Sr Technical Content Strategist and Team Lead

Introduction
With the rise of large language models (LLMs), it’s becoming more practical to run these Generative AI models on cloud infrastructure. DigitalOcean recently introduced GPU Droplets, which allows developers to run computationally heavy tasks such as training and deploying LLMs efficiently. In this tutorial, you will learn to setup and use the LLM CLI and deploy OpenAI’s GPT-4o model on a DigitalOcean GPU Droplet using the command line.
LLM CLI is a command line utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine.
Prerequisites
Before you start, ensure you have:
- A DigitalOcean Cloud account.
- A GPU Droplet deployed and running.
- Familiarity with the Linux command line. To learn more, you can visit this guide on Linux command line primer.
- The LLM CLI tool installed on your GPU Droplet.
- An OpenAI API key set up for accessing the GPT-4o model.
Step 1 - Set Up the GPU Droplet
1.Create a New Project - You will need to create a new project from the cloud control panel and tie it to a GPU Droplet.
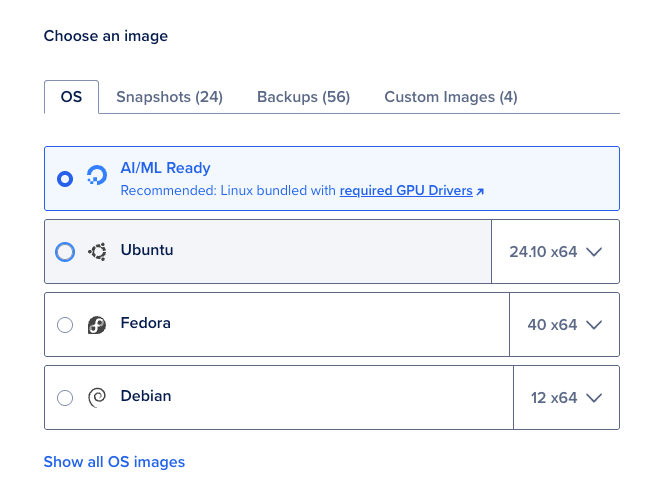
2.Create a GPU Droplet - Log into your DigitalOcean account, create a new GPU Droplet, and choose AI/ML Ready as the OS. This OS image installs all the necessary NVIDIA GPU Drivers. You can refer to our official documentation on how to create a GPU Droplet.
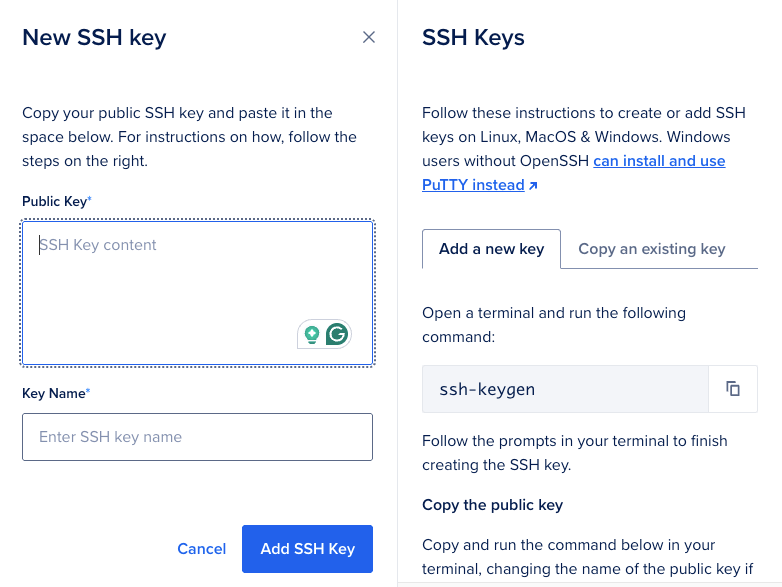
3.Add an SSH Key for authentication - An SSH key is required to authenticate with the GPU Droplet and by adding the SSH key, you can login to the GPU Droplet from your terminal.
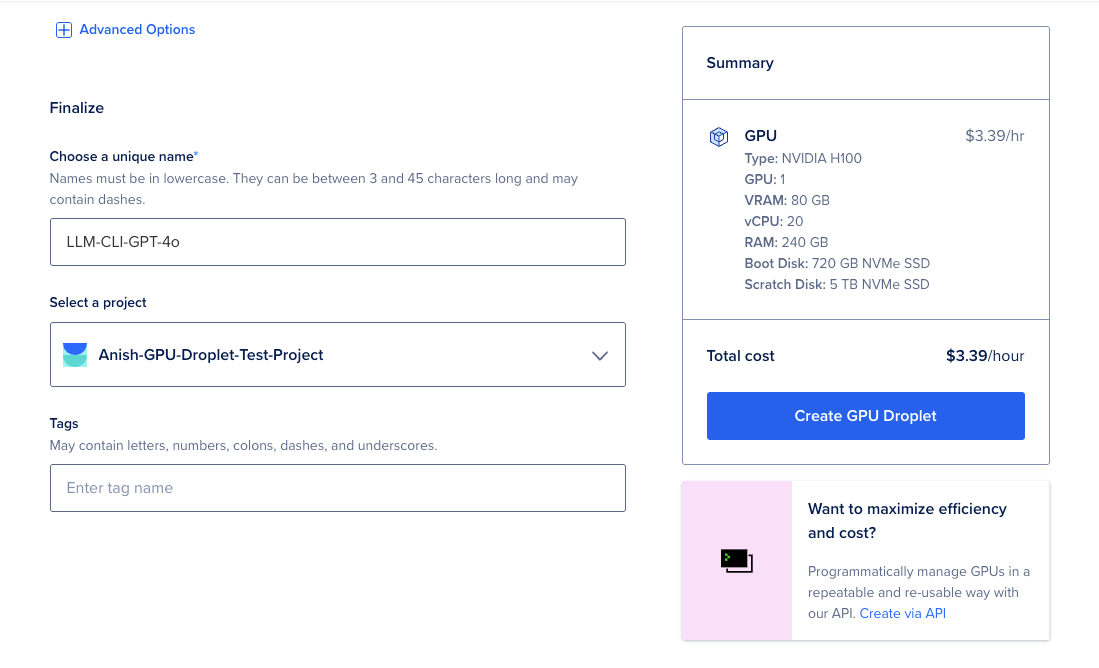
4.Finalize and Create the GPU Droplet - Once all of the above steps are completed, finalize and create a new GPU Droplet.
Step 2 - Install Dependencies
Once the GPU Droplet is ready and deployed. You can SSH to the GPU Droplet from your terminal.
ssh root@<your-droplet-ip>
LLM CLI requires Python and pip to be installed on your GPU Droplet.
sudo apt install python3 python3-pip -y
Ensure your Ubuntu based GPU Droplet is up to date:
sudo apt update && sudo apt upgrade -y
Step 3 - Install LLM CLI
Let’s install this CLI tool using pip:
pip install llm
Let’s verify the installation:
llm --version
Outputllm, version 0.16
You can use the below command to get a list of llm commands:
llm --help
OutputUsage: llm [OPTIONS] COMMAND [ARGS]...
Access large language models from the command-line
Documentation: https://llm.datasette.io/
To get started, obtain an OpenAI key and set it like this:
$ llm keys set openai
Enter key: ...
Then execute a prompt like this:
llm 'Five outrageous names for a pet pelican'
Options:
--version Show the version and exit.
--help Show this message and exit.
Commands:
prompt* Execute a prompt
aliases Manage model aliases
chat Hold an ongoing chat with a model.
collections View and manage collections of embeddings
embed Embed text and store or return the result
embed-models Manage available embedding models
embed-multi Store embeddings for multiple strings at once
install Install packages from PyPI into the same environment as LLM
keys Manage stored API keys for different models
logs Tools for exploring logged prompts and responses
models Manage available models
openai Commands for working directly with the OpenAI API
plugins List installed plugins
replicate Commands for working with models hosted on Replicate
similar Return top N similar IDs from a collection
templates Manage stored prompt templates
uninstall Uninstall Python packages from the LLM environment
Step 4 - API key management
Many LLM models require an API key. These API keys can be provided to this tool using several different mechanisms.
In this tutorial since you are deploying OpenAI’s GPT-4o model, you can obtain an API key for OpenAI’s language models from the API keys page on their site.
Once you have the API key ready and saved use the below command to store and save the APi key:
llm keys set openai
You will be prompted to enter the key like this:
OutputEnter key:<paste_your_api_key>
Step 5 - Deploy and run the GPT-4o Model Using LLM CLI
LLM CLI ships with a default plugin for talking to OpenAI’s API. It uses the gpt-3.5-turbo model as the default plugin. You can also install LLM plugins to use models from other providers such as Claude, gpt4all, llama etc, including openly licensed models to directly run on your own computer.
These plugins all help you run LLMs directly on your own computer.
To verify the list of LLM models plugins available, you can use the following command:
llm models
This should give you a list of models currently installed.
OutputOpenAI Chat: gpt-3.5-turbo (aliases: 3.5, chatgpt)
OpenAI Chat: gpt-3.5-turbo-16k (aliases: chatgpt-16k, 3.5-16k)
OpenAI Chat: gpt-4 (aliases: 4, gpt4)
OpenAI Chat: gpt-4-32k (aliases: 4-32k)
OpenAI Chat: gpt-4-1106-preview
OpenAI Chat: gpt-4-0125-preview
OpenAI Chat: gpt-4-turbo-2024-04-09
OpenAI Chat: gpt-4-turbo (aliases: gpt-4-turbo-preview, 4-turbo, 4t)
OpenAI Chat: gpt-4o (aliases: 4o)
OpenAI Chat: gpt-4o-mini (aliases: 4o-mini)
OpenAI Chat: o1-preview
OpenAI Chat: o1-mini
OpenAI Completion: gpt-3.5-turbo-instruct (aliases: 3.5-instruct, chatgpt-instruct)
Anthropic Messages: claude-3-opus-20240229 (aliases: claude-3-opus)
Anthropic Messages: claude-3-sonnet-20240229 (aliases: claude-3-sonnet)
Anthropic Messages: claude-3-haiku-20240307 (aliases: claude-3-haiku)
Anthropic Messages: claude-3-5-sonnet-20240620 (aliases: claude-3.5-sonnet)
You can use the llm install <model-name> command (a thin wrapper around pip install) to install other plugins.
Run a Prompt from the CLI
First, we will switch from ChatGPT 3.5 (the default) to GPT-4o. You can start interacting with it by querying directly from the command line. For example, ask the model a question like this:
llm -m gpt-4o "What is DigitalOcean GPU Droplet?"
OutputDigitalOcean GPU Droplets are specialized cloud-based virtual machines designed to handle high-performance computing tasks that require GPU acceleration. These Droplets are equipped with powerful graphics processing units (GPUs) that excel at parallel processing tasks, making them ideal for applications such as machine learning, data analysis, scientific computing, and rendering tasks that require significant computational power.
With GPU Droplets, users can leverage the processing capability of GPUs to speed up tasks that would otherwise take a long time on standard CPU-based instances. DigitalOcean provides these GPU instances with various configurations, allowing users to select the number of GPUs and the specific type of GPU that suits their workload requirements.
The key features and benefits of DigitalOcean GPU Droplets include:
1. **High Performance**: Access to powerful GPUs which are optimized for intensive computational tasks.
2. **Flexible Pricing**: Pay-as-you-go pricing model allows users to scale resources up or down based on demand.
3. **Scalability**: Easily scale GPU-powered compute resources according to the needs of your application.
4. **Integration and Ease of Use**: Easy integration with other DigitalOcean products and services, providing a unified cloud infrastructure handling both compute and storage needs.
5. **Developer-Friendly**: DigitalOcean's intuitive dashboard and developer-friendly infrastructure make it simpler for developers to deploy and manage GPU-intensive applications.
Note: The basic syntax to run a prompt using LLM CLI is llm "<prompt>". You can pass the --model <model name> to use a different model with the prompt.
You can also send a prompt to standard input, for example. If you send text to standard input and provide arguments, the resulting prompt will consist of the piped content followed by the arguments.
For example, you can pipe the llm command to ask it to explain a Python script or piece of code in a file.
cat factorial.py | llm "Explain this code and find any bugs"
OutputThe code provided is a Python implementation of a recursive function to calculate the factorial of a non-negative integer. Here's a breakdown of how the code works along with potential issues:
### Code Explanation:
1. **Function Definition**:
- `def factorial(n):` defines a function named `factorial` that takes one argument `n`.
2. **Base Case**:
- The first `if` statement `if n == 0 or n == 1:` checks whether `n` is either 0 or 1. The factorial of both 0 and 1 is 1, so if this condition is true, the function returns 1.
3. **Recursive Case**:
- The `else:` clause is executed if `n` is greater than 1. The function calls itself recursively with the argument `n - 1` and multiplies the result by `n`. This recursive calling continues until it reaches the base case.
4. **Example Usage**:
- The code asks the user to enter a number, converts that input into an integer using `int()`, and then prints the factorial of the given number by calling the `factorial` function.
### Bug and Issues:
1. **Input Validation**:
- The code does not handle invalid inputs, such as negative numbers or non-integer values. Factorial is defined only for non-negative integers. If the user enters a negative integer or a non-integer (such as a string), the program will either return a stack overflow error (for negative numbers leading to infinite recursion) or crash with a `ValueError` for non-integer inputs.
To fix this, you could add input validation to ensure `n` is a non-negative integer:
while True:
try:
number = int(input("Enter a non-negative integer: "))
if number < 0:
print("Please enter a non-negative integer.")
else:
break
except ValueError:
print("Invalid input. Please enter a valid integer.")
By default, the tool will start a new conversation each time you run it. But, you can opt to continue the previous conversation by passing the -c/--continue option:
llm "Give me more ways to optimize the code" -c
OutputCertainly! There are several ways to optimize the code for calculating the factorial. Here are some approaches, each with its own advantages:
### 1. Iterative Approach
The iterative approach is generally more efficient in terms of memory usage compared to the recursive approach:
def factorial(n):
result = 1
for i in range(2, n + 1):
result *= i
return result
### 2. Memoization
Using memoization can help store previously computed factorials to reduce redundant calculations. This is particularly useful if you're computing factorials of multiple numbers:
memo = {0: 1, 1: 1} # Base case
def factorial(n):
if n in memo:
return memo[n]
else:
memo[n] = n * factorial(n - 1)
return memo[n]
### 3. Using Python's Built-in Functions
Python has a built-in function for calculating factorials in the `math` module, which is highly optimized:
import math
number = int(input("Enter a non-negative integer: "))
print(f"The factorial of {number} is {math.factorial(number)}")
There are numerous use-cases to use LLM CLI on your system to interact, build and deploy Generative AI applications. You can check out more here.
Conclusion
By following this guide, you’ve successfully deployed the OpenAI GPT-4o model using the LLM CLI on a DigitalOcean GPU Droplet. You can now use this setup for various applications that require high-performance language models, such as content generation, chatbots, or natural language processing.
Feel free to experiment with other models supported by the LLM CLI or scale your deployment by running multiple models or increasing the resources of your GPU Droplet.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Anish is a Sr Technical Content Strategist and Team Lead at DigitalOcean with 7+ years of experience as an DevOps SRE at Nutanix and Cloud consultant at AMEX, and technical writing at DOCN, and shipping deep infra and AI inference tutorials that help developers deploy production‑ready applications on DigitalOcean.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
