Tutorial
Создание нейронной сети для перевода языка жестов на английский

Автор выбрал Code Org для получения пожертвования в рамках программы Write for DOnations.
Введение
Компьютерное зрение — это подсфера компьютерной науки, задача которой заключается в получении понимания высшего порядка на основании изображений и видео. Оно лежит в основе таких технологий, как смешные фильтры для видеочатов, аутентификация лица вашим мобильным устройством и беспилотные автомобили.
В этом руководстве вы будете использовать компьютерное зрение для создания переводчика американского языка жестов для своей веб-камеры. Во время работы по этому руководству вы будете использовать OpenCV, библиотеку компьютерного зрения, PyTorch для создания глубокой нейронной сети и onnx для экспорта своей нейронной сети. Также при создании приложения компьютерного зрения вы будете использовать следующие понятия:
- Вы будете использовать те же три шага, что использовались в руководстве Применение компьютерного зрения для создания эмоционального фильтра «Собака»: предварительная обработка набора данных, обучение модели и оценка модели.
- Также вы расширите каждый из этих шагов: примените приращение данных для работы с поворотом руки или смещением руки от центра, измените графики скорости обучения для повышения точности модели и экспортируете модели для увеличения скорости формирования логических выводов.
- Также вы научитесь использовать связанные концепции в машинном обучении.
К концу этого руководства вы сможете создать переводчик американского языка жестов и получите основополагающие знания по глубинному обучению. Также для этого проекта вы можете получить полный исходный код.
Предварительные требования
Для этого обучающего модуля вам потребуется следующее:
- Локальная среда разработки для Python 3 с минимум 1 ГБ оперативной памяти. Для необходимой настройки можно следовать инструкциям руководства Установка и настройка локальной среды программирования для Python 3.
- Рабочая веб-камера для обнаружения изображений в реальном времени.
- (Рекомендуется) Создание эмоционального фильтра «Собака»; это обучающее руководство не используется явно, но на его основе разработаны и подкреплены аналогичные идеи.
Шаг 1 — Создание проекта и установка зависимостей
Давайте создадим рабочее пространство для этого проекта и установим необходимые зависимости.
Для дистрибутивов Linux начните с подготовки диспетчера системных пакетов и установки пакета Python3 virtualenv. Используйте:
Мы назовем наше рабочее пространство SignLanguage:
Перейдите в директорию SignLanguage:
Затем создайте новую виртуальную среду для проекта:
Активируйте среду:
Затем установите PyTorch, платформу глубинного обучения для Python, которую мы будем использовать в этом руководстве.
В macOS установите Pytorch с помощью следующей команды:
В Linux и Windows используйте следующие команды для создания значения CPU-only:
Теперь установите предварительно упакованные бинарные файлы для OpenCV, numpy и onnx, которые являются библиотеками для компьютерного зрения, линейной алгебры, экспорта моделей ИИ и выполнения моделей ИИ соответственно. OpenCV предлагает такие утилиты, как поворот изображений, а numpy предлагает такие утилиты линейной алгебры, как инверсия матрицы:
В дистрибутивах Linux вам потребуется установить libSM.so:
После установки зависимостей мы создадим первую версию нашего переводчика языка жестов: классификатор языка жестов.
Шаг 2 — Подготовка набора данных для классификации языка жестов
В следующих трех разделах вы создадите классификатор языка с помощью нейронной сети. Ваша цель — создать модель, которая принимает картину руки в качестве ввода и вывода буквы.
Следующие три шага требуются для создания модели классификации машинного обучения:
- Предварительная обработка данных: примените унитарное кодирование для своих меток и оберните данные в тензоры PyTorch. Обучите модель на приращенных данных для ее подготовки к «необычному» вводу, например смещенной или перевернутой руки.
- Спецификация и обучение модели: настройте нейронную сеть с помощью PyTorch. Определите гиперпараметры обучения, например продолжительность обучения, и запустите стохастический градиентный спуск. Также вы измените определенный обучающий гиперпараметр, график скорости обучения. Это позволит повысить точность модели.
- Запуск прогноза с помощью модели: оцените нейронную сеть на ваших данных проверки, чтобы понять ее точность. Затем экспортируйте модель в формат ONNX для повышения скорости формирования логического вывода.
В этом разделе обучающего модуля вы выполните первый шаг из трех. Вы загрузите данные, создадите объект Dataset для итерации по вашим данным и, наконец, примените приращение данных. В конце этого шага вы получите алгоритмический способ доступа к изображениям и меткам в вашем наборе данных для использования в вашей модели.
Сначала загрузите набор данных в текущий рабочий каталог:
Примечание. В macOS wget по умолчанию отсутствует. Для этого установите Homebrew, следуя инструкциям этого обучающего руководства DigitalOcean. Затем запустите brew wget install.
Распакуйте файл с архивом, содержащий каталог data/:
Создайте новый файл с именем step_2_dataset.py:
Как и ранее, импортируйте необходимые утилиты и создайте класс, который будет хранить ваши данные. Для обработки данных здесь вы создадите новый набор данных для обучения и тестирования. Вы выполните установку интерфейса PyTorch Dataset, который позволит загружать и использовать конвейер встроенных данных PyTorch для вашего набора данных для классификации языка жестов:
Удалите заполнитель pass в классе SignLanguageMNIST. На его месте добавьте метод создания преобразования меток:
Метки варьируются от 0 до 25. Но буквы J (9) и Z (25) не включены. Это означает, что есть только 24 действительных значения меток. Таким образом, набор всех значений для меток начиная с 0 является непрерывным, мы обозначаем все метки [0, 23]. Это преобразование с меток набора данных [0, 23] на индексы букв [0, 25] обеспечивается этим методом get_label_mapping.
Далее добавьте метод извлечения меток и образцов из файла CSV. Следующий вывод предполагает, что каждая строка начинается с label, и затем следуют значения 784 пикселя. Эти значения 784 пикселя представляют изображение 28x28:
Объяснение того, как эти значения 784 пикселя представляют изображение, см. в модуле Создание эмоционального фильтра «Собака», шаг 4.
Обратите внимание, что каждая строка в итерируемом csv.reader представляет собой список строк; вызовы int и map(int, ...) приводят все строки к целым числам. Прямо под нашим статичным методом добавьте функцию, которая будет инициализировать нашего держателя данных:
Эта функция начинается с загрузки образцов и меток. Затем она оборачивает данные в массивах NumPy. Значение и стандартное отклонение будет скоро объяснено в следующем разделе __getitem__.
Сразу после функции __init__ добавьте функцию __len__. Dataset требует, чтобы этот метод определял, когда прекращать итерацию данных:
Наконец, добавьте метод __getitem__, который возвращает словарь, содержащий образец и метку:
Вы используете технику под названием приращение данных, где во время обучения происходит возмущение образцов для повышения устойчивости к подобным нарушениям работы. В частности, случайное уменьшение масштаба изображения путем изменения значений и локаций посредством RandomResizedCrop. Обратите внимание, что уменьшение масштаба не должно влиять на финальный класс языка жестов, то есть метка не трансформируется. Дополнительно вы упорядочили вводы, чтобы значения изображения ожидаемо изменяли масштаб на диапазон [0, 1] вместо [0, 255]. Для этого во время упорядочивания используйте набор данных _mean и _std.
Ваш завершенный класс SignLanguageMNIST будет выглядеть следующим образом:
Как и ранее, теперь вы проверите функции утилиты нашего набора данных, загрузив набор данных SignLanguageMNIST. Добавьте следующий код в конец файла после класса SignLanguageMNIST:
Этот код инициализирует набор данных с помощью класса SignLanguageMNIST. Затем для наборов обучения и проверки он оборачивает набор данных в DataLoader. Это позволит перевести набор данных в итерируемый вариант для использования позже.
Теперь вы убедитесь, что утилиты набора данных функционируют. Создайте образец загрузчика набора данных с помощью DataLoader и напечатайте первый элемент этого загрузчика. Добавьте в конец своего файла следующую строку:
Вы можете проверить, что ваш файл соответствует файлу step_2_dataset в этом (репозитории). Закройте редактор и запустите скрипт со следующим:
Таким образом выводится следующая пара тензоров. Наш конвейер данных выводит два образца и две метки. Это означает, что наш конвейер данных готов к использованию:
Output{'image': tensor([[[[ 0.4337, 0.5022, 0.5707, ..., 0.9988, 0.9646, 0.9646],
[ 0.4851, 0.5536, 0.6049, ..., 1.0502, 1.0159, 0.9988],
[ 0.5364, 0.6049, 0.6392, ..., 1.0844, 1.0844, 1.0673],
...,
[-0.5253, -0.4739, -0.4054, ..., 0.9474, 1.2557, 1.2385],
[-0.3369, -0.3369, -0.3369, ..., 0.0569, 1.3584, 1.3242],
[-0.3712, -0.3369, -0.3198, ..., 0.5364, 0.5364, 1.4783]]],
[[[ 0.2111, 0.2796, 0.3481, ..., 0.2453, -0.1314, -0.2342],
[ 0.2624, 0.3309, 0.3652, ..., -0.3883, -0.0629, -0.4568],
[ 0.3309, 0.3823, 0.4337, ..., -0.4054, -0.0458, -1.0048],
...,
[ 1.3242, 1.3584, 1.3927, ..., -0.4054, -0.4568, 0.0227],
[ 1.3242, 1.3927, 1.4612, ..., -0.1657, -0.6281, -0.0287],
[ 1.3242, 1.3927, 1.4440, ..., -0.4397, -0.6452, -0.2856]]]]), 'label': tensor([[24.],
[11.]])}
Теперь вы убедились, что ваш конвейер данных работает. Это завершает первый шаг — предварительную обработку данных, которая сейчас включает приращение данных для повышения надежности модели. Далее вы определите нейронную сеть и оптимизатор.
Шаг 3 — Создание и обучение классификатора языка жестов с помощью глубинного обучения
Имея функционирующий конвейер данных, вы определите модель и обучите ее на данных. В частности, вы создадите нейронную сеть с шестью уровнями, определите потери, оптимизатор и, наконец, оптимизируете функцию потерь для прогнозов вашей нейронной сети. В конце этого шага у вас будет рабочий классификатор языка жестов.
Создайте новый файл step_3_train.py:
Импортируйте необходимые утилиты:
Определите нейронную сеть PyTorch, содержащую три сверточных слоя, за которыми следуют три полносвязных слоя. Добавьте следующее в конец существующего скрипта:
Теперь инициализируйте нейронную сеть, определите функцию потерь и определите гиперпараметры оптимизации, добавив следующий код в конец скрипта:
Наконец, вы обучите два периода:
Вы определяете период для итерации обучения, где каждый образец обучения использовался точно один раз. В конце основной функции параметры модели будут сохранены в файле под названием checkpoint.pth.
Добавьте следующий код в конец скрипта для извлечения image и label из загрузчика набора данных, а затем оберните каждый в Variable PyTorch:
Этот код также запустит предварительный проход, а затем выполнит обратное распространение по потерям и нейронной сети.
В конце файла добавьте следующее для вызова функции main:
Еще раз убедитесь, что ваш файл соответствует следующему:
Сохраните и закройте его. Затем запустите обучение с целью подтверждения правильности концепции, запустив:
Вы увидите вывод, похожий на следующий, по мере обучения нейронной сети:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
[1, 0] loss: 0.254097
[1, 100] loss: 0.208116
[1, 200] loss: 0.196270
[1, 300] loss: 0.183676
[1, 400] loss: 0.169824
[1, 500] loss: 0.157704
[1, 600] loss: 0.151408
[1, 700] loss: 0.136470
[1, 800] loss: 0.123326
Для снижения потерь вы можете увеличить число периодов до 5, 10 или даже 20. Однако по истечении определенного периода обучения потери сети перестанут уменьшаться при увеличении времени обучения. Чтобы обойти эту проблему, так как время обучения увеличивается, вы установите график скорости обучения, который снижает скорость обучения со временем. Чтобы понять, почему это работает, см. визуализацию Distill в статье Why Momentum Really Works («Почему момент действительно работает»).
Измените функцию main с помощью следующих двух строк, определив scheduler и вызвав scheduler.step. Также измените число периодов на 12:
Убедитесь, что ваш файл соответствует файлу шага 3 в этом репозитории. Обучение будет длиться около 5 минут. Ваш вывод будет выглядеть примерно следующим образом:
Output[0, 0] loss: 3.208171
[0, 100] loss: 3.211070
[0, 200] loss: 3.192235
[0, 300] loss: 2.943867
[0, 400] loss: 2.569440
[0, 500] loss: 2.243283
[0, 600] loss: 1.986425
[0, 700] loss: 1.768090
[0, 800] loss: 1.587308
...
[11, 0] loss: 0.000302
[11, 100] loss: 0.007548
[11, 200] loss: 0.009005
[11, 300] loss: 0.008193
[11, 400] loss: 0.007694
[11, 500] loss: 0.008509
[11, 600] loss: 0.008039
[11, 700] loss: 0.007524
[11, 800] loss: 0.007608
Финальная полученная потеря составляет 0.007608, что на три порядка меньше начальной потери 3.20. Это завершает второй этап нашего рабочего процесса, где мы настраиваем и обучаем нейронную сеть. Таким образом, чем меньше значение потери, тем оно незначительнее. Чтобы объективно оценить производительность модели, мы вычислим ее точность в процентном соотношении изображений, которые модель классифицировала правильно.
Шаг 4 — Оценка классификатора языка жестов
Теперь вы оцените ваш классификатор языка жестов, вычислив его точность на контрольной выборке, наборе изображений, которые модель не увидела во время обучения. Это позволит лучше понять производительность модели, чем с помощью значения финальной потери. Также вы добавите утилиты для сохранения нашей обученной модели в конце обучения и загрузите нашу предварительно обученную модель при формировании логического вывода.
Создайте новый файл с именем step_4_evaluate.py.
Импортируйте необходимые утилиты:
Далее определите утилиту для оценки производительности нейронной сети. Следующая функция сравнивает прогнозируемую букву нейронной сети с истинной буквой для отдельного изображения:
outputs — это список вероятностей класса для каждого образца. Например, outputs для отдельного образца могут быть [0.1, 0.3, 0.4, 0.2]. labels — это список классов метки. Например, класс метки может быть 3.
Y = ... конвертирует метки в массив NumPy. Далее Yhat = np.argmax(...) конвертирует вероятности класса outputs в прогнозируемые классы. Например, список вероятностей класса [0.1, 0.3, 0.4, 0.2] выведет прогнозируемый класс 2, поскольку значение индекса 2 значения 0.4 является самым большим значением.
Поскольку Y и Yhat теперь являются классами, вы можете их сравнить. Yhat == Y проверяет, соответствует ли прогнозируемый класс классу метки, и np.sum(...) является приемом, который вычисляет количество истинных значений y. Другими словами, np.sum выведет количество образцов, классифицированных правильно.
Добавьте вторую функцию batch_evaluate, которая применяет первую функцию evaluate ко всем изображениям:
batch — это группа изображений, сохраненная как один тензор. Вначале вы увеличиваете общее количество оцениваемых изображений (n) на количество изображений в этой партии. Далее вы запустите логический вывод на нейронной сети с этой партией изображений outputs = net(...). Проверка типа if isinstance(...) конвертирует выводы в массив NumPy при необходимости. Наконец, вы используете команду evaluate для расчета количества правильно классифицированных образцов. По завершении функции вы вычисляете процент образцов, которые были правильно классифицированы, score / n.
Наконец, добавьте следующий скрипт для использования предыдущих утилит:
Это загрузит предварительно обученную нейронную сеть и оценит ее производительность на предоставленном наборе данных языка жестов. В частности, скрипт здесь выводит точность для изображений, которые использовались для обучения, и отдельного набора изображений, которые вы отобрали для тестирования, называемого контрольной выборкой.
Затем вы экспортируете модель PyTorch в бинарный файл ONNX. Затем этот бинарный файл можно использовать в производственной среде для запуска логического вывода для вашей модели. Не менее важно, что для кода, запускающего этот бинарный файл, не требуется копия определения оригинальной сети. В конце функции validate добавьте следующее:
Это экспортирует модель ONNX, проверяет экспортированную модель, а затем запускает логический вывод для экспортированной модели. Убедитесь, что ваш файл соответствует файлу шага 4 в этом репозитории:
Для использования и оценки точки сохранения из последнего шага запустите следующее:
В результате будет получен примерно следующий вывод, который подтверждает, что экспортированная модель не только работает, но также согласуется с вашей оригинальной моделью PyTorch:
Output========== PyTorch ==========
Training accuracy: 99.9
Validation accuracy: 97.4
========== ONNX ==========
Training accuracy: 99.9
Validation accuracy: 97.4
Ваша нейронная сеть приобретает точность обучения 99,9% и точность проверки 97,4%. Эта разница между точностью обучения и проверки указывает на то, что ваша модель чрезмерно обучена. Это означает, что модель вместо запоминания обобщаемых паттернов запомнила данные обучения. Для понимания возможных последствий и причин чрезмерного обучения см. Understanding Bias-Variance Tradeoffs («Понимание компромисса отклонение–дисперсия»).
На этом этапе мы завершили классификатор языка жестов. Фактически наша модель может корректно преодолевать неоднозначность жестов почти постоянно. Это обоснованно хорошая модель, поэтому мы переходим к финальной стадии нашего приложения. Мы будем использовать этот классификатор языка жестов в приложении для веб-камеры в режиме реального времени.
Шаг 5 — Привязка к данным из камеры
Следующей задачей будет привязка камеры компьютера к вашему классификатору языка жестов. Вы будете собирать входящие данные камеры, классифицировать отображаемый язык жестов и затем сообщать классифицированный жест пользователю.
Теперь создайте скрипт Python для детектора лица. Создайте файл step_6_camera.py, используя nano или другой предпочитаемый текстовый редактор:
Добавьте в файл следующий код:
Этот код импортирует OpenCV, который содержит утилиты вашего изображения, и среду исполнения ONNX, чего вполне достаточно для запуска формирования логических выводов для вашей модели. Остальная часть кода типична для программных шаблонов Python.
Теперь замените pass в функции main на следующий код, что инициализирует использование классификатором языка жестов параметров, обученных ранее. Также добавьте преобразование с индексов на буквы и статистику изображения:
Вы будете использовать элементы этого тестового скрипта из официальной документации OpenCV. В частности, вы обновите тело функции main. Начните с инициализации объекта VideoCapture, который настроен на фиксацию прямой трансляции с камеры вашего компьютера. Поместите это в конец функции main:
Затем добавьте цикл while, который считывает данные с камеры каждый такт:
Напишите функцию утилиты, которая делает центральный снимок для рамки камеры. Поместите эту функцию перед main:
Затем сделайте центральный снимок для рамки камеры, переведите в оттенки серого, нормализуйте и измените размер на 28x28. Поместите это в цикл while в функции main:
Здесь же, в цикле while, запустите логический вывод в среде выполнения ONNX. Конвертируйте выводы в индекс класса, затем в букву:
Отобразите прогнозируемую букву внутри рамки и отобразите рамку обратно для пользователя:
В конце цикла while добавьте этот код для проверки того, нажимает ли пользователь символ q, и если да, выйдите из приложения. Эта строка останавливает программу на 1 миллисекунду. Добавьте следующее:
И наконец, выпустите снимок и закройте все окна. Поместите за циклом while в конец функции main.
Еще раз убедитесь, что ваш файл соответствует следующему или этому репозиторию:
Закройте файл и запустите скрипт.
После запуска скрипта откроется окно с прямой трансляцией с веб-камеры. Прогнозируемая буква языка жестов отобразится вверху слева. Задержите руку и покажите любимый жест, чтобы увидеть классификатор в действии. Здесь представлены примеры с отображением L и D.

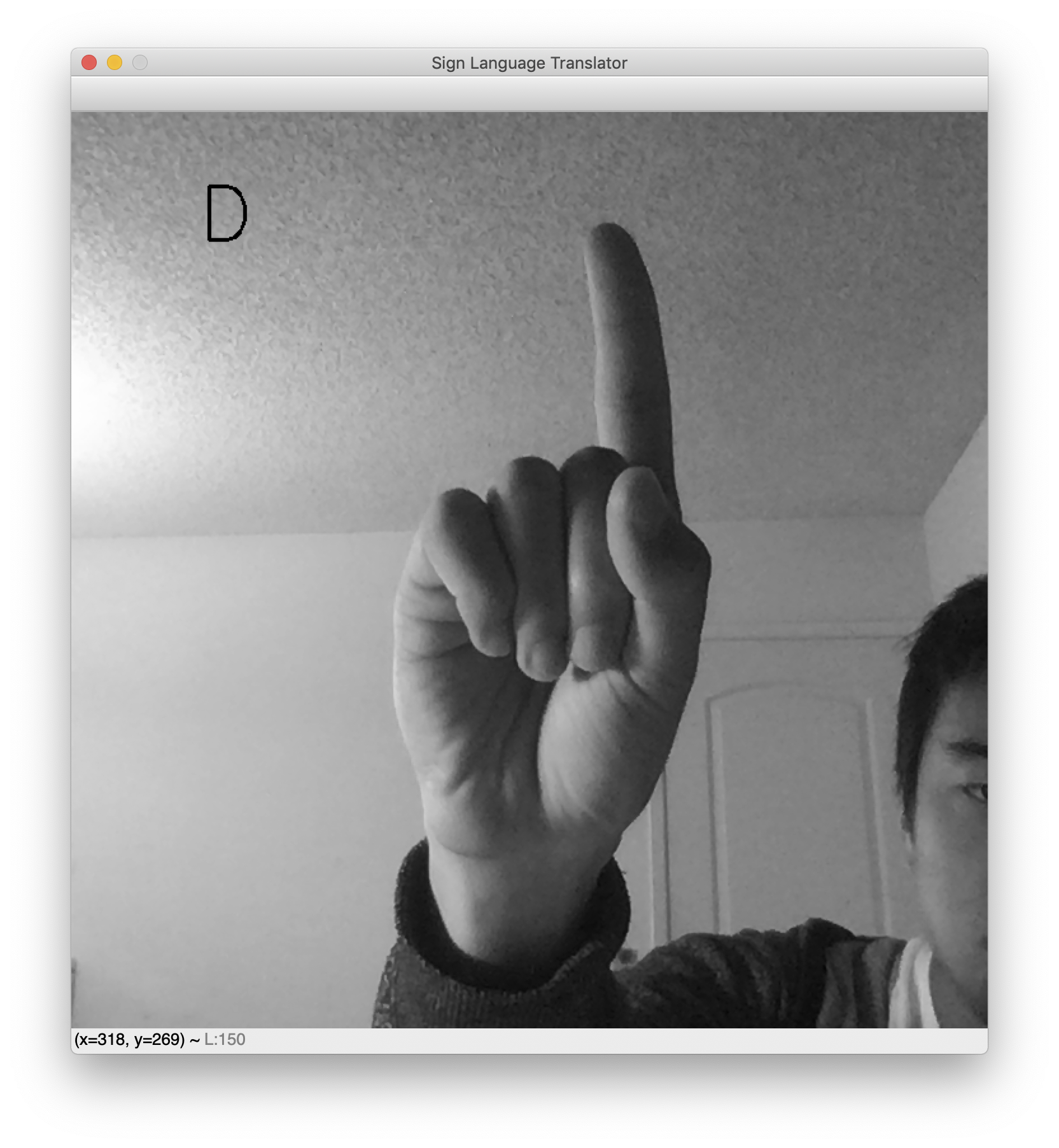
Во время тестирования обратите внимание, что фон должен быть достаточно четким для работы этого переводчика. Это нежелательное последствие чистоты набора данных. Если бы набор данных включал изображения ручных жестов на разных вариантах фона, сеть была бы устойчива к фоновому шуму. Однако этот набор данных требует наличия пустого фона и правильного расположения руки по центру. В результате этот переводчик для веб-камеры лучше всего работает, когда рука расположена по центру на пустом фоне.
На этом завершается работа над приложением переводчика языка жестов.
Заключение
В этом обучающем модуле вы создали переводчик американского языка жестов с помощью компьютерного зрения и модели машинного обучения. В частности, вы увидели новые аспекты обучения модели машинного обучения, а именно приращение данных для надежности модели, графики скорости обучения для сокращения потерь и экспорт моделей ИИ с помощью ONNX для производственной среды. Кульминацией стало приложение компьютерного зрения в режиме реального времени, которое переводит язык жестов в буквы с помощью созданного конвейера. Стоит отметить, что преодолеть хрупкость финального классификатора можно одним или всеми из следующих способов. Для дальнейшего изучения попробуйте изучить следующие темы, которые помогут усовершенствовать ваше приложение:
- Обобщение: это скорее не подтема компьютерного зрения, а постоянная проблема всего машинного обучения. См. Understanding Bias-Variance Tradeoffs (Понимание компромисса отклонение–дисперсия).
- Адаптация домена: допустим ваша модель была обучена на домене А (например для солнечной среды). Сможете ли вы быстро адаптировать модель к домену В (например для пасмурной среды)?
- Примеры состязательных моделей: допустим состязательная модель намеренно создает изображения, чтобы обмануть вашу модель. Как создавать такие изображения? Как бороться с такими изображениями?
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!

Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.