Tutorial
Como construir uma rede neural para traduzir linguagem de sinais para o inglês

O autor selecionou a Code Org para receber uma doação como parte do programa Write for DOnations.
Introdução
Visão computacional é um subcampo da ciência da computação que visa extrair um entendimento de ordem superior de imagens e vídeos. Isso possibilita tecnologias como filtros divertidos de bate-papo por vídeo, autenticador facial do seu dispositivo móvel, e carros autônomos.
Neste tutorial, você utilizará a visão computacional para construir um tradutor da Linguagem Americana de Sinais para sua webcam. Ao trabalhar ao longo do tutorial, você usará o OpenCV, uma biblioteca de visão computacional, o PyTorch para construir uma rede neural profunda e o onnx para exportar sua rede neural. Você também aplicará os seguintes conceitos ao construir uma aplicação de visão computacional:
- Você usará o mesmo método de três passos conforme utilizado no tutorial How To Apply Computer Vision to Build an Emotion-Based Dog Filter: pré-processar um dataset, treinar um modelo e avaliar o modelo.
- Você também expandirá cada um desses passos: empregar aumento de dados para o tratamento de mãos rotacionadas ou não centralizadas, alterar as programações das taxas de aprendizagem para melhorar a precisão do modelo, e exportar modelos para maior velocidade de inferência.
- Ao longo do caminho, você também explorará conceitos relacionados ao aprendizado de máquina.
Ao final deste tutorial, você terá tanto um tradutor da Linguagem Americana de Sinais quanto um conhecimento básico de deep learning (aprendizado profundo). Você também pode acessar o código-fonte completo para este projeto.
Pré-requisitos
Para concluir este tutorial, você precisará do seguinte:
- Um ambiente de desenvolvimento local para o Python 3 com pelo menos 1GB de RAM. Você pode seguir o tutorial How to Install and Set Up a Local Programming Environment for Python 3 para configurar tudo o que você precisa.
- Uma webcam funcionando para fazer a detecção de imagem em tempo real.
- (Recomendado) Build an Emotion-Based Dog Filter: este tutorial não é utilizado explicitamente, mas as mesmas ideias são reforçadas e construídas com base nele.
Passo 1 — Criando o projeto e instalando as dependências
Vamos criar um espaço de trabalho para este projeto e instalar as dependências que precisaremos.
Em distribuições Linux, comece preparando seu gerenciador de pacotes do sistema e instale o pacote virtualenv do Python3. Use:
Vamos chamar nosso espaço de trabalho de SignLanguage:
Vá até o diretório SignLanguage:
A seguir, crie um novo ambiente virtual para o projeto:
Ative seu ambiente:
Em seguida, instale o PyTorch, um framework de deep-learning para Python que usaremos neste tutorial.
No macOS, instale o Pytorch com o seguinte comando:
No Linux e Windows, utilize os seguintes comandos para uma compilação CPU-only:
Agora, instale os binários pré-compilados para o OpenCV, numpy, e onnx, que são bibliotecas para visão computacional, álgebra linear, exportação do modelo de IA, e execução do modelo de IA, respectivamente. O OpenCV oferece utilitários como rotações de imagem, e o numpy oferece utilitários de álgebra linear, como inversão de matriz:
Em distribuições Linux, você precisará instalar a libSM.so:
Com as dependências instaladas, vamos construir a primeira versão do nosso tradutor de linguagem de sinais: um classificador de linguagem de sinais.
Passo 2 — Preparando o dataset de classificação de linguagem de sinais
Nestas três seções seguintes, você construirá um classificador de linguagem de sinais usando uma rede neural. Seu objetivo é gerar um modelo que aceita uma imagem de uma mão como entrada e retorna uma letra.como saída:
Os três passos seguintes são necessários para construir um modelo de classificação de aprendizagem de máquina:
- Pré-processar os dados: aplique uma codificação one-hot aos seus rótulos e agrupe seus dados nos Tensores do PyTorch. Treinar seu modelo em dados aumentados para prepará-lo para uma entrada “não usual”, como uma mão descentralizada ou rotacionada.
- Especificar e treinar o modelo: defina uma rede neural usando o PyTorch. Defina os hiperparâmetros de treinamento — como quanto tempo de treinamento — e execute um gradiente estocástico descendente. Você também variará um hiperparâmetro específico de treinamento, que é a programação da taxa de aprendizagem. Isso aumentará a precisão do modelo.
- Execute uma previsão usando o modelo: avalie a rede neural nos seus dados de validação para entender sua precisão. A seguir, exporte o modelo para um formato chamado ONNX para maiores velocidades de inferência.
Nesta seção do tutorial, você cumprirá o passo 1 de 3. Você baixará os dados, criará um objeto Dataset para iterar através dos seus dados, e, finalmente, aplicará o aumento de dados. Ao final deste passo, você terá uma maneira programática de acessar imagens e rótulos em seu dataset para alimentar seu modelo.
Primeiro, baixe o dataset para seu diretório de trabalho atual:
Nota: no macOS, o wget não está disponível por padrão. Para fazer isso, instale o Homebrew seguindo este tutorial da DigitalOcean. A seguir, execute brew install wget.
Descompacte o arquivo zip, que contém um diretório data/:
Crie um novo arquivo, chamado step_2_dataset.py:
Como antes, importe os utilitários necessários e crie a classe que conterá seus dados. Para o processamento de dados aqui, você criará os datasets de treinamento e de teste. Você implementará a interface Dataset do PyTorch, permitindo que você carregue e utilize o pipeline de dados embutido do PyTorch para seu dataset de classificação de linguagem de sinais:
Exclua o placeholder pass na classe SignLanguageMNIST. No seu lugar, adicione um método para gerar um mapeamento de rótulos:
Os rótulos variam de 0 a 25. No entanto, as letras J (9) e Z (25) são excluídas. Isso significa que existem apenas 24 valores de rótulo válidos. Para que o conjunto de todos os valores de rótulo a partir de 0 seja contíguo, mapeamos todos os rótulos para [0, 23]. Este mapeamento entre rótulos de dataset [0, 23] para índices de letra [0, 25] é fornecido pelo método get_label_mapping.
A seguir, adicione um método para extrair rótulos e amostras de um arquivo CSV. O seguinte pressupõe que cada linha começa com o label e que então é seguido por 784 valores de pixel. Esses 784 valores de pixel representam uma imagem 28x28:
Para uma explicação de como esses 784 valores representam uma imagem, consulte o Passo 4 do tutorial Build an Emotion-Based Dog Filter
Observe que cada linha no csv.reader iterável é uma lista de strings: as invocações int e map(int ...) convertem todas as strings para inteiros. Diretamente abaixo do nosso método estático, adicione uma função que inicializará nosso armazenador de dados:
Essa função começa carregando as amostras e rótulos. A seguir, agrupa os dados em matrizes do NumPy. As informações de média e desvio padrão serão explicadas em breve, na seção __getitem__ a seguir.
Diretamente após a função __init__, adicione uma função __len__. O Dataset requer este método para determinar quando parar de iterar os dados:
Por fim, adicione um método __getitem__, que retorna um dicionário com a amostra e o rótulo:
Use uma técnica chamada de aumento de dados, onde amostras são perturbadas durante o treinamento, para aumentar a robustez do modelo a essas perturbações. Em particular, faça um zoom aleatório na imagem variando quantidades e em diferentes localizações, através do RandomResizedCrop. Observe que o zoom não deve afetar a classe final da linguagem de sinais; assim, o rótulo não é transformado. Além disso, você normaliza as entradas para que os valores da imagem sejam redimensionados para o intervalo de [0, 1] na expectativa, em vez de [0, 255]; para conseguir isso, utilize o dataset _mean e _std ao normalizar.
Sua classe SignLanguageMNIST completa se parecerá com a seguinte:
Como antes, você agora verificará nossas funções utilitárias de dataset carregando o dataset SignLanguageMNIST. Adicione o código a seguir ao final do seu arquivo após a classe SignLanguageMNIST:
Este código inicializa o dataset usando a classe SignLanguageMNIST. A seguir, para os datasets de treinamento e de validação, ele agrupa o dataset em um DataLoader. Isso traduzirá o dataset para um iterável para ser usado mais tarde.
Agora, você verificará se os utilitários de dataset estão funcionando. Crie um dataset de amostra usando o DataLoader e imprima o primeiro elemento desse carregador. Adicione o seguinte ao final do seu arquivo:
Você pode verificar se seu arquivo corresponde ao arquivo step_2_dataset neste (repositório). Saia do seu editor e execute o script com o seguinte:
Isso resulta no seguinte par de tensores. Nosso pipeline de dados fornece duas amostras e dois rótulos. Isso indica que nosso pipeline de dados está funcionando e pronto para uso:
Output{'image': tensor([[[[ 0.4337, 0.5022, 0.5707, ..., 0.9988, 0.9646, 0.9646],
[ 0.4851, 0.5536, 0.6049, ..., 1.0502, 1.0159, 0.9988],
[ 0.5364, 0.6049, 0.6392, ..., 1.0844, 1.0844, 1.0673],
...,
[-0.5253, -0.4739, -0.4054, ..., 0.9474, 1.2557, 1.2385],
[-0.3369, -0.3369, -0.3369, ..., 0.0569, 1.3584, 1.3242],
[-0.3712, -0.3369, -0.3198, ..., 0.5364, 0.5364, 1.4783]]],
[[[ 0.2111, 0.2796, 0.3481, ..., 0.2453, -0.1314, -0.2342],
[ 0.2624, 0.3309, 0.3652, ..., -0.3883, -0.0629, -0.4568],
[ 0.3309, 0.3823, 0.4337, ..., -0.4054, -0.0458, -1.0048],
...,
[ 1.3242, 1.3584, 1.3927, ..., -0.4054, -0.4568, 0.0227],
[ 1.3242, 1.3927, 1.4612, ..., -0.1657, -0.6281, -0.0287],
[ 1.3242, 1.3927, 1.4440, ..., -0.4397, -0.6452, -0.2856]]]]), 'label': tensor([[24.],
[11.]])}
Você verificou agora que seu pipeline de dados funciona. Isso conclui o primeiro passo — pré-processando seus dados — que agora inclui aumento de dados para maior robustez do modelo. A seguir, você definirá a rede neural e o otimizador.
Passo 3 — Construindo e treinando o classificador de linguagem de sinais usando Deep Learning
Com um pipeline de dados funcionando, você agora definirá um modelo e o treinará nos dados. Em particular, você construirá uma rede neural com seis camadas, definirá uma perda, um otimizador e, por fim, otimizará a função de perdas para as previsões da sua rede neural. Ao final deste passo, você terá um classificador de linguagem de sinais funcionando.
Crie um novo arquivo chamado step_3_train.py:
Importe os utilitários necessários:
Defina uma rede neural PyTorch que inclua três camadas convolucionais, seguidas de três camadas totalmente conectadas. Adicione isto ao final do seu script existente:
Agora, inicialize a rede neural, defina uma função de perdas e defina hiperparâmetros de otimização, adicionando o código a seguir ao final do script:
Por fim, você treinará para dois epochs:
Você define um epoch para ser uma iteração de treinamento onde cada amostra de treinamento foi usada exatamente uma vez. No final da função main, os parâmetros do modelo serão salvos em um arquivo chamado "checkpoint.pth".
Adicione o código a seguir ao final do seu script para extrair image e label do dataset loader e, em seguida, agrupe cada um em uma Variable PyTorch:
Esse código também executará a passagem para frente e depois retropropagará pela perda e pela rede neural
No final do seu arquivo, adicione o seguinte para invocar a função main:
Verifique novamente se o arquivo corresponde ao seguinte:
Salve e saia. A seguir, inicie nosso treinamento de prova de conceito executando:
Você verá uma saída semelhante à seguinte à medida que a rede neural treina:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
[1, 0] loss: 0.254097
[1, 100] loss: 0.208116
[1, 200] loss: 0.196270
[1, 300] loss: 0.183676
[1, 400] loss: 0.169824
[1, 500] loss: 0.157704
[1, 600] loss: 0.151408
[1, 700] loss: 0.136470
[1, 800] loss: 0.123326
Para uma menor perda, aumente o número de epochs para 5, 10, ou até 20. No entanto, após um determinado período de treinamento, a perda de rede deixará de diminuir com o aumento do tempo de treinamento. Para contornar esse problema, à medida que o tempo de treinamento aumenta, você introduzirá uma programação de taxa de aprendizagem, que diminui a taxa de aprendizagem ao longo do tempo. Para entender porque isso funciona, consulte a visualização de Distill em “Why Momentum Really Works”.
Atualize sua função main com as seguintes duas linhas, definindo um agendador e invocando scheduler.step. Além disso, altere o número de epochs para 12:
Verifique se seu arquivo corresponde ao arquivo do passo 3 neste repositório. O treinamento será executado por cerca de 5 minutos. Sua saída se parecerá com o seguinte:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
...
[11, 0] loss: 0.000302
[11, 100] loss: 0.007548
[11, 200] loss: 0.009005
[11, 300] loss: 0.008193
[11, 400] loss: 0.007694
[11, 500] loss: 0.008509
[11, 600] loss: 0.008039
[11, 700] loss: 0.007524
[11, 800] loss: 0.007608
A perda final obtida é 0,007608, que é 3 ordens de grandeza menor que a perda inicial 3.20. Isso conclui o segundo passo do nosso fluxo de trabalho, onde configuramos e treinamos a rede neural. Dito isto, por menor que seja esse valor de perda, ele tem pouco significado. Para colocar o desempenho do modelo em perspectiva, vamos calcular sua precisão — a percentagem de imagens que o modelo classificou corretamente.
Passo 4 — Avaliando o classificador de linguagem de sinais
Você agora avaliará seu classificador de linguagem de sinais calculando sua precisão no dataset de validação, um conjunto de imagens que o modelo não viu durante o treinamento. Isso fornecerá um melhor senso de desempenho do modelo do que forneceu o valor da perda final. Além disso, você adicionará utilitários para salvar nosso modelo treinado no final do treinamento e carregará nosso modelo pré-treinado ao realizar inferência.
Crie um novo arquivo, chamado step_4_evaluate.py.
Importe os utilitários necessários:
A seguir, defina um utilitário para avaliar o desempenho da rede neural. A seguinte função compara a letra prevista pela rede neural com a letra verdadeira, para uma única imagem:
outputs é uma lista de probabilidades de classe para cada amostra. Por exemplo, outputs, para uma única amostra podem ser [0.1, 0.3, 0.4, 0.2]. labels é uma lista de classes de rótulos. Por exemplo, a classe do rótulo pode ser 3.
Y = ... converte os rótulos em uma matriz do NumPy. A seguir, Yhat = np.argmax(...) converte as probabilidades da classe outputs para classes previstas. Por exemplo, a lista de probabilidades de classe [0.1, 0.3, 0.4, 0.2] geraria a classe prevista 2, pois o valor de 0.4 do índice 2 é o maior valor.
Como tanto Y como Yhat são classes agora, você pode compará-las. Yhat = = Y verifica se a classe prevista corresponde à classe de rótulo, e np.sum(...) é um truque que calcula o número de valores verdadeiros. Em outras palavras, np.sum gerará o número de amostras que foram classificadas corretamente.
Adicione a segunda função batch_evaluate, que aplica a primeira função evaluate a todas as imagens:
O batch é um grupo de imagens armazenado como um único tensor. Primeiro, você incrementa o número total de imagens que você está avaliando (n) pelo número de imagens neste lote. A seguir, você executa a inferência na rede neural com este lote de imagens, output = net(...). A verificação de tipo if isinstance(...) converte as saídas em uma matriz do NumPy, se necessário. Por fim, você usará evaluate para calcular o número de amostras corretamente classificadas. Na conclusão da função, você calcula o percentual de amostras que você classificou corretamente, score / n.
Por fim, adicione o script a seguir para aproveitar os utilitários anteriores:
Isso carrega uma rede neural pré-treinada e avalia seu desempenho no dataset da linguagem de sinais fornecido. Especificamente, o script aqui retorna precisão nas imagens que você usou para treinar e um conjunto separado de imagens que você colocou para fins de teste, chamado de conjunto de validação.
Em seguida, você exportará o modelo PyTorch para um binário ONNX. Este arquivo binário, pode então ser usado em produção para executar a inferência com seu modelo. Mais importante, o código em execução neste binário não precisa de uma cópia da definição original da rede. No final da função validate adicione o seguinte:
Isso exporta o modelo ONNX, verifica o modelo exportado e, em seguida, executa a inferência com o modelo exportado. Verifique com atenção se o seu arquivo corresponde ao arquivo do Passo 4 neste repositório:
Para usar e avaliar o ponto de verificação da última etapa, execute o seguinte:
Isso gerará uma saída semelhante à seguinte, afirmando que o modelo exportado, não apenas funciona, mas também concorda com o modelo PyTorch original:
Output========== PyTorch ==========
Training accuracy: 99.9
Validation accuracy: 97.4
========== ONNX ==========
Training accuracy: 99.9
Validation accuracy: 97.4
Sua rede neural atinge uma precisão de treinamento de 99,9% e uma precisão de validação de 97.4%. Esta diferença entre a precisão de treinamento e a de validação indica que seu modelo está sobreajustado. Isso significa que, em vez de aprender padrões generalizáveis, seu modelo memorizou os dados de treinamento. Para entender as implicações e causas do sobreajuste consulte Understanding Bias-Variance Tradeoffs.
Neste ponto, completamos um classificador de linguagem de sinais. Em essência, nosso modelo pode distinguir corretamente a ambiguidade entre sinais, quase todo o tempo. Este é um modelo razoavelmente bom, por isso vamos passar para a fase final da nossa aplicação. Vamos usar este classificador de linguagem de sinais em uma aplicação de webcam em tempo real.
Passo 5 — Vinculando a entrada da câmera
O próximo objetivo será vincular a câmera do computador ao classificador de linguagem de sinais. Você coletará a entrada da câmera, classificará a linguagem de sinais exibida, e, em seguida, informará o sinal classificado para o usuário.
Agora, crie um script Python para o detector facial. Crie o arquivo step_6_camera.py usando o nano ou seu editor de texto favorito:
Adicione o seguinte código ao arquivo:
Este código importa o OpenCV, que contém seus utilitários de imagem, e o runtime do ONNX, que é tudo o que você precisa para executar a inferência com seu modelo. O restante do código é típico de um programa Python.
Agora, substitua pass na função main pelo seguinte código, que inicializa um classificador de linguagem de sinais usando os parâmetros que você treinou anteriormente. Além disso, adicione um mapeamento de índices para letras e estatísticas de imagem:
Você usará elementos deste script de teste da documentação oficial do OpenCV. Especificamente, você atualizará o corpo da função main. Comece inicializando um objeto VideoCapture que é definido para capturar uma entrada ativa da câmera do seu computador. Coloque isto no final da função main:
A seguir, adicione um loop while, que lê da câmera em cada timestep:
Escreva uma função utilitária que faça o corte central do quadro da câmera. Coloque esta função antes do main:
A seguir, pegue o corte central do quadro da câmera, converta para a escala de cinza, normalize e redimensione para 28x28. Coloque isto dentro do loop while dentro da função main:
Ainda dentro do loop while, execute a inferência com o runtime ONNX. Converta as saídas para um índice de classe, depois, para uma letra:
Exiba a letra prevista dentro do quadro e apresente o quadro de volta ao usuário:
No final do loop while, adicione este código para verificar se o usuário obtém o caractere q e, caso positivo, saia da aplicação. Esta linha interrompe o programa por 1 milissegundo. Adicione o seguinte:
Por fim, termine a captura e feche todas as janelas. Coloque isto fora do loop while para encerrar a função main.
Verifique novamente se seu arquivo corresponde ao seguinte ou a este repositório:
Saia do seu arquivo e execute o script.
Assim que o script for executado, uma janela aparecerá com sua entrada da webcam ativa. A letra prevista da linguagem de sinais será mostrada no topo à esquerda. Levante a mão e faça seu sinal favorito para ver o classificador em ação. Aqui estão alguns resultados de amostra mostrando a letra L e D.

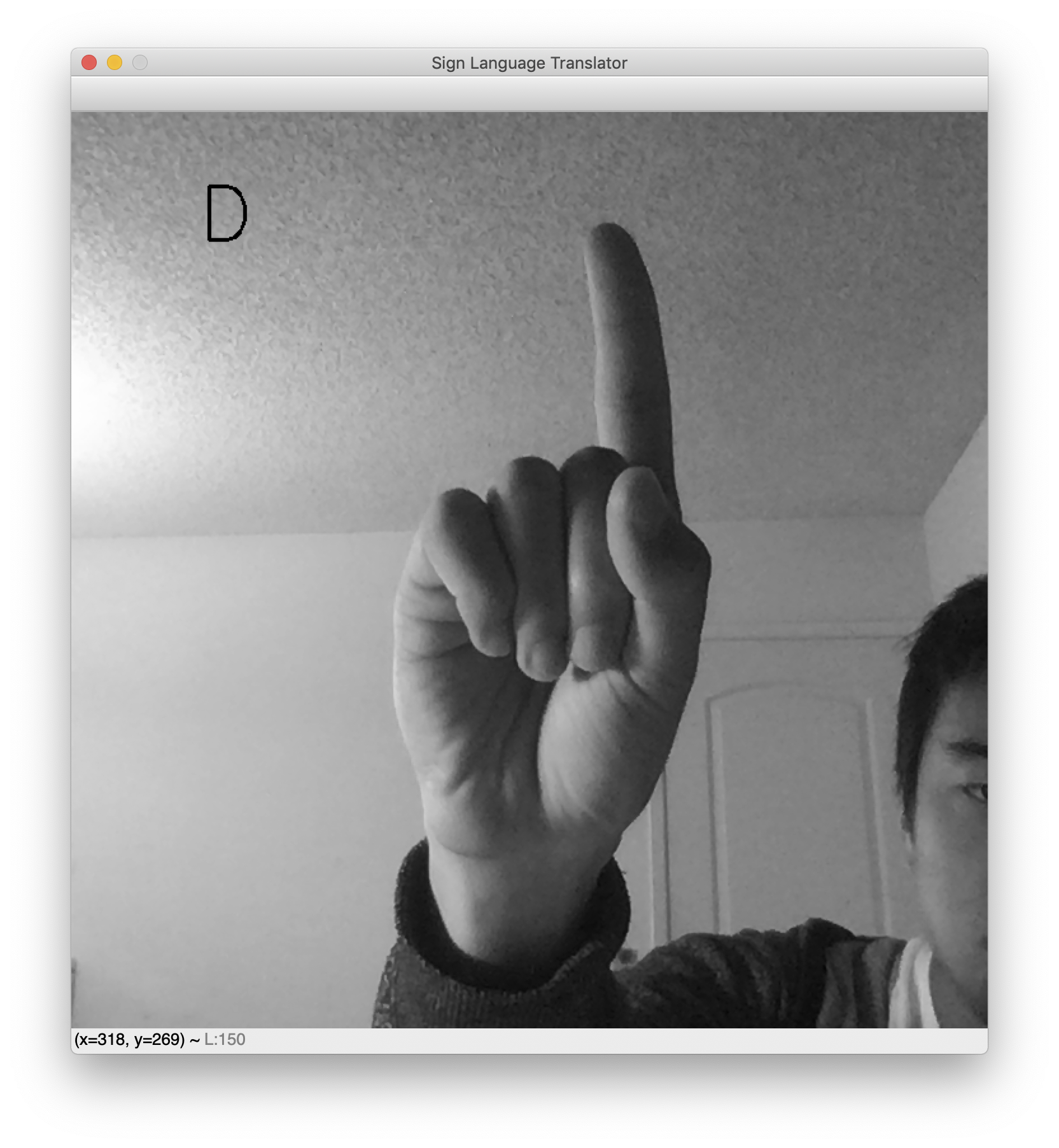
Ao testar, observe que o pano de fundo precisa ser bastante claro para este tradutor funcionar. Essa é uma consequência infeliz da limpeza do dataset. Se o dataset incluísse imagens de sinais de mão com planos de fundo variados, a rede seria menos sensível a planos de fundo ruidosos. No entanto, o dataset apresenta planos de fundo brancos e mãos bem centralizadas. Como resultado, este tradutor da webcam funciona melhor quando sua mão também está centralizada e em um plano de fundo em branco.
Isso conclui a aplicação do tradutor de linguagem de sinais.
Conclusão
Neste tutorial, você construiu um tradutor da linguagem americana de sinais usando visão computacional e um modelo de aprendizagem de máquina. Em particular, você viu novos aspectos do treinamento de modelo de aprendizagem de máquina — especificamente aumento de dados para robustez do modelo, programação de taxas de aprendizagem para menor perda, e exportação de modelos de IA usando o ONNX para uso em produção. Isso terminou em um aplicativo de visão computacional em tempo real, que traduz a linguagem de sinais em letras usando um pipeline que você criou. Vale ressaltar que o combate à fragilidade do classificador final pode ser realizado com qualquer um ou todos os métodos a seguir. Para uma exploração mais aprofundada, tente os seguintes tópicos para aprimorar sua aplicação:
- Generalização: isso não é um subtópico dentro da visão computacional, em vez disso, é um problema constante ao longo de toda a aprendizagem de máquina. Veja Understanding Bias-Variance Tradeoffs.
- Adaptação de domínio: digamos que seu modelo seja treinado no domínio A (por exemplo, ambientes ensolarados). Você pode adaptar o modelo ao domínio B (por exemplo, ambientes nublados) rapidamente?
- Exemplos adversos: digamos que um adversário esteja criando imagens intencionalmente para enganar seu modelo. Como você pode criar essas imagens? Como você pode combater essas imagens?
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!

Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.