Tutorial
Comment construire un réseau neuronal pour traduire la langue des signes en anglais

L’auteur a choisi Code Org pour recevoir un don dans le cadre du programme Write for DOnations.
Introduction
La vision par ordinateur est un sous-domaine de l’informatique qui vise à extraire une compréhension supérieure des choses à partir d’images et de vidéos. On la retrouve dans les technologies comme les filtres de chat vidéo amusants, l’authentification de visage sur votre appareil mobile et les voitures autonomes.
Dans ce tutoriel, vous utiliserez la vision par ordinateur pour créer un traducteur de la langue des signes américaine pour votre webcam. Au cours de ce tutoriel, vous utiliserez OpenCV, une bibliothèque de vision par ordinateur, PyTorch pour créer un réseau neuronal profond et onnx pour exporter votre réseau neuronal. Vous appliquerez également les concepts suivants lors de la création d’une application de vision par ordinateur :
- Vous utiliserez la même méthode en trois étapes qui est utilisée dans le tutoriel Comment appliquer la vision par ordinateur pour créer un filtre pour chiens basé sur les émotions : pré-traiter un ensemble de données, former un modèle et évaluer le modèle.
- Vous allez également aller plus loin dans chacune de ces étapes : utiliser l’augmentation des données pour traiter les aiguilles tournées ou non centrées, modifier les horaires de fréquence d’apprentissage pour améliorer la précision du modèle et exporter des modèles pour une vitesse d’inférence plus rapide.
- En cours de route, vous explorerez également les concepts liés à l’apprentissage automatique.
À la fin de ce tutoriel, vous aurez à la fois un traducteur de la langue des signes américaine et le savoir-faire fondamental sur l’apprentissage profond. Vous pouvez également accéder au code source complet de ce projet.
Conditions préalables
Pour terminer ce tutoriel, vous aurez besoin des éléments suivants :
- Un environnement de développement local pour Python 3 avec au moins 1 Go de RAM. Vous pouvez consulter Comment installer et configurer un environnement de programmation local pour Python 3 pour configurer tout ce dont vous avez besoin.
- Une webcam qui fonctionne pour la détection d’images en temps réel.
- (Recommandé) Créez un filtre pour chien basé sur les émotions. On n’utilise pas explicitement ce tutoriel mais les mêmes idées y sont renforcées et développées.
Étape 1 - Création du projet et installation des dépendances
Créons un espace de travail pour ce projet et installons les dépendances dont nous aurons besoin.
Sur les distributions Linux, commencez par préparer votre gestionnaire de packages système et installez le package virtualenv de Python3. Utilisez :
Nous allons appeler notre espace de travail SignLanguage :
Naviguez jusqu’au répertoire SignLanguage :
Ensuite, créez un nouvel environnement virtuel pour le projet :
Activez votre environnement :
Installez ensuite PyTorch, un framework d’apprentissage profond pour Python que nous utiliserons au cours de ce tutoriel.
Sous macOS, installez Pytorch avec la commande suivante :
Sous Linux et Windows, utilisez les commandes suivantes pour une construction du CPU uniquement :
Installez maintenant les binaires préfilmés pour OpenCV, numpy et onnx, des bibliothèques destinée à la vision par ordinateur, l’algèbre linéaire, l’exportation de modèle AI et l’exécution de modèle AI, respectivement. OpenCV propose des utilitaires tels que les rotations d’images et numpy fournit des utilitaires d’algèbre linéaire comme l’inversion d’une matrice :
Sur les distributions Linux, vous devrez installer libSM.so :
Une fois les dépendances installées, construisons la première version de notre traducteur de la langue des signes : un système de classification de la langue des signes.
Étape 2 - Préparation de l’ensemble de données de classification de la langue des signes
Au cours des trois prochaines sections, vous allez construire un système de classification de la langue des signes à l’aide d’un réseau neuronal. Votre objectif est de produire un modèle qui accepte une image d’une main en entrée et génère une lettre.
Vous devez suivre les trois étapes suivantes pour créer un modèle de classification d’apprentissage automatique :
- Pré-traitez les données : appliquez one-hot encoding à vos étiquettes et sauvegardez vos données dans PyTorch Tensors. Entraînez votre modèle sur des données augmentées pour le préparer à une saisie “inhabituelle”, comme une main sur le côté ou tournée.
- Spécifiez et entraînez le modèle : configurez un réseau neuronal à l’aide de PyTorch. Définissez les hyper-paramètres d’entraînement (comme la durée d’entraînement) et exécutez la descente de gradient stochastique. Vous modifierez également un hyper-paramètre d’entraînement spécifique, qui correspond au calendrier de fréquence d’apprentissage. Ils optimisent la précision du modèle.
- Exécutez une prédiction à l’aide du modèle : évaluez le réseau neuronal sur vos données de validation pour comprendre sa précision. Ensuite, exportez le modèle dans un format appelé ONNX pour avoir des vitesses d’inférence plus rapides.
Dans cette section du tutoriel, vous allez effectuer l’étape 1 sur 3. Vous allez télécharger les données, créer un objet Dataset pour itérer sur vos données et enfin appliquer l’augmentation des données. À la fin de cette étape, vous aurez un moyen d’accéder par programme aux images et aux étiquettes de votre ensemble de données qui viendront alimenter votre modèle.
Tout d’abord, téléchargez l’ensemble de données dans votre répertoire de travail actuel :
Note : sous macOS, par défaut, wget n’est pas disponible. Pour qu’il le soit, installez Homebrew en suivant ce tutoriel de DigitalOcean. Ensuite, exécutez brew install wget.
Décompressez le fichier zip, qui contient un répertoire data/ :
Créez un nouveau fichier que vous nommerez step_2_dataset.py :
Comme précédemment, importez les utilitaires nécessaires et créez la classe qui contiendra vos données. Ici, pour le traitement des données, vous allez créer des ensembles de données d’entraînement et de test. Vous allez implémenter l’interface de Dataset de PyTorch, qui vous permettra de charger et d’utiliser le pipeline de données intégré de PyTorch pour votre ensemble de données de classification de la langue des signes :
Supprimez l’espace réservé pass dans la catégorie SignLanguageMNIST. À sa place, ajoutez une méthode pour générer un mappage d’étiquette :
Les étiquettes vont de 0 à 25. Cependant, les lettres J (9) et Z (25) sont exclues. Cela signifie qu’il n’existe que 24 valeurs d’étiquette valables. Pour que l’ensemble de toutes les valeurs d’étiquette à partir de 0 soit contigu, nous mappons toutes les étiquettes de [0 à 23]. Ce mappage des étiquettes de [0 à 23] et des indices de lettre de [0 à 25] de l’ensemble de données est fourni par cette méthode get_label_mapping.
Ensuite, ajoutez une méthode pour extraire les étiquettes et les échantillons d’un fichier CSV. Ce qui suit suppose que chaque ligne commence par l’étiquette, ensuite suivie des valeurs 784 pixels. Ces valeurs 784 pixels représentent une image 28x28 :
Pour avoir une explication sur la façon dont ces 784 valeurs représentent une image, voir Créer un filtre pour chien basé sur les émotions, étape 4.
Notez que chaque ligne de l’itérable csv.reader est une liste de chaînes. Les invocations int et map (int, ...) transforment toutes les chaînes en entiers. Juste en dessous de notre méthode statique, ajoutez une fonction qui initialisera notre support de données :
Cette fonction commence par charger les échantillons et les étiquettes. Ensuite, elle sauvegarde les données dans des tableaux NumPy. Les informations sur l’écart moyen et l’écart-type seront expliquées sous peu, dans la section __getitem__ suivante.
Juste après la fonction __init__, ajoutez une fonction __len__ Le Dataset requiert cette méthode pour déterminer à quel moment arrêter l’itération sur les données :
Enfin, ajoutez une méthode __getitem__, qui renvoie un dictionnaire qui contient l’échantillon et l’étiquette :
Vous utilisez la technique que l’on appelle data augmentation, dans laquelle les échantillons sont perturbés pendant l’entraînement, pour augmenter la robustesse du modèle face à ces perturbations. En particulier, zoomez de façon aléatoire sur l’image en variant les quantités et sur différents emplacements, via RandomResizedCrop. Notez que le zoom avant ne devrait pas affecter la catégorie finale de la langue des signes. Ainsi, l’étiquette n’est pas transformée. Vous normalisez encore plus les entrées de sorte que les valeurs d’image soient remises à l’échelle dans la plage [0 à 1] dans les valeurs attendues, au lieu de [0 à 25]5. Pour ce faire, utilisez l’ensemble de données _mean et _std lors de la normalisation.
La catégorie SignLanguageMNIST que vous venez de terminer ressemblera à ce qui suit :
Comme précédemment, vous allez maintenant vérifier les fonctions de notre utilitaire d’ensemble de données en chargeant l’ensemble de données SignLanguageMNIST. Ajoutez le code suivant à la fin de votre fichier après la catégorie SignLanguageMNIST :
Ce code initialise l’ensemble de données avec la catégorie SignLanguageMNIST. Ensuite, pour les ensembles d’entraînement et de validation, il sauvegarde l’ensemble de données dans un DataLoader. Cela traduira l’ensemble de données en un itérable à utiliser plus tard.
Vous allez maintenant vérifier que les utilitaires d’ensemble de données fonctionnent bien. Créez un exemple de chargeur de jeu de données à l’aide DataLoader et imprimez le premier élément de ce chargeur. Ajoutez ce qui suit à la fin de votre fichier :
Vous pouvez vérifier si votre fichier correspond au fichier step_2_dataset dans ce (référentiel). Quittez votre éditeur et exécutez le script avec les éléments suivants :
Cela génère la paire de vecteurs contravariants suivante. Notre pipeline de données génère deux échantillons et deux étiquettes. Cela indique que notre pipeline de données est opérationnel et prêt à être utilisé :
Output{'image': tensor([[[[ 0.4337, 0.5022, 0.5707, ..., 0.9988, 0.9646, 0.9646],
[ 0.4851, 0.5536, 0.6049, ..., 1.0502, 1.0159, 0.9988],
[ 0.5364, 0.6049, 0.6392, ..., 1.0844, 1.0844, 1.0673],
...,
[-0.5253, -0.4739, -0.4054, ..., 0.9474, 1.2557, 1.2385],
[-0.3369, -0.3369, -0.3369, ..., 0.0569, 1.3584, 1.3242],
[-0.3712, -0.3369, -0.3198, ..., 0.5364, 0.5364, 1.4783]]],
[[[ 0.2111, 0.2796, 0.3481, ..., 0.2453, -0.1314, -0.2342],
[ 0.2624, 0.3309, 0.3652, ..., -0.3883, -0.0629, -0.4568],
[ 0.3309, 0.3823, 0.4337, ..., -0.4054, -0.0458, -1.0048],
...,
[ 1.3242, 1.3584, 1.3927, ..., -0.4054, -0.4568, 0.0227],
[ 1.3242, 1.3927, 1.4612, ..., -0.1657, -0.6281, -0.0287],
[ 1.3242, 1.3927, 1.4440, ..., -0.4397, -0.6452, -0.2856]]]]), 'label': tensor([[24.],
[11.]])}
Vous avez maintenant vérifié si votre pipeline de données fonctionne bien. Ceci conclut la première étape, le prétraitement de vos données, qui comprend désormais une augmentation des données pour un module plus robuste. Vous allez ensuite définir le réseau neuronal et l’optimiseur.
Étape 3 - Création et formation du un système de classification de la langue des signes à l’aide de l’apprentissage profond
Maintenant que vous avez un pipeline de données fonctionnel, vous allez définir un modèle et le former sur les données. Vous allez tout particulièrement construire un réseau neuronal à six couches, définir une perte, un optimiseur et enfin optimiser la fonction de perte pour les prédictions de votre réseau neuronal. À la fin de cette étape, vous disposerez d’un système de classification de la langue des signes fonctionnel.
Créez un nouveau fichier appelé step_3_train.py :
Importez les utilitaires dont vous avez besoin :
Définissez un réseau neuronal PyTorch comprenant trois couches convolutives, suivies de trois couches entièrement connectées. Ajoutez ce qui suit à la fin de votre script existant :
Maintenant, initialisez le réseau neuronal, définissez une fonction de perte et configurez les hyperparamètres d’optimisation en ajoutant le code suivant à la fin du script :
Enfin, vous vous entraînerez sur deux epochs :
Vous configurez une epoch comme une itération de l’entraînement au cours de laquelle chaque échantillon d’entraînement a été utilisé exactement une fois. À la fin de la fonction principale, les paramètres du modèle seront enregistrés dans un fichier nommé "checkpoint.pth".
Ajoutez le code suivant à la fin de votre script pour extraire l’image et l'étiquette du chargeur d’ensemble de données, puis sauvegardez-les tous dans une variable PyTorch :
Ce code exécutera également la passe avant, puis la rétropropagera à travers le réseau de perte et neuronal.
À la fin de votre fichier, ajoutez ce qui suit pour appeler la fonction main :
Vérifiez que les éléments de votre fichier correspondent à ce qui suit :
Sauvegardez et fermez. Ensuite, lancez notre entraînement de validation de concept en exécutant :
Lorsque votre réseau neuronal s’entraîne, vous aurez un résultat semblable à ce qui suit :
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
[1, 0] loss: 0.254097
[1, 100] loss: 0.208116
[1, 200] loss: 0.196270
[1, 300] loss: 0.183676
[1, 400] loss: 0.169824
[1, 500] loss: 0.157704
[1, 600] loss: 0.151408
[1, 700] loss: 0.136470
[1, 800] loss: 0.123326
Pour obtenir une perte plus faible, vous pouvez augmenter le nombre d’époques de 5 à 10 ou même 20. Cependant, après une certaine période d’entraînement, la perte de réseau ne pourra plus diminuer avec l’augmentation du temps d’entraînement. Pour contourner ce problème, à mesure que le temps d’entraînement augmente, vous introduirez un calendrier de taux d’apprentissage, qui viendra faire baisser le taux d’apprentissage au fil du temps. Pour comprendre pourquoi cela fonctionne, voir la présentation de Distill “Pourquoi Momentum fonctionne réellement”
Modifiez votre fonction main avec les deux lignes suivantes, configurant un scheduler et invoquant scheduler.step. De plus, configurez le nombre d’époques sur 12 :
Vérifiez que votre fichier correspond au fichier de l’étape 3 dans ce référentiel. L’entraînement durera environ 5 minutes. Votre résultat ressemblera à ce qui suit:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
...
[11, 0] loss: 0.000302
[11, 100] loss: 0.007548
[11, 200] loss: 0.009005
[11, 300] loss: 0.008193
[11, 400] loss: 0.007694
[11, 500] loss: 0.008509
[11, 600] loss: 0.008039
[11, 700] loss: 0.007524
[11, 800] loss: 0.007608
La perte finale obtenue est de 0.007608, soit 3 ordres de grandeur plus petite que la perte de départ de 3.20. Ceci conclut la deuxième étape de notre flux de travail, au cours duquel nous configurons et entraînons le réseau neuronal. Cela dit, aussi petite que soit cette valeur de perte, elle n’a que peu de sens. Pour mettre les performances du modèle en perspective, nous calculerons sa précision, c’est à dire le pourcentage d’images correctement classées par le modèle.
Étape 4 - Évaluation du système de classification de la langue des signes
Vous allez maintenant évaluer votre système de classification de la langue des signes en calculant sa précision sur le validation set, un ensemble d’images que le modèle n’a pas vu pendant l’entraînement. Cela vous donnera une meilleure idée des performances du modèle que la valeur de perte finale. De plus, vous ajouterez des utilitaires pour enregistrer notre modèle entraîné à la fin de l’entraînement et charger notre modèle pré-formé lors de l’inférence.
Créez un nouveau fichier que vous appellerez step_4_evaluate.py.
Importez les utilitaires dont vous avez besoin :
Ensuite, configurer un utilitaire pour évaluer les performances du réseau neuronal. La fonction suivante compare la lettre prédite par le réseau neuronal avec la vraie lettre, pour une seule image :
outputs liste les catégories probables pour chaque échantillon. Par exemple, les outputs pour un seul échantillon peuvent être [0.1, 0.3, 0.4, 0.2]. labels est une liste de catégories d’étiquettes. Par exemple, la catégorie d’étiquette peut être 3.
Y = ... convertit les étiquettes en un tableau NumPy. Ensuite, Yhat = np.argmax (...) convertit les catégories probables des outputs en prédictions de catégories. Par exemple, la liste de catégories probables [0.1, 0.3, 0.4, 0.2] donnerait la prédiction de catégorie 2 prédite, car la valeur d’indice 2 de 0,4 est la plus grande valeur.
Maintenant que Y et Yhat sont des catégories, vous pouvez les comparer. Yhat == Y vérifie si la prédiction de catégorie correspond à la catégorie d’étiquette, et np.sum (...) est une astuce qui calcule le nombre de valeurs de truth-y. En d’autres termes, np.sum affichera le nombre d’échantillons correctement classés.
Ajoutez la deuxième fonction batch_evaluate, qui applique la première fonction evaluate à toutes les images :
batch est un groupe d’images stockées comme un seul vecteur contravariant. Tout d’abord, vous devez augmenter le nombre total d’images à évaluer (n) en fonction du nombre d’images de ce lot. Ensuite, exécutez l’inférence sur le réseau neuronal avec ce lot d’images, outputs = net(...). La vérification type if isinstance (...) convertit les sorties dans un tableau NumPy au besoin. Enfin, utilisez evaluate pour calculer le nombre d’échantillons correctement classés. À la fin de la fonction, vous calculez le pourcentage d’échantillons que vous avez correctement classés, score / n.
Enfin, ajoutez le script suivant pour tirer parti des utilitaires précédents :
Cela charge un réseau neuronal pré-entraîné et évalue ses performances sur l’ensemble de données en langue des signes fourni. Plus précisément, le script donne ici une précision sur les images que vous avez utilisées pour la formation et un ensemble distinct d’images que vous mettez de côté à des fins de test, appelé validation set.
Vous allez ensuite exporter le modèle PyTorch vers un fichier binaire ONNX. Ce fichier binaire peut ensuite être utilisé en production pour exécuter l’inférence avec votre modèle. Plus important encore, le code exécutant ce binaire n’a pas besoin d’une copie de la configuration du réseau d’origine. À la fin de la fonction de valide, ajoutez ce qui suit :
Cela exporte le modèle ONNX, vérifie le modèle exporté, puis exécute l’inférence avec le modèle exporté. Vérifiez que votre fichier correspond au fichier de l’étape 4 dans ce référentiel :
Pour utiliser et évaluer le point de contrôle de la dernière étape, exécutez ce qui suit :
Cela générera une sortie similaire à la suivante, affirmant que votre modèle exporté non seulement fonctionne, mais le fait également en accord avec votre modèle PyTorch d’origine :
Output========== PyTorch ==========
Training accuracy: 99.9
Validation accuracy: 97.4
========== ONNX ==========
Training accuracy: 99.9
Validation accuracy: 97.4
Votre réseau neuronal atteint une précision d’entraînement de 99,9 % et une précision de validation de 97,4 %. Cet écart entre la précision d’entraînement et de la validation indique que votre modèle souffre d’un ajustement excessif. Cela signifie qu’au lieu d’apprendre des modèles généralisables, votre modèle a mémorisé les données d’entraînement. Pour comprendre les implications et les causes du sur-ajustement, consultez Comprendre les compromis entre le biais et la variance.
À ce stade, nous avons terminé de concevoir un système de classification de la langue des signes En substance, notre modèle peut correctement lever une ambiguïté entre les signes presque tout le temps. Nous avons un modèle plutôt acceptable, nous pouvons donc passer à l’étape finale de notre application. Nous utiliserons ce système de classification de la langue des signes dans une application webcam en temps réel.
Étape 5 - Liaison du flux de la caméra
Votre prochain objectif est de relier l’appareil photo de l’ordinateur à votre système de classification de la langue des signes. Vous allez collecter les entrées de la caméra, classer la langue des signes affichée, puis signaler le signe classifié à l’utilisateur.
Créez maintenant un script Python pour le détecteur de visages. Créez le fichier step_6_camera.py en utilisant nano ou votre éditeur de texte favori :
Ajoutez le code suivant dans le fichier :
Ce code importe OpenCV, qui contient vos utilitaires d’image, et le runtime ONNX, tout ce dont vous avez besoin pour exécuter l’inférence avec votre modèle. Le reste du code est un texte standard type du programme Python.
Remplacez maintenant pass dans la fonction main par le code suivant, qui initialise un système de classification de la langue des signes en utilisant les paramètres que vous avez précédemment entraînés. Ajoutez également un mappage des index aux lettres et aux statistiques d’images :
Vous utiliserez des éléments de ce test script de la documentation officielle d’OpenCV. Plus précisément, vous mettrez à jour le corps de la fonction main. Commencez par initialiser un objet VideoCapture configuré pour capturer le flux en direct à partir de la caméra de votre ordinateur. Placez-le à la fin de la fonction main :
Ajoutez ensuite une boucle while pour que la lecture se fasse à partir de la caméra à chaque intervalle de temps :
Écrivez une fonction utilitaire qui prend le recadrage central comme cadre de caméra. Placez cette fonction avant main :
Ensuite, prenez le recadrage central comme cadre de la caméra, convertissez-le en niveaux de gris, normalisez -le et redimensionnez-le en 28x28. Placez-le dans la boucle while de la fonction main :
Toujours dans la boucle while, exécutez l’inférence avec le runtime ONNX. Convertissez les sorties en un index de catégorie, puis en une lettre :
Affichez la lettre prédite à l’intérieur du cadre et affichez le cadre à l’utilisateur :
À la fin de la boucle while, ajoutez ce code pour vérifier si lorsque l’utilisateur frappe le caractère q il quitte bien l’application. Cette ligne arrête le programme pendant 1 milliseconde. Ajoutez ce qui suit :
Enfin, relâchez la capture et fermez toutes les fenêtres. Placez-la en dehors de la boucle while pour terminer la fonction main.
Vérifiez que votre fichier correspond à ce qui suit ou à ce référentiel :
Quittez votre fichier et exécutez le script.
Une fois le script exécuté, une fenêtre apparaîtra avec votre flux de webcam en direct. La lettre de la langue des signes prédite s’affichera en haut à gauche. Levez la main et faites votre signe favori pour voir votre classeur en action. Voici quelques exemples de résultats avec la lettre L et D.

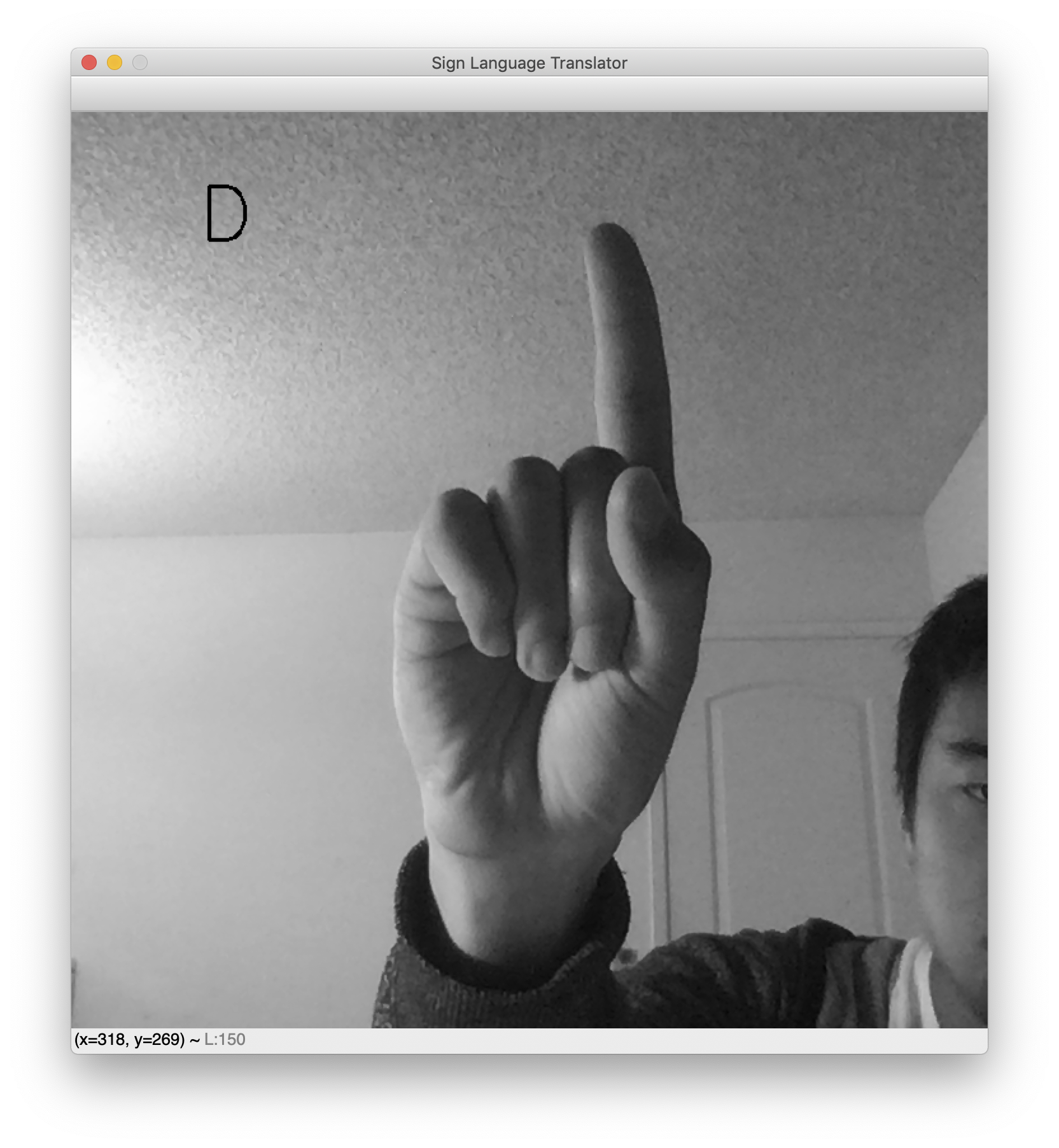
Lorsque vous réalisez les tests, notez que l’arrière-plan doit être assez clair pour que ce traducteur fonctionne. C’est une conséquence malheureuse de la propreté de l’ensemble de données. Si l’ensemble de données comprenait des images de signes de la main avec des arrière-plans divers, le réseau pourrait résister aux arrière-plans bruyants. Cependant, dans cet ensemble de données, les arrière-plans sont vierges et les mains bien centrées. Par conséquent, ce traducteur de webcam fonctionne mieux lorsque vous centrez votre main et la placez sur un fond vierge.
Ceci conclut l’application du traducteur de la langue des signes.
Conclusion
Dans ce tutoriel, vous avez créé un traducteur de la langue des signes américaine à l’aide de la vision par ordinateur et d’un modèle d’apprentissage automatique. Vous avez tout particulièrement abordé de nouveaux aspects de l’entraînement d’un modèle d’apprentissage automatique, notamment l’augmentation des données pour veiller à la robustesse du modèle, les calendriers de fréquence d’apprentissage pour réduire les pertes et l’exportation de modèles d’IA à l’aide d’ONNX pour la production. Vous avez ensuite obtenu une application de vision par ordinateur en temps réel, qui traduit le langage des signes en lettres à l’aide d’un pipeline que vous avez créé. Il convient de noter vous pouvez lutter contre la fragilité du classificateur final en utilisant l’une des méthodes suivantes (ou l’ensemble d’entre elles). Pour explorer le sujet plus profondément, essayez les rubriques suivantes pour améliorer votre application :
- Généralisation : il ne s’agit d’un sous-thème de la vision par ordinateur, mais plutôt d’un problème constant tout au long de l’apprentissage automatique. Voir Comprendre les compromis entre le biais et la variance.
- Adaptation du domaine : supposons que votre modèle soit formé dans le domaine A (par exemple, des environnements ensoleillés). Pouvez-vous rapidement adapter le modèle au domaine B (par exemple, des environnements nuageux) ?
- Exemples contradictoires : Supposons qu’un adversaire conçoit intentionnellement des images pour tromper votre modèle. Comment pouvez-vous concevoir de telles images ? Que pouvez-vous faire pour combattre de telles images ?
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!

Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.