTorch. Entrene su modelo en augmented data para prepararlo para procesar entradas “inusuales”, como una mano no centrada o rotada.
- Especificar y entrenar el modelo: configure una red neuronal con PyTorch. Definir los hiperparámetros del entrenamiento, como por cuánto tiempo entrenar, y ejecutar la pendiente de gradiente estocástica (SGD). También variará un hiperparámetro de entrenamiento específico, que es una programación de la tasa de aprendizaje. Con esto se aumentará la precisión del modelo.
- Ejecutar una predicción utilizando el modelo: evalúe la red neuronal con sus datos de validación para comprender su exactitud. Luego, exporte el modelo a un formato denominado ONNX para acelerar la velocidad de inferencia.
En esta sección del tutorial, completará el paso 1 de 3. Descargará los datos, creará un objeto Dataset para iterar sus datos, y, por último, aplicará data augmentation. Al final de este paso, tendrá un modo de programación para acceder a las imágenes y etiquetas de su conjunto de datos a fin de suministrar su modelo.
Primero, descargue el conjunto de datos a su directorio de trabajo actual:
Nota: En macOS, wget no está disponible por defecto. Para hacerlo, instale Homebrew siguiendo este tutorial de DigitalOcean. Luego, ejecute brew install wget.
- wget https://assets.digitalocean.com/articles/signlanguage_data/sign-language-mnist.tar.gz
Descomprima el archivo zip, que contiene un directorio data/:
- tar -xzf sign-language-mnist.tar.gz
Cree un archivo nuevo, llamado step_2_dataset.py:
- nano step_2_dataset.py
Tal como lo hizo antes, importe las utilidades necesarias y cree la clase que contendrá sus datos. Para el procesamiento de datos aquí, creará los conjuntos de datos de entrenamiento y prueba. Implementará la interfaz Dataset de PyTorch, lo que le permitirá cargar y utilizar el proceso de conjunto de datos integrado de PyTorch para aplicarlo a su conjunto de datos de clasificación del lenguaje de señas:
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import numpy as np
import torch
import csv
class SignLanguageMNIST(Dataset):
"""Sign Language classification dataset.
Utility for loading Sign Language dataset into PyTorch. Dataset posted on
Kaggle in 2017, by an unnamed author with username `tecperson`:
https://www.kaggle.com/datamunge/sign-language-mnist
Each sample is 1 x 1 x 28 x 28, and each label is a scalar.
"""
pass
Elimine el marcador de posición pass de la clase SignLanguageMNIST. En su lugar, agregue un método para asignar las etiquetas:
@staticmethod
def get_label_mapping():
"""
We map all labels to [0, 23]. This mapping from dataset labels [0, 23]
to letter indices [0, 25] is returned below.
"""
mapping = list(range(25))
mapping.pop(9)
return mapping
Las etiquetas varían entre 0 y 25. Sin embargo, las letras J (9) y Z (25) están excluidas. Esto significa que las etiquetas solo tienen 24 valores válidos. Para que el conjunto de todos los valores de la etiqueta a partir de 0 sea continuo, asignamos todas las etiquetas a [0, 23]. El método get_label_mapping proporciona esta asignación desde las etiquetas de conjunto de datos [0, 23] a los índices de letras [0, 25].
A continuación, agregue un método para extraer las etiquetas y las muestras de un archivo CSV. El siguiente método supone que cada línea comienza con label y, a continuación, siguen valores de 784 píxeles. Estos valores de 784 píxeles representan una imagen de 28x28:
@staticmethod
def read_label_samples_from_csv(path: str):
"""
Assumes first column in CSV is the label and subsequent 28^2 values
are image pixel values 0-255.
"""
mapping = SignLanguageMNIST.get_label_mapping()
labels, samples = [], []
with open(path) as f:
_ = next(f) # skip header
for line in csv.reader(f):
label = int(line[0])
labels.append(mapping.index(label))
samples.append(list(map(int, line[1:])))
return labels, samples
Para obtener información sobre cómo estos valores de 784 representan una imagen, consulte Cómo crear un filtro de emociones caninas, paso 4.
Tenga en cuenta que cada línea de csv.reader iterable es una lista de cadenas; las invocaciones int y map(int, ...) convierten todas las cadenas en enteros. Directamente debajo del método estático, agregue una función que inicializará nuestro marcador:
def __init__(self,
path: str="data/sign_mnist_train.csv",
mean: List[float]=[0.485],
std: List[float]=[0.229]):
"""
Args:
path: Path to `.csv` file containing `label`, `pixel0`, `pixel1`...
"""
labels, samples = SignLanguageMNIST.read_label_samples_from_csv(path)
self._samples = np.array(samples, dtype=np.uint8).reshape((-1, 28, 28, 1))
self._labels = np.array(labels, dtype=np.uint8).reshape((-1, 1))
self._mean = mean
self._std = std
Esta función comienza cargando las muestras y las etiquetas. Luego, ajusta los datos en las matrices de NumPy. En un momento explicaremos la información de la desviación estándar y media, en la sección __getitem__ que aparece a continuación.
Directamente después de la función __init__, agregue una función __len__. El objeto Dataset requiere que este método determine en qué momento se detendrá la iteración de los datos:
...
def __len__(self):
return len(self._labels)
Por último, agregue un método __getitem__, que devuelve un diccionario que contiene la muestra y la etiqueta:
def __getitem__(self, idx):
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(28, scale=(0.8, 1.2)),
transforms.ToTensor(),
transforms.Normalize(mean=self._mean, std=self._std)])
return {
'image': transform(self._samples[idx]).float(),
'label': torch.from_numpy(self._labels[idx]).float()
}
Se utiliza una técnica denominada data augmentation, que consiste en perturbar las muestras durante el entrenamiento con el fin de aumentar la solidez del modelo ante estas perturbaciones. En este caso particular, puede utilizar RandomResizedCrop para hacer un acercamiento aleatorio en la imagen con diversos niveles de zoom y en diferentes áreas. Tenga en cuenta que la clase final del lenguaje de señas no debería verse afectado por los acercamientos; de esta manera, la etiqueta no se transforma. Además, se estandarizan las entradas para que se modifique la escala de los valores de la imagen al rango ]0, 1[, en vez de [0, 255] como se esperaba; para realizar esto, utilice el conjunto de datos _mean y _std al estandarizar.
Su clase SignLanguageMNIST terminada tendrá el siguiente aspecto:
from torch.utils.data import Dataset
from torch.autograd import Variable
import torchvision.transforms as transforms
import torch.nn as nn
import numpy as np
import torch
from typing import List
import csv
class SignLanguageMNIST(Dataset):
"""Sign Language classification dataset.
Utility for loading Sign Language dataset into PyTorch. Dataset posted on
Kaggle in 2017, by an unnamed author with username `tecperson`:
https://www.kaggle.com/datamunge/sign-language-mnist
Each sample is 1 x 1 x 28 x 28, and each label is a scalar.
"""
@staticmethod
def get_label_mapping():
"""
We map all labels to [0, 23]. This mapping from dataset labels [0, 23]
to letter indices [0, 25] is returned below.
"""
mapping = list(range(25))
mapping.pop(9)
return mapping
@staticmethod
def read_label_samples_from_csv(path: str):
"""
Assumes first column in CSV is the label and subsequent 28^2 values
are image pixel values 0-255.
"""
mapping = SignLanguageMNIST.get_label_mapping()
labels, samples = [], []
with open(path) as f:
_ = next(f) # skip header
for line in csv.reader(f):
label = int(line[0])
labels.append(mapping.index(label))
samples.append(list(map(int, line[1:])))
return labels, samples
def __init__(self,
path: str="data/sign_mnist_train.csv",
mean: List[float]=[0.485],
std: List[float]=[0.229]):
"""
Args:
path: Path to `.csv` file containing `label`, `pixel0`, `pixel1`...
"""
labels, samples = SignLanguageMNIST.read_label_samples_from_csv(path)
self._samples = np.array(samples, dtype=np.uint8).reshape((-1, 28, 28, 1))
self._labels = np.array(labels, dtype=np.uint8).reshape((-1, 1))
self._mean = mean
self._std = std
def __len__(self):
return len(self._labels)
def __getitem__(self, idx):
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(28, scale=(0.8, 1.2)),
transforms.ToTensor(),
transforms.Normalize(mean=self._mean, std=self._std)])
return {
'image': transform(self._samples[idx]).float(),
'label': torch.from_numpy(self._labels[idx]).float()
}
Al igual que antes, ahora cargará el conjunto de datos SignLanguageMNIST para verificar nuestras funciones de utilidad. Agregue el siguiente código al final de su archivo, después de la clase SignLanguageMNIST:
def get_train_test_loaders(batch_size=32):
trainset = SignLanguageMNIST('data/sign_mnist_train.csv')
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
testset = SignLanguageMNIST('data/sign_mnist_test.csv')
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False)
return trainloader, testloader
Este código inicializa el conjunto de datos utilizando la clase SignLanguageMNIST. Luego, ajusta el conjunto de datos en un DataLoader para los conjuntos de entrenamiento y validación. Esto traducirá el conjunto de datos a uno iterable que utilizará más adelante.
Ahora, verificará que las utilidades del conjunto de datos funcionen. Cree un cargador de muestra de un conjunto de datos con DataLoader e imprima el primer elemento del cargador. Añada lo siguiente al final de su archivo:
if __name__ == '__main__':
loader, _ = get_train_test_loaders(2)
print(next(iter(loader)))
Puede verificar que su archivo coincida con el archivo step_2_dataset en este (repositorio). Cierre su editor y ejecute la secuencia de comandos con lo siguiente:
- python step_2_dataset.py
Como resultado se muestra el siguiente par de tensores. Nuestro proceso arroja como resultado dos muestras y dos etiquetas. Esto indica que nuestro proceso de datos está listo para comenzar:
Output{'image': tensor([[[[ 0.4337, 0.5022, 0.5707, ..., 0.9988, 0.9646, 0.9646],
[ 0.4851, 0.5536, 0.6049, ..., 1.0502, 1.0159, 0.9988],
[ 0.5364, 0.6049, 0.6392, ..., 1.0844, 1.0844, 1.0673],
...,
[-0.5253, -0.4739, -0.4054, ..., 0.9474, 1.2557, 1.2385],
[-0.3369, -0.3369, -0.3369, ..., 0.0569, 1.3584, 1.3242],
[-0.3712, -0.3369, -0.3198, ..., 0.5364, 0.5364, 1.4783]]],
[[[ 0.2111, 0.2796, 0.3481, ..., 0.2453, -0.1314, -0.2342],
[ 0.2624, 0.3309, 0.3652, ..., -0.3883, -0.0629, -0.4568],
[ 0.3309, 0.3823, 0.4337, ..., -0.4054, -0.0458, -1.0048],
...,
[ 1.3242, 1.3584, 1.3927, ..., -0.4054, -0.4568, 0.0227],
[ 1.3242, 1.3927, 1.4612, ..., -0.1657, -0.6281, -0.0287],
[ 1.3242, 1.3927, 1.4440, ..., -0.4397, -0.6452, -0.2856]]]]), 'label': tensor([[24.],
[11.]])}
Ya verificó que su proceso de datos funciona. Con esto concluye el primer paso, preprocesar sus datos, que ahora incluye data augmentation para intensificar la solidez del modelo. A continuación, definirá la red neuronal y el optimizador.
Paso 3: Compilar y entrenar el clasificador de lenguaje de señas utilizando el aprendizaje profundo
Ahora que el proceso del conjunto de datos funciona, definirá un modelo y lo entrenará para procesar los datos. En concreto, creará una red neuronal con seis capas, definirá una pérdida y un optimizador, y, por último, optimizará la función de pérdida para las predicciones de su red neuronal. Al final de este paso, tendrá un clasificador de lenguaje de señas funcional.
Cree un nuevo archivo llamado step_3_train.py:
- nano step_3_train.py
Importe las utilidades necesarias:
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
from step_2_dataset import get_train_test_loaders
Defina una red neural de PyTorch que contenga capas convolucionales, seguidas de tres capas completamente conectadas. Agréguela al final de su secuencia de comandos existente:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 24)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Ahora, agregue el siguiente código al final de la secuencia de comandos para iniciar la red neural, definir una función de pérdida y definir los hiperparámetros de optimización:
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
Por último, entrenará por dos períodos:
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
trainloader, _ = get_train_test_loaders()
for epoch in range(2): # loop over the dataset multiple times
train(net, criterion, optimizer, trainloader, epoch)
torch.save(net.state_dict(), "checkpoint.pth")
Definirá un período como una iteración de entrenamiento en la que cada muestra de entrenamiento se ha utilizado solo una vez. Al final de la función principal, los parámetros del modelo se guardarán en un archivo llamado “checkpoint.pth”.
Agregue el siguiente código al final de su secuencia de comandos para extraer image y label del cargador del conjunto de datos y, luego, ajuste cada uno a una Variable de PyTorch:
def train(net, criterion, optimizer, trainloader, epoch):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels[:, 0])
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 100 == 0:
print('[%d, %5d] loss: %.6f' % (epoch, i, running_loss / (i + 1)))
Este código también ejecutará la propagación hacia adelante y luego se propagará hacia atrás a través de la pérdida y de la red neuronal.
Al final de su archivo, agregue lo siguiente para invocar la función main:
if __name__ == '__main__':
main()
Vuelva a comprobar que su archivo coincida con lo siguiente:
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
from step_2_dataset import get_train_test_loaders
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 6, 3)
self.conv3 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 48)
self.fc3 = nn.Linear(48, 25)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
trainloader, _ = get_train_test_loaders()
for epoch in range(2): # loop over the dataset multiple times
train(net, criterion, optimizer, trainloader, epoch)
torch.save(net.state_dict(), "checkpoint.pth")
def train(net, criterion, optimizer, trainloader, epoch):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs = Variable(data['image'].float())
labels = Variable(data['label'].long())
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels[:, 0])
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 100 == 0:
print('[%d, %5d] loss: %.6f' % (epoch, i, running_loss / (i + 1)))
if __name__ == '__main__':
main()
Guarde y cierre. Luego, ejecute lo siguiente para iniciar nuestro entrenamiento de prueba de concepto:
- python step_3_train.py
Verá un resultado similar al siguiente a medida que la red neuronal entrene:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
[1, 0] loss: 0.254097
[1, 100] loss: 0.208116
[1, 200] loss: 0.196270
[1, 300] loss: 0.183676
[1, 400] loss: 0.169824
[1, 500] loss: 0.157704
[1, 600] loss: 0.151408
[1, 700] loss: 0.136470
[1, 800] loss: 0.123326
Para obtener una pérdida menor, puede aumentar el número de períodos a 5, 10 o incluso 20. Sin embargo, después de un período de tiempo de entrenamiento, la pérdida de red dejará de disminuir con el incremento del tiempo de entrenamiento. Para omitir este problema, a medida que el tiempo de entrenamiento aumente, introducirá una programación de la tasa de aprendizaje, que con el tiempo disminuye dicha tasa. Para comprender por qué funciona, consulte la visualización de Distill en “Why Momentum Really Works” (Por qué el momentum realmente funciona).
Modifique su función main con las siguientes dos líneas, en las que definirá un programador de trabajo, scheduler, e invocará scheduler.step. Además, cambie el número de periodos a 12:
def main():
net = Net().float()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
trainloader, _ = get_train_test_loaders()
for epoch in range(12): # loop over the dataset multiple times
train(net, criterion, optimizer, trainloader, epoch)
scheduler.step()
torch.save(net.state_dict(), "checkpoint.pth")
Compruebe que su archivo coincida con el archivo del paso 3 de este repositorio. El entrenamiento se ejecutará durante unos 5 minutos. El resultado será similar a lo siguiente:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
...
[11, 0] loss: 0.000302
[11, 100] loss: 0.007548
[11, 200] loss: 0.009005
[11, 300] loss: 0.008193
[11, 400] loss: 0.007694
[11, 500] loss: 0.008509
[11, 600] loss: 0.008039
[11, 700] loss: 0.007524
[11, 800] loss: 0.007608
La pérdida final que se obtiene es 0.007608, que es 3 órdenes de magnitud más pequeña que la pérdida inicial de 3.20. Con esto, concluye el segundo paso de nuestro flujo de trabajo, en el que instalamos y entrenamos la red neuronal. Dicho esto, sin importar lo pequeño que es este valor de pérdida, tiene poca relevancia. Para poner el rendimiento del modelo en perspectiva, calcularemos su precisión, es decir, el porcentaje de imágenes que el modelo clasificó de manera correcta.
Paso 4: Evaluar el clasificador de lenguaje de señas
Ahora, evaluará su clasificador de lenguaje de señas calculando su precisión con el conjunto de validación, un conjunto de imágenes que el modelo no procesó durante el entrenamiento. Esto proporcionará una mejor comprensión del rendimiento del modelo que el valor final de pérdida. Además, agregará utilidades para guardar el modelo entrenado al final del entrenamiento y cargar el modelo entrenado con anterioridad al llevar a cabo la inferencia.
Cree un archivo nuevo llamado step_4_evaluate.py.
- nano step_4_evaluate.py
Importe las utilidades necesarias:
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
import numpy as np
import onnx
import onnxruntime as ort
from step_2_dataset import get_train_test_loaders
from step_3_train import Net
Luego, defina una utilidad para evaluar el rendimiento de la red neuronal. La siguiente función compara la letra pronosticada por la red neuronal con la letra real, para una sola imagen:
def evaluate(outputs: Variable, labels: Variable) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.numpy()
Yhat = np.argmax(outputs, axis=1)
return float(np.sum(Yhat == Y))
outputs es una lista de las probabilidades de clase para cada muestra. Por ejemplo, los outputs de una sola muestra pueden ser [0.1, 0.3, 0.4, 0.2]. labels es una lista de las clases de etiquetas. Por ejemplo, la clase de etiqueta puede ser 3.
Y = ... convierte las etiquetas en una matriz de NumPy. Luego, Yhat = np.argmax(...) convierte las probabilidades de la clase de outputs en clases pronosticadas. Por ejemplo, la lista de probabilidades de clase [0.1, 0.3, 0.4, 0.2] generaría la clase pronosticada 2, debido a que el valor del índice 2 de 0.4 es el valor más alto.
Ya que ahora Y y Yhat son clases, puede compararlas. Yhat == Y comprueba si la clase pronosticada coincide con la clase de la etiqueta, y np.sum(...) es un truco que calcula el número de valores que se evalúan como verdaderos. En otras palabras, np.sum mostrará el número de muestras que se clasificaron correctamente.
Agregue la segunda función batch_evaluate, que aplica la primera función evaluate a todas las imágenes:
def batch_evaluate(
net: Net,
dataloader: torch.utils.data.DataLoader) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = n = 0.0
for batch in dataloader:
n += len(batch['image'])
outputs = net(batch['image'])
if isinstance(outputs, torch.Tensor):
outputs = outputs.detach().numpy()
score += evaluate(outputs, batch['label'][:, 0])
return score / n
batch es un grupo de imágenes almacenadas como un solo tensor. Primero, se aumenta el número total de imágenes que está por evaluar (n) por el número de imágenes en este lote. A continuación, se ejecuta la inferencia en la red neuronal con este lote de imágenes, outputs = net(...). El verificador de tipos if isinstance(...) convierte los resultados en una matriz de NumPy si es necesario. Por último, se utiliza evaluate para calcular el número de muestras que se clasificaron correctamente. Al finalizar la función, se calcula el porcentaje de muestras correctamente clasificadas, score / n.
Por último, agregue la siguiente secuencia de comandos para aprovechar las utilidades anteriores:
def validate():
trainloader, testloader = get_train_test_loaders()
net = Net().float()
pretrained_model = torch.load("checkpoint.pth")
net.load_state_dict(pretrained_model)
print('=' * 10, 'PyTorch', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
if __name__ == '__main__':
validate()
Esto carga una red neuronal previamente entrenada y evalúa su rendimiento con respecto al conjunto de datos del lenguaje de señas proporcionado. En concreto, esta secuencia de comandos muestra la precisión con respecto a las imágenes que utilizó para el entrenamiento y un conjunto de imágenes diferente que reservó para la prueba, al que denominamos conjunto de validación.
A continuación, exportará el modelo de PyTorch a uno binario de ONNX. Luego, este archivo binario se puede utilizar en producción para ejecutar la inferencia con su modelo. Más importante aún, el código que ejecuta este modelo binario no necesita una copia de la definición original de la red. Al final de la función validate, agregue lo siguiente:
trainloader, testloader = get_train_test_loaders(1)
# export to onnx
fname = "signlanguage.onnx"
dummy = torch.randn(1, 1, 28, 28)
torch.onnx.export(net, dummy, fname, input_names=['input'])
# check exported model
model = onnx.load(fname)
onnx.checker.check_model(model) # check model is well-formed
# create runnable session with exported model
ort_session = ort.InferenceSession(fname)
net = lambda inp: ort_session.run(None, {'input': inp.data.numpy()})[0]
print('=' * 10, 'ONNX', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
Esto exporta el modelo de ONNX, comprueba el modelo exportado y, luego, ejecuta la inferencia con el modelo exportado. Compruebe que su archivo coincida con el archivo del paso 4 de este repositorio:
from torch.utils.data import Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch
import numpy as np
import onnx
import onnxruntime as ort
from step_2_dataset import get_train_test_loaders
from step_3_train import Net
def evaluate(outputs: Variable, labels: Variable) -> float:
"""Evaluate neural network outputs against non-one-hotted labels."""
Y = labels.numpy()
Yhat = np.argmax(outputs, axis=1)
return float(np.sum(Yhat == Y))
def batch_evaluate(
net: Net,
dataloader: torch.utils.data.DataLoader) -> float:
"""Evaluate neural network in batches, if dataset is too large."""
score = n = 0.0
for batch in dataloader:
n += len(batch['image'])
outputs = net(batch['image'])
if isinstance(outputs, torch.Tensor):
outputs = outputs.detach().numpy()
score += evaluate(outputs, batch['label'][:, 0])
return score / n
def validate():
trainloader, testloader = get_train_test_loaders()
net = Net().float().eval()
pretrained_model = torch.load("checkpoint.pth")
net.load_state_dict(pretrained_model)
print('=' * 10, 'PyTorch', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
trainloader, testloader = get_train_test_loaders(1)
# export to onnx
fname = "signlanguage.onnx"
dummy = torch.randn(1, 1, 28, 28)
torch.onnx.export(net, dummy, fname, input_names=['input'])
# check exported model
model = onnx.load(fname)
onnx.checker.check_model(model) # check model is well-formed
# create runnable session with exported model
ort_session = ort.InferenceSession(fname)
net = lambda inp: ort_session.run(None, {'input': inp.data.numpy()})[0]
print('=' * 10, 'ONNX', '=' * 10)
train_acc = batch_evaluate(net, trainloader) * 100.
print('Training accuracy: %.1f' % train_acc)
test_acc = batch_evaluate(net, testloader) * 100.
print('Validation accuracy: %.1f' % test_acc)
if __name__ == '__main__':
validate()
Ejecute lo siguiente para utilizar y evaluar el punto de control del último paso:
- python step_4_evaluate.py
Esto generará un resultado similar al siguiente, lo cual confirma que el modelo exportado no solo funciona, sino que también concuerda con el modelo de PyTorch original:
Output========== PyTorch ==========
Training accuracy: 99.9
Validation accuracy: 97.4
========== ONNX ==========
Training accuracy: 99.9
Validation accuracy: 97.4
Su red neuronal logra una precisión de entrenamiento de 99.9% y una precisión de validación de 97.4%. Esta brecha entre el entrenamiento y la exactitud de validación indica que su modelo está sobreajustado. Esto significa que, en lugar de aprender patrones que se pueden generalizar, el modelo memorizó los datos de entrenamiento. Para comprender las implicaciones y las causas del sobreajuste, consulte Información sobre la compensación de la relación sesgo-varianza.
En este momento, hemos completado un clasificador de lenguaje de señas. Básicamente, nuestro modelo puede diferenciar las señas correctamente y sin ambigüedades, casi todo el tiempo. Este es un modelo razonablemente bueno; por lo tanto, pasaremos a la etapa final de nuestra aplicación. Utilizaremos este clasificador de lenguaje de señas en una aplicación de cámara web en tiempo real.
Paso 5: Vincular la señal de video
El siguiente objetivo es vincular la cámara de la computadora a su clasificador de lenguaje de señas. Recopilará los datos de entrada de la cámara, clasificará el lenguaje de señas mostrado e informará sobre la seña que clasificó al usuario.
Ahora, cree una secuencia de comandos de Python para el detector facial. Cree el archivo step_6_camera.py con nano o su editor de texto favorito:
- nano step_5_camera.py
Agregue el siguiente código al archivo:
"""Test for sign language classification"""
import cv2
import numpy as np
import onnxruntime as ort
def main():
pass
if __name__ == '__main__':
main()
Este código importa OpenCV, que contiene las utilidades de imagen y el tiempo de ejecución de ONNX, que es todo lo necesario para ejecutar la inferencia con su modelo. El resto del código es el típico texto estándar de programación de Python.
Ahora, sustituya pass en la función main por el siguiente código, que inicializa un clasificador de lenguaje de señas con los parámetros que entrenó previamente. También agregue una asignación desde los índices a las letras y las estadísticas de imágenes:
def main():
# constants
index_to_letter = list('ABCDEFGHIKLMNOPQRSTUVWXY')
mean = 0.485 * 255.
std = 0.229 * 255.
# create runnable session with exported model
ort_session = ort.InferenceSession("signlanguage.onnx")
Utilizará elementos de esta secuencia de comandos de prueba que se detalla en la documentación oficial de OpenCV. Específicamente, actualizará el cuerpo de la función main. Comience por iniciar un objeto de VideoCapture, que está configurado para captar la señal de video en directo desde la cámara de su equipo. Ubíquelo al final de la función main:
def main():
...
# create runnable session with exported model
ort_session = ort.InferenceSession("signlanguage.onnx")
cap = cv2.VideoCapture(0)
Luego, agregue un bucle while, que realiza una lectura desde la cámara en cada intervalo de tiempo:
def main():
...
cap = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = cap.read()
Escriba una función de utilidad que utilice el encuadre central para el marco de la cámara. Ubique esta función antes de main:
def center_crop(frame):
h, w, _ = frame.shape
start = abs(h - w) // 2
if h > w:
frame = frame[start: start + w]
else:
frame = frame[:, start: start + h]
return frame
A continuación, tome el encuadre central para el marco de la cámara, conviértalo a una escala de grises, estandarice y cambie el tamaño a 28x28. Coloque esto dentro del bucle while y dentro de la función main:
def main():
...
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# preprocess data
frame = center_crop(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
x = cv2.resize(frame, (28, 28))
x = (frame - mean) / std
Dentro del bucle while, ejecute la inferencia con el tiempo de ejecución de ONNX. Convierta los resultados a un índice de clase y, luego, a una letra:
...
x = (frame - mean) / std
x = x.reshape(1, 1, 28, 28).astype(np.float32)
y = ort_session.run(None, {'input': x})[0]
index = np.argmax(y, axis=1)
letter = index_to_letter[int(index)]
Exhiba en la pantalla la letra pronosticada dentro del marco y muéstrelo al usuario:
...
letter = index_to_letter[int(index)]
cv2.putText(frame, letter, (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (0, 255, 0), thickness=2)
cv2.imshow("Sign Language Translator", frame)
Al final del bucle while, agregue este código para verificar si el usuario presiona el carácter q y, si lo hace, cierre la aplicación. Esta línea detiene el programa por 1 milisegundo. Agregue lo siguiente:
...
cv2.imshow("Sign Language Translator", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
Por último, cierre la captura y todas las ventanas. Coloque esto fuera del bucle while para finalizar la función main.
...
while True:
...
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
Compruebe con cuidado que su archivo coincida con lo siguiente o con este repositorio:
import cv2
import numpy as np
import onnxruntime as ort
def center_crop(frame):
h, w, _ = frame.shape
start = abs(h - w) // 2
if h > w:
return frame[start: start + w]
return frame[:, start: start + h]
def main():
# constants
index_to_letter = list('ABCDEFGHIKLMNOPQRSTUVWXY')
mean = 0.485 * 255.
std = 0.229 * 255.
# create runnable session with exported model
ort_session = ort.InferenceSession("signlanguage.onnx")
cap = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = cap.read()
# preprocess data
frame = center_crop(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
x = cv2.resize(frame, (28, 28))
x = (x - mean) / std
x = x.reshape(1, 1, 28, 28).astype(np.float32)
y = ort_session.run(None, {'input': x})[0]
index = np.argmax(y, axis=1)
letter = index_to_letter[int(index)]
cv2.putText(frame, letter, (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (0, 255, 0), thickness=2)
cv2.imshow("Sign Language Translator", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
Cierre el archivo y ejecute la secuencia de comandos.
- python step_5_camera.py
Una vez que se ejecute la secuencia de comandos, aparecerá una ventana con la señal de video en directo. La letra del lenguaje de señas pronosticada se mostrará en la parte superior izquierda. Levante la mano y realice su seña favorita para ver al clasificador en acción. A continuación, puede observar algunos resultados de muestra con las letras L y D.

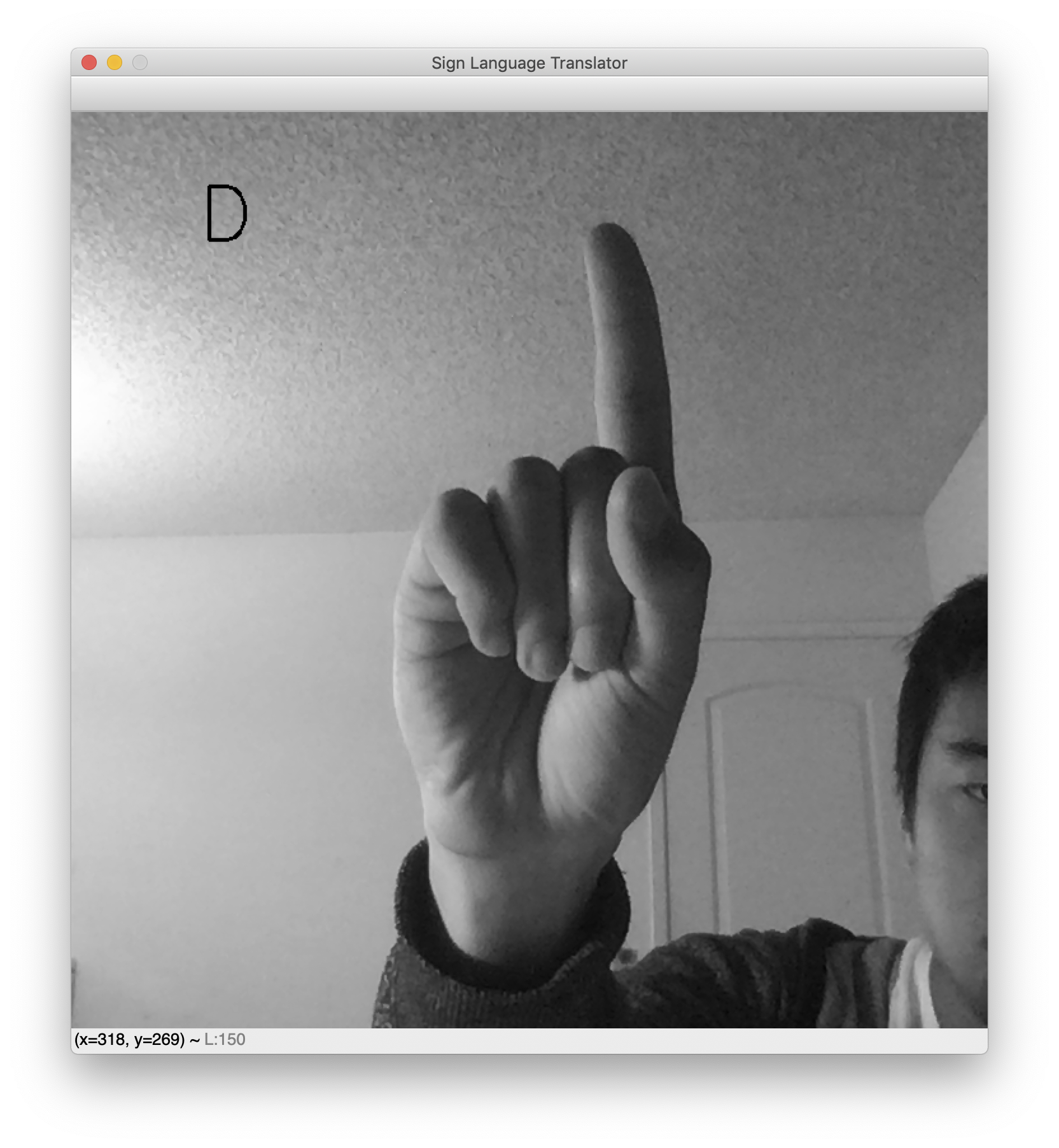
Al realizar las pruebas, observe que para que funcione el traductor, el fondo debe ser bastante claro. Esta es una consecuencia desafortunada de la pulcritud del conjunto de datos. Si el conjunto de datos hubiera incluido imágenes de señas con las manos sobre diversos fondos, la red mostraría mayor flexibilidad ante los fondos complejos. Sin embargo, el conjunto de datos presenta fondos en blanco y manos bien centradas. Como resultado, este traductor de cámara web funciona mejor cuando su mano está también centrada y contra un fondo en blanco.
Con esto, concluye la aplicación del traductor de lenguaje de señas.
Conclusión
Mediante este tutorial, construyó un traductor para el lenguaje de señas americano utilizando la visión artificial y un modelo de aprendizaje automático. En particular, exploró nuevos aspectos del entrenamiento de un modelo de aprendizaje automático; específicamente, data augmentation para lograr la solidez del modelo, programación de la tasa de aprendizaje para una menor pérdida y exportación de modelos de IA con ONNX para el uso de producción. Luego, este proceso culminó con una aplicación de visión artificial en tiempo real, que traduce el lenguaje de señas a letras mediante un proceso que usted compiló. Cabe señalar que es posible abordar la fragilidad del clasificador final con cualquiera o con todos los métodos siguientes. Para seguir explorando, profundice sobre los siguientes temas para mejorar su aplicación:
- Generalización: no se trata de un subtema de la visión artificial, sino que es un problema constante en todo el proceso de aprendizaje automático. Consulte la Información sobre la compensación de la relación sesgo-varianza.
- Adaptación del dominio: suponga que su modelo está entrenado en el dominio A (por ejemplo, entornos soleados). ¿Puede adaptar rápidamente el modelo al dominio B (por ejemplo, entornos nublados)?
- Ejemplos conflictivos: suponga que un competidor está diseñando imágenes que engañen intencionalmente a su modelo. ¿Cómo puede diseñar esas imágenes? ¿Cómo puede hacer frente a tales imágenes?
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I'm a diglot by definition, lactose intolerant by birth but an ice-cream lover at heart. Call me wabbly, witling, whatever you will, but I go by Alvin
Former Senior Technical Editor at DigitalOcean, with a strong focus on DevOps and System Administration content. Areas of expertise include Terraform, PyTorch, Python, and Django.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.