By Carlos Samito Francisco Mucuho and Anish Singh Walia

The author selected Open Source Initiative to receive a donation as part of the Write for DOnations program.
Introduction
In this tutorial, you will build a Python application capable of extracting audio from an input video, transcribing the extracted audio, generating a subtitle file based on the transcription, and then adding the subtitle to a copy of the input video.
To build this application, you will use FFmpeg to extract audio from an input video. You will use OpenAI’s Whisper to generate a transcript for the extracted audio and then use this transcript to generate a subtitle file. Additionally, you will use FFmpeg to add the generated subtitle file to a copy of the input video.
FFmpeg is a powerful and open-source software suite for handling multimedia data, including audio and video processing tasks. It provides a command-line tool that allows users to convert, edit, and manipulate multimedia files with a wide range of formats and codecs.
OpenAI’s Whisper is an automatic speech recognition (ASR) system designed to convert spoken language into written text. Trained on a vast amount of multilingual and multitasking supervised data, it excels at transcribing diverse audio content with high accuracy.
By the end of this tutorial, you will have an application capable of adding subtitles to a video:
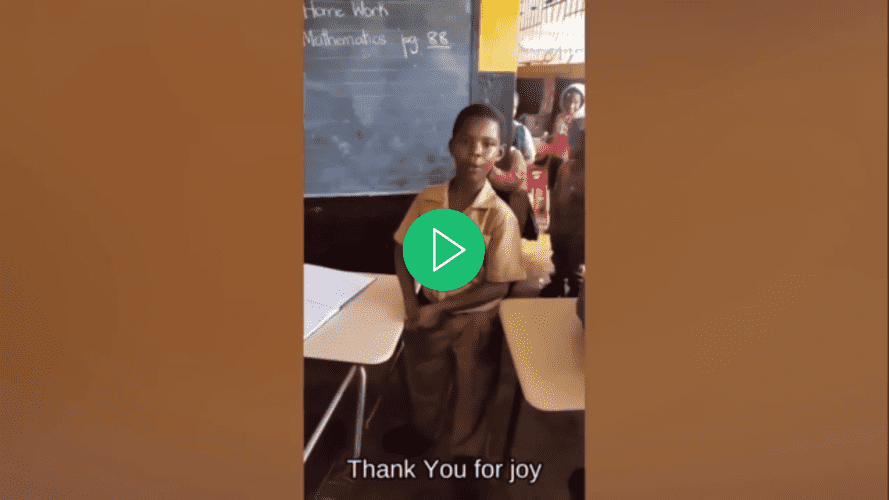
Prerequisites
In order to follow this tutorial the reader will need the following tools:
-
FFmpeg installed.
-
A basic understanding of Python. You can follow this tutorial series to learn how to code in Python.
Step 1 — Creating the Project Root Directory
In this section, you will create the project directory, download the input video, create and activate a virtual environment, and install the required Python packages.
Open a terminal window and navigate to a suitable location for your project. Run the following command to create the project directory:
- mkdir generate-subtitle
Navigate into the project directory:
- cd generate-subtitle
Download this edited video and store it in your project’s root directory as input.mp4. The video showcases a kid named Rushawn singing Jermaine Edward’s “Beautiful Day”. The edited video that you are going to use in this tutorial was taken from the following YouTube video:
Create a new virtual environment and name it env:
- python3 -m venv env
Activate the virtual environment:
- source env/bin/activate
Now, use the following command to install the packages needed to build this application:
- pip3 install faster-whisper ffmpeg-python
With the command above you installed the following libraries:
-
faster-whisper: is a redesigned version of OpenAI’s Whisper model that leverages CTranslate2, a high-performance inference engine for Transformer models. This implementation achieves up to four times greater speed than openai/whisper with comparable accuracy, all while consuming less memory. -
ffmpeg-python: is a Python library that provides a wrapper around the FFmpeg tool, allowing users to interact with FFmpeg functionalities in Python scripts easily. Through a Pythonic interface, it enables video and audio processing tasks, such as editing, conversion, and manipulation.
Run the following command to save packages that were installed using pip in the virtual environment in a file named requirements.txt:
- pip3 freeze > requirements.txt
The requirements.txt file should look similar to the following:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
In this section, you created the project directory, downloaded the input video that will be used in this tutorial, set up a virtual environment, activated it, and installed the necessary Python packages. In the next section, you will generate a transcript for the input video.
Step 2 — Generating the video transcript
In this section, you will create the Python script where the application will live. Inside this script, you will use the ffmpeg-python library to extract the audio track from the input video downloaded in the previous section and save it as a WAV file. Next, you will use the faster-whisper library to generate a transcript for the extracted audio.
In your project root directory, create a file named main.py and add the following code to it:
import time
import math
import ffmpeg
from faster_whisper import WhisperModel
input_video = "input.mp4"
input_video_name = input_video.replace(".mp4", "")
Here, the code begins by importing various libraries and modules, including time, math, ffmpeg from ffmpeg-python, and a custom module named WhisperModel from faster_whisper. These libraries will be used for video and audio processing, transcription, and subtitle generation.
Next, the code sets the input video file name, stores it in a constant named input_video, and then stores the video file name without the .mp4 extension in a constant named input_video_name. Setting the input file name here will allow you to work on multiple input videos without overwriting the subtitle and output video files generated for them.
Add the following code to the bottom of your main.py:
def extract_audio():
extracted_audio = f"audio-{input_video_name}.wav"
stream = ffmpeg.input(input_video)
stream = ffmpeg.output(stream, extracted_audio)
ffmpeg.run(stream, overwrite_output=True)
return extracted_audio
The code above defines a function named extract_audio() which is responsible for extracting the audio from the input video.
First, it sets the name of the audio that will be extracted to a name formed by appending audio- to the input video’s base name with a .wav extension, and stores this name in a constant named extracted_audio.
Next, the code calls the ffmpeg library’s ffmpeg.input() method to open the input video and creates an input stream object named stream.
The code then calls the ffmpeg.output() method to create an output stream object with the input stream and the defined extracted audio file name.
After setting the output stream, the code calls the ffmpeg.run() method, passing the output stream as a parameter to initiate the audio extraction process and save the audio file extracted in your project’s root directory. Additionally, a boolean parameter, overwrite_output=True, is included, to replace any pre-existing output file with the newly generated one if such a file already exists.
Finally, the code returns the name of the extracted audio file.
Add the following code below the extract_audio() function:
def run():
extracted_audio = extract_audio()
run()
Here, the code defines a function named run() and then calls it. This function calls all the functions needed to generate and add subtitles to a video.
Inside the function, the code calls the extract_audio() function to extract audio from a video and then stores the audio file name returned in a variable named extracted_audio.
Go back to your terminal and execute the following command to run the main.py script:
- python3 main.py
After executing the command above, the FFmpeg output will be shown in the terminal, and a file named audio-input.wav containing the audio extracted from the input video will be stored in your project’s root directory.
Go back to your main.py file and add the following code between the extract_audio() and run() functions:
def transcribe(audio):
model = WhisperModel("small")
segments, info = model.transcribe(audio)
language = info[0]
print("Transcription language", info[0])
segments = list(segments)
for segment in segments:
# print(segment)
print("[%.2fs -> %.2fs] %s" %
(segment.start, segment.end, segment.text))
return language, segments
The code above defines a function named transcribe responsible for transcribing the audio file extracted from the input video.
First, the code creates an instance of the WhisperModel object and sets the model type to small. OpenAI’s Whisper has the following model types: tiny, base, small, medium, and large. The tiny model is the smallest and fastest and the large model is the largest and slowest but most accurate.
Next, the code calls the model.transcribe() method with the extracted audio as an argument to retrieve the segments function and the audio information and stores them in variables named info and segments respectively. The segments function is a Python generator so the transcription will only start when the code iterates over it. The transcription can be run to completion by gathering the segments in a list or a for loop.
Next, the code stores the language detected in the audio in a constant named info and prints it to the console.
After printing the language detected, the code gathers the transcription segments in a list to run the transcription and stores the segments gathered in a variable also named segments. The code then loops over the transcription segments list and prints each segment’s start time, end time, and text to the console.
Finally, the code returns the language detected in the audio and the transcription segments.
Add the following code inside the run() function:
def run():
extracted_audio = extract_audio()
language, segments = transcribe(audio=extracted_audio)
The code added calls the transcribe function with the extracted audio as an argument and stores the values returned in constants named language, and segments.
Go back to your terminal and execute the following command to run the main.py script:
- python3 main.py
The first time you run this script the code will first download and cache the Whisper Small model, subsequent runs will be much faster.
After executing the command above you should see the following output in the console:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
The output above shows that the language detected in the audio is English (en). Additionally, it shows each transcription segment’s start and end time in seconds and text.
Warning: Although OpenAI’s Whisper speech recognition is very accurate it isn’t 100% accurate, it may be subject to limitations and occasional errors, particularly in challenging linguistic or audio scenarios. So always make sure to check the transcription manually.
In this section, you created a Python script for the application. Inside the script, ffmpeg-python was used to extract the audio from the downloaded video and save it as a WAV file. Then, the faster-whisper library was used to generate a transcript for the extracted audio. In the next section, you will generate a subtitle file based on the transcript and then you will add the subtitle to the video.
Step 3 — Generating and adding the subtitle to the video
In this section, first, you will understand what a subtitle file is and how it is structured. Next, you will use the transcription segments generated in the previous section to create a subtitle file. After creating the subtitle file, you will use the ffmpeg-python library to add the subtitle file to a copy of the input video.
Understanding Subtitles: Structure and Types
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
Subtitle Index: A sequential number indicating the order of the subtitle in the file.
-
Timecodes: Start and end time markers that specify when the subtitle text should be displayed. The timecodes are usually formatted as
HH:MM:SS,sss(hours, minutes, seconds, milliseconds). -
Subtitle Text: The actual text of the subtitle entry, representing spoken or written content. This text is displayed on the screen during the specified time interval.
For example, a subtitle entry in an SRT file might look like this:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
In this example, the index is 1, the timecodes indicate that the subtitle should be displayed from 10.5 seconds to 15 seconds, and the subtitle text is This is an example subtitle.
Subtitles can be divided into two primary types:
-
Soft subtitles: Also known as closed captions, are stored externally as separate files (such as SRT) and can be added or removed independently of the video. They provide viewer flexibility, allowing toggling, language switching, and customization of settings. However, their effectiveness relies on the video player’s support, and not all players universally accommodate soft subtitles.
-
Hard subtitles: Are permanently embedded into video frames during editing or encoding, remaining a fixed part of the video. While they ensure constant visibility, even on players lacking support for external subtitle files, modifications or turning them off require re-encoding the entire video, limiting user control
Creating the subtitle file
Go back to your main.py file and add the following code between the transcribe() and run() functions:
def format_time(seconds):
hours = math.floor(seconds / 3600)
seconds %= 3600
minutes = math.floor(seconds / 60)
seconds %= 60
milliseconds = round((seconds - math.floor(seconds)) * 1000)
seconds = math.floor(seconds)
formatted_time = f"{hours:02d}:{minutes:02d}:{seconds:01d},{milliseconds:03d}"
return formatted_time
Here, the code defines a function named format_time() which is responsible for converting a given transcription segment’s start and end time in seconds to a subtitle-compatible time format that displays hours, minutes, seconds, and milliseconds (HH:MM:SS,sss).
The code first calculates hours, minutes, seconds, and milliseconds from the given time in seconds, formats them accordingly and then returns the formatted time.
Add the following code between the format_time() and run() functions:
def generate_subtitle_file(language, segments):
subtitle_file = f"sub-{input_video_name}.{language}.srt"
text = ""
for index, segment in enumerate(segments):
segment_start = format_time(segment.start)
segment_end = format_time(segment.end)
text += f"{str(index+1)} \n"
text += f"{segment_start} --> {segment_end} \n"
text += f"{segment.text} \n"
text += "\n"
f = open(subtitle_file, "w")
f.write(text)
f.close()
return subtitle_file
The code added defines a function named generate_subtitle_file() which takes as parameters the language detected in the extracted audio and the transcription segments. This function is responsible for generating an SRT subtitle file based on the language and the transcription segments.
First, the code sets the name of the subtitle file to a name formed by appending sub- and the detected language to the input video’s base name with the “.srt” extension, and stores this name in a constant named subtitle_file. Additionally, the code defines a variable named text where you will store the subtitle entries.
Next, the code iterates through the transcribed segments, formats the start and end times using the format_time() function, uses these formatted values along with the segment index and text to create a subtitle entry, and then adds an empty line separate each subtitle entry.
Lastly, the code creates a subtitle file in your project root directory with the name set earlier, adds the subtitle entries to the file, and returns the subtitle file name.
Add the following code to the bottom of your run() function:
def run():
extracted_audio = extract_audio()
language, segments = transcribe(audio=extracted_audio)
subtitle_file = generate_subtitle_file(
language=language,
segments=segments
)
The code added calls the generate_subtitle_file() function with the detected language and transcription segments as arguments, and stores the subtitle file named returned in a constant named subtitle_file.
Go back to your terminal and execute the following command to run the main.py script:
- python3 main.py
After running the command above a subtitle file named sub-input.en.srt will be saved in your project’s root directory.
Open the sub-input.en.srt subtitle file and you should see something similar to the following:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
Adding subtitles to videos
Add the following code between the generate_subtitle_file() and the run() function:
def add_subtitle_to_video(soft_subtitle, subtitle_file, subtitle_language):
video_input_stream = ffmpeg.input(input_video)
subtitle_input_stream = ffmpeg.input(subtitle_file)
output_video = f"output-{input_video_name}.mp4"
subtitle_track_title = subtitle_file.replace(".srt", "")
if soft_subtitle:
stream = ffmpeg.output(
video_input_stream, subtitle_input_stream, output_video, **{"c": "copy", "c:s": "mov_text"},
**{"metadata:s:s:0": f"language={subtitle_language}",
"metadata:s:s:0": f"title={subtitle_track_title}"}
)
ffmpeg.run(stream, overwrite_output=True)
Here, the code defines a function named add_subtitle_to_video() which takes as parameters a boolean value used to determine if it should add a soft subtitle or hard subtitle, the subtitle file name, and the language detected in the transcription. This function is responsible for adding soft or hard subtitles to a copy of the input video.
First, the code uses the ffmpeg.input() method with the input video and subtitle file to create input stream objects for the input video and subtitle file and stores them in constants named video_input_stream and subtitle_input_stream respectively.
After creating the input streams, the code sets the name of the output video file to a name formed by appending output- to the input video’s base name with the “.mp4” extension, and stores this name in a constant named output_video. Additionally, sets the name of the subtitle track to the subtitle file name without the .srt extension and stores this name in a constant named subtitle_track_title.
Next, the code checks if the boolean soft_subtitle is set to True indicating that it should add a soft subtitle.
If that is the case, the code calls the ffmpeg.output() method to create an output stream object with the input streams, the output video file name, and the following options for the output video:
-
"c": "copy": It specifies that the video codec and other video parameters should be copied directly from the input to the output without re-encoding. -
"c:s": "mov_text": It specifies that the subtitle codec and parameters should also be copied from the input to the output without re-encoding.mov_textis a common subtitle codec used in MP4/MOV files. -
”metadata:s:s:0”: f"language={subtitle_language}": It sets the language metadata for the subtitle stream. The language is set to the value stored insubtitle_language -
"metadata:s:s:0": f"title={subtitle_track_title}": It sets the title metadata for the subtitle stream. The title is set to the value stored insubtitle_track_title
Finally, the code calls the ffmpeg.run() method, passing the output stream as a parameter to add the soft subtitle to the video and save the output video file in your project’s root directory.
Add the following code to the bottom of your add_subtitle_to_video() function:
def add_subtitle_to_video(soft_subtitle, subtitle_file, subtitle_language):
...
if soft_subtitle:
...
else:
stream = ffmpeg.output(video_input_stream, output_video,
vf=f"subtitles={subtitle_file}")
ffmpeg.run(stream, overwrite_output=True)
The highlighted code will run if the boolean soft_subtitle is set to False indicating that it should add a hard subtitle.
If that is the case, first, the code calls the ffmpeg.output() method to create an output stream object with the input video stream, the output video file name, and the vf=f"subtitles={subtitle_file}" parameter. The vf stands for “video filter”, and it is used to apply a filter to the video stream. In this case, the filter being applied is the addition of the subtitle.
Lastly, the code calls the ffmpeg.run() method, passing the output stream as a parameter to add the hard subtitle to the video and save the output video file in your project’s root directory.
Add the following highlighted code to the run() function:
def run():
extracted_audio = extract_audio()
language, segments = transcribe(audio=extracted_audio)
subtitle_file = generate_subtitle_file(
language=language,
segments=segments
)
add_subtitle_to_video(
soft_subtitle=True,
subtitle_file=subtitle_file,
subtitle_language=language
)
The highlighted code calls the add_subtitle_to_video() with the soft_subtitle parameter set to True, the subtitle file name, and the subtitle language to add a soft subtitle to a copy of the input video.
Go back to your terminal and execute the following command to run the main.py script:
- python3 main.py
After running the command above an output video file named output-input.mp4 will be saved in your project’s root directory.
Open the video using your preferred video player, select a subtitle for the video, and notice how the subtitle won’t be displayed until you select it:

Go back to the main.py file, navigate to the run() function, and in the add_subtitle_to_video() function call set the soft_subtitle parameter to False:
def run():
…
add_subtitle_to_video(
soft_subtitle=False,
subtitle_file=subtitle_file,
subtitle_language=language
)
Here, you set the soft_subtitle parameter to False to add hard subtitles to the video.
Go back to your terminal and execute the following command to run the main.py script:
- python3 main.py
After running the command above the output-input.mp4 video file located in your project’s root directory will be overwritten.
Open the video using your preferred video player, try to select a subtitle for the video, and notice how one isn’t available yet a subtitle is being displayed:

In this section, you gained an understanding of the structure of an SRT subtitle file and utilized the transcription segments from the previous section to create one. Following this, the ffmpeg-python library was used to add the generated subtitle file to the video.
Conclusion
In this tutorial, you used the ffmpeg-python and faster-whisper Python libraries to build an application capable of extracting audio from an input video, transcribing the extracted audio, generating a subtitle file based on the transcription, and adding the subtitle to a copy of the input video.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I help Businesses scale with AI x SEO x (authentic) Content that revives traffic and keeps leads flowing | 3,000,000+ Average monthly readers on Medium | Sr Technical Writer @ DigitalOcean | Ex-Cloud Consultant @ AMEX | Ex-Site Reliability Engineer(DevOps)@Nutanix
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Thank you for helpful article. The transcribe function has bug though. info is not a tuple, but a class, so you will need access the class property :
language = info.language
print("Transcription language", language)
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.