By Erin Glass
Senior Manager, DevEd
 unter Ubuntu 20.04")
Einführung
Der Elastic Stack (früher ELK Stack genannt) ist eine Sammlung von Open-Source-Software, die von Elastic produziert wird. Damit können Sie Protokolle, die aus beliebigen Quellen in beliebigen Formaten generiert werden, durchsuchen, analysieren und visualisieren – diese Praktik wird* zentrale Protokollierung* genannt. Zentrale Protokollierung kann dabei helfen, Probleme mit Ihren Servern oder Anwendungen zu identifizieren, da Sie so alle Protokolle an einem Ort durchsuchen können. Außerdem können Sie Probleme ermitteln, die mehrere Server umfassen, indem Sie ihre Protokolle für einen bestimmten Zeitraum miteinander korrelieren.
Der Elastic Stack verfügt über vier Hauptkomponenten:
- Elasticsearch: eine verteilte RESTful-Suchmaschine, die alle erfassten Daten speichert.
- Logstash: die Datenverarbeitungskomponente von Elastic Stack, die eingehende Daten an Elasticsearch sendet.
- Kibana: eine Weboberfläche zum Durchsuchen und Visualisieren von Protokollen.
- Beats: schlanke Datenversender mit einem Zweck, die Daten von Hunderten oder Tausenden von Geräten an Logstash oder Elasticsearch senden können.
In diesem Tutorial installieren Sie den Elastic Stack auf einem Ubuntu 20.04-Server. Sie erfahren, wie Sie alle Komponenten des Elastic Stacks installieren – darunter Filebeat, ein Beat, das zum Weiterleiten und Zentralisieren von Protokollen und Dateien dient – und so konfigurieren, dass Systemprotokolle gesammelt und visualisiert werden. Da Kibana in der Regel nur auf dem localhost verfügbar ist, verwenden wir außerdem Nginx als Proxy, sodass es über einen Webbrowser aufrufbar ist. Wir installieren alle diese Komponenten auf einem einzigen Server, den wir als Elastic Stack-Server bezeichnen werden.
Hinweis: Bei der Installation des Elastic Stacks müssen Sie im gesamten Stack die gleiche Version verwenden. In diesem Tutorial installieren wir die neuesten Versionen des gesamten Stacks (zum Zeitpunkt der Verfassung dieses Textes Elasticsearch 7.7.1, Kibana 7.7.1, Logstash 7.7.1 und Filebeat 7.7.1).
Voraussetzungen
Um dieses Tutorial zu absolvieren, benötigen Sie Folgendes:
-
Einen Ubuntu 20.04-Server mit 4 GB RAM und 2 CPUs, eingerichtet mit einem non-root sudo user. Sie können hierzu der Ersteinrichtung eines Servers mit Ubuntu 20.04 folgen. In diesem Tutorial arbeiten wir mit der Mindestmenge von CPUs und RAM, die zur Ausführung von Elasticsearch benötigt werden. Beachten Sie, dass die Menge von CPU, RAM und Speicher, die Ihr Elasticsearch-Server benötigt, von der Menge der Protokolle abhängt, die Sie erwarten.
-
Installiertes OpenJDK 11. Siehe Abschnitt Installieren der standardmäßigen JRE/JDK in our guide Installieren von Java mit Apt unter Ubuntu 20.04, um die Einrichtung vorzunehmen.
-
Nginx, installiert auf Ihrem Server; Nginx werden wir in diesem Leitfaden später als Reverseproxy für Kibana konfigurieren. Folgen Sie unserem Leitfaden Installieren von Nginx unter Ubuntu 20.04, um die Einrichtung vorzunehmen.
Da der Elastic Stack dazu dient, wertvolle Informationen über Ihren Server aufzurufen, auf die nicht autorisierte Benutzer nicht zugreifen sollen, sollten Sie Ihren Server unbedingt schützen, indem Sie ein TLS/SSL-Zertifikat installieren. Dieser Schutz ist optional, wird jedoch ausdrücklich empfohlen.
Da Sie im Laufe des Leitfadens jedoch Änderungen an Ihrem Nginx-Serverblock vornehmen werden, ist es wahrscheinlich sinnvoller, dem Leitfaden Let’s Encrypt unter Ubuntu 20.04 am Ende des zweiten Schritts dieses Tutorials zu folgen. Wenn Sie vor diesem Hintergrund planen, Let’s Encrypt auf Ihrem Server zu konfigurieren, benötigen Sie dazu Folgendes:
-
Einen vollständig qualifizierten Domänennamen (FQDN). In diesem Tutorial wird überall
your_domainverwendet. Sie können einen Domänennamen unter Namecheap günstig erwerben oder einen kostenlosen von Freenom herunterladen oder einfach die Domänenregistrierungsstelle Ihrer Wahl verwenden. -
Die beiden folgenden DNS-Einträge wurden für Ihren Server eingerichtet. Sie finden in dieser Einführung in DigitalOcean DNS Details dazu, wie Sie sie hinzufügen können.
- Einen A-Datensatz mit
your-domain, der auf die öffentliche IP-Adresse Ihres Servers verweist. - Einen A-Eintrag mit
www.your_domain, der auf die öffentliche IP-Adresse Ihres Servers verweist.
- Einen A-Datensatz mit
Schritt 1 — Installieren und Konfigurieren von Elasticsearch
Die Elasticsearch-Komponenten sind in Standard-Paket-Repositorys von Ubuntu nicht verfügbar. Sie können jedoch mit APT installiert werden, nachdem Sie die Paketquellliste von Elastic hinzugefügt haben.
Alle Pakete werden mit dem Signierschlüssel von Elasticsearch signiert, um das System vor Paket-Spoofing zu schützen. Pakete, die mit dem Schlüssel authentifiziert wurden, werden von Ihrem Paketmanager als vertrauenswürdig eingestuft. In diesem Schritt importieren Sie den öffentlichen GPG-Schlüssel von Elasticsearch und fügen die Paketquellliste von Elastic hinzu, um Elasticsearch zu installieren.
Verwenden Sie zunächst cURL, das Befehlszeilentool zur Übertragung von Daten mit URLs, um den öffentlichen GPG-Schlüssel von Elasticsearch in APT zu importieren. Beachten Sie, dass wir die Argumente -fsSL nutzen, um alle Fortschritte und möglichen Fehler stumm zu schalten (ausgenommen Serverfehler) und um zuzulassen, dass cURL bei einer Umleitung eine Anfrage an einem neuen Ort stellt. Leiten Sie die Ausgabe des cURL-Befehls in das APT-Schlüsselprogramm weiter, das den öffentlichen GPG-Schlüssel zu APT hinzufügt.
- curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Fügen Sie als Nächstes die Elastic-Quellliste in das Verzeichnis sources.list.d ein, in dem APT nach neuen Quellen sucht:
- echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Aktualisieren Sie als Nächstes Ihre Paketlisten, damit APT die neue Elastic-Quelle liest:
- sudo apt update
Installieren Sie dann Elasticsearch mit diesem Befehl:
- sudo apt install elasticsearch
Elasticsearch ist nun installiert und bereit für die Konfiguration. Verwenden Sie zur Bearbeitung der Konfigurationsdatei von Elasticsearch (elasticsearch.yml) Ihren bevorzugten Texteditor. Wir verwenden hier nano:
- sudo nano /etc/elasticsearch/elasticsearch.yml
Anmerkung: Die Konfigurationsdatei von Elasticsearch liegt im YAML-Format vor. Das bedeutet, dass wir das Einrückungsformat beibehalten müssen. Achten Sie darauf, dass Sie beim Bearbeiten der Datei keine zusätzlichen Leerzeichen hinzufügen.
Die Datei elasticsearch.yml bietet Konfigurationsoptionen für Cluster, Knoten, Pfade, Arbeitsspeicher, Netzwerk, Suche und Gateway. Die meisten dieser Optionen sind in der Datei vorkonfiguriert, aber Sie können sie je nach Ihren Bedürfnissen ändern. Im Sinne unserer Demonstration einer Konfiguration mit einem Server werden wir nur die Einstellungen für den Netzwerkhost anpassen.
Elasticsearch lauscht an Port 9200 auf Verkehr von überall. Sie werden externen Zugriff auf Ihre Elasticsearch-Instanz einschränken wollen, um zu verhindern, dass externe Personen Ihre Daten lesen oder Ihren Elasticsearch-Cluster mit der [REST-API] (https://de.wikipedia.org/wiki/Representational_State_Transfer) herunterfahren. Um Zugriff zu beschränken und damit die Sicherheit zu erhöhen, suchen Sie nach der Zeile, die network.host angibt, heben Sie die Kommentierung auf und ersetzen den Wert durch localhost, sodass die Zeile wie folgt aussieht:
. . .
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .
Wir haben localhost angegeben, damit Elasticsearch an allen Schnittstellen und gebundenen IPs lauscht. Wenn Sie möchten, dass nur an einer bestimmten Schnittstelle gelauscht werden soll, können Sie deren IP-Adresse an Stelle von localhost angeben. Speichern und schließen Sie elasticsearch.yml. Wenn Sie nano verwenden, können Sie dazu STRG+X drücken, gefolgt von Y und dann ENTER.
Das sind die Mindesteinstellungen, mit denen Sie anfangen können, um Elasticsearch zu nutzen. Sie können Elasticsearch jetzt zum ersten Mal starten.
Starten Sie den Elasticsearch-Dienst mit systemctl. Geben Sie Elasticsearch einige Momente zum Starten. Andernfalls erhalten Sie möglicherweise Fehlermeldungen, dass Sie keine Verbindung herstellen können.
- sudo systemctl start elasticsearch
Führen Sie als Nächstes den folgenden Befehl aus, damit Elasticsearch bei jedem Server-Boot gestartet wird:
- sudo systemctl enable elasticsearch
Sie können testen, ob Ihr Elasticsearch-Dienst ausgeführt wird, indem Sie eine HTTP-Anfrage senden:
- curl -X GET "localhost:9200"
Sie erhalten eine Antwort, die einige grundlegende Informationen zu Ihrem lokalen Knoten enthält und in etwa wie folgt aussieht:
Output{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qqhFHPigQ9e2lk-a7AvLNQ",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Nachdem Elasticsearch ausgeführt wird, installieren wir nun Kibana, die nächste Komponente des Elastic Stacks.
Schritt 2 — Installieren und Konfigurieren des Kibana-Dashboards
Laut der offiziellen Dokumentation sollten Sie Kibana erst nach der Installation von Elasticsearch installieren. Durch eine Installation in dieser Reihenfolge wird sichergestellt, dass die Komponenten, auf die die einzelnen Produkte angewiesen sind, korrekt eingerichtet werden.
Da Sie die Elastic-Paketquelle bereits im vorherigen Schritt hinzugefügt haben, können Sie die verbleibenden Komponenten des Elastic Stacks einfach mit apt installieren:
- sudo apt install kibana
Aktivieren und starten Sie dann den Kibana-Dienst:
- sudo systemctl enable kibana
- sudo systemctl start kibana
Da Kibana so konfiguriert ist, dass nur an localhost gelauscht wird, müssen wir einen Reverseproxy einrichten, um externen Zugriff darauf zu ermöglichen. Dazu verwenden wir Nginx, das bereits auf Ihrem Server installiert sein sollte.
Verwenden Sie zunächst den Befehl openssl, um einen administrativen Kibana-Benutzer zu erstellen, den Sie für den Zugriff auf die Kibana-Weboberfläche verwenden werden. Als Beispiel nennen wir dieses Konto kibanaadmin; für mehr Sicherheit empfehlen wir aber, einen nicht standardmäßigen Namen für Ihren Benutzer zu wählen, der sich nur schwer erraten lässt.
Mit dem folgenden Befehl werden der administrative Kibana-Benutzer und das Passwort erstellt und in der Datei htpasswd.users gespeichert. Sie werden Nginx so konfigurieren, dass dieser Benutzername und das Passwort erforderlich sind und die Datei vorübergehend gelesen wird:
- echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
Geben Sie in der Eingabeaufforderung ein Passwort ein und bestätigen Sie es. Merken oder notieren Sie sich die Anmeldedaten, da Sie sie benötigen werden, um auf die Kibana-Weboberfläche zuzugreifen.
Als Nächstes erstellen wir eine Nginx-Serverblockdatei. Als Beispiel werden wir diese Datei als your_domain bezeichnen; vielleicht finden Sie es jedoch hilfreich, Ihrer Datei einen beschreibenden Namen zu geben. Wenn Sie für diesen Server beispielsweise einen FQDN und DNS-Einträge eingerichtet haben, könnten Sie diese Datei nach Ihrem FQDN benennen.
Erstellen Sie mit nano oder Ihrem bevorzugten Texteditor die Nginx-Serverblockdatei:
- sudo nano /etc/nginx/sites-available/your_domain
Fügen Sie der Datei den folgenden Codeblock hinzu; vergessen Sie dabei nicht, your_domain durch den FQDN oder die öffentliche IP-Adresse Ihres Servers zu ersetzen. Dieser Code konfiguriert Nginx so, dass HTTP-Datenverkehr Ihres Servers an die Kibana-Anwendung geleitet wird, die an localhost:5601 lauscht. Außerdem konfiguriert er Nginx so, dass die Datei htpasswd.users gelesen und eine grundlegende Authentifizierung vorgeschrieben wird.
Hinweis: Wenn Sie das Nginx-Voraussetzungstutorial bis zum Ende befolgt haben, haben Sie diese Datei möglicherweise bereits erstellt und mit Inhalten ausgefüllt. Löschen Sie in diesem Fall alle vorhandenen Inhalte in der Datei, bevor Sie Folgendes hinzufügen:
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Wenn Sie fertig sind, speichern und schließen Sie die Datei.
Aktivieren Sie als Nächstes die neue Konfiguration, indem Sie eine symbolische Verknüpfung zum Verzeichnis sites-enabled erstellen. Wenn Sie bereits eine Serverblockdatei mit dem gleichen Namen in der Nginx-Voraussetzung erstellt haben, müssen Sie diesen Befehl nicht ausführen:
- sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
Prüfen Sie die Konfiguration dann auf Syntaxfehler:
- sudo nginx -t
Wenn in Ihrer Ausgabe Fehler angezeigt werden, vergewisserrn Sie sich noch einmal, dass die in Ihrer Konfigurationsdatei platzierten Inhalte richtig hinzugefügt wurden. Sobald Sie sehen, dass in der Ausgabe syntax is ok (Syntax in Ordnung) steht, fahren Sie fort und starten Sie den Nginx-Dienst neu:
- sudo systemctl reload nginx
Wenn Sie den Leitfaden zur Servereinrichtung befolgt haben, sollte Ihre UFW-Firewall aktiviert sein. Um Verbindungen zu Nginx zu ermöglichen, können wir die Regeln anpassen, indem wir Folgendes eingeben:
- sudo ufw allow 'Nginx Full'
Hinweis: Wenn Sie dem Nginx-Voraussetzungstutorial gefolgt sind, haben Sie ggf. eine UFW-Regel erstellt, um das Profil Nginx HTTP über die Firewall zuzulassen. Da das Profil Nginx Full sowohl HTTP- als auch HTTPS-Datenverkehr über die Firewall zulässt, können Sie die von Ihnen im Voraussetzungstutorial erstellte Regel problemlos löschen. Führen Sie dazu folgenden Befehl aus:
- sudo ufw delete allow 'Nginx HTTP'
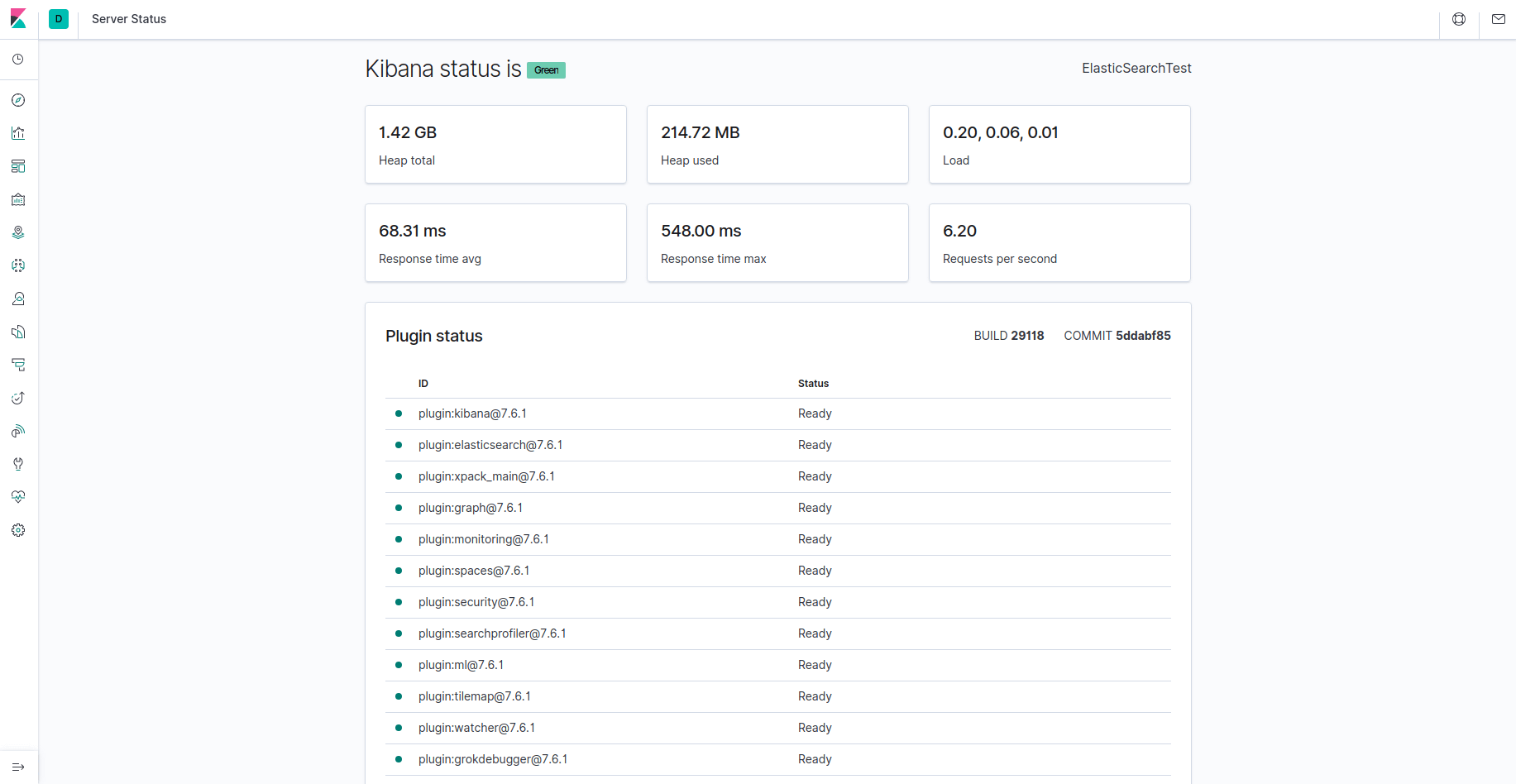
Kibana ist nun über Ihren FQDN oder die öffentliche IP-Adresse des Elastic Stack-Servers zugänglich. Sie können die Statusseite des Kibana-Servers überprüfen, indem Sie zur folgenden Adresse navigieren und Ihre Anmeldedaten eingeben, wenn Sie dazu aufgefordert werden:
http://your_domain/status
Auf dieser Statusseite werden Informationen zur Ressourcennutzung des Servers angezeigt und die installierten Plugins aufgelistet.
Hinweis: Wie im Voraussetzungsbereich erwähnt, sollten Sie auf Ihrem Server SSL/TLS aktivieren. Sie können dem Leitfaden zu Let’s Encrypt folgen, um unter Ubuntu 20.04 ein kostenloses SSL-Zertifikat für Nginx zu erhalten. Nach der Erlangung Ihrer SSL/TLS-Zertifikate können Sie zurückkehren und dieses Tutorial abschließen.
Nach der Installation des Kibana-Dashboards installieren wir nun die nächste Komponente: Logstash.
Schritt 3 — Installieren und Konfigurieren von Logstash
Zwar kann Beats Daten direkt an die Elasticsearch-Datenbank senden, doch ist es üblich, Logstash zur Verarbeitung der Daten zu verwenden. So können Sie flexibler Daten aus verschiedenen Quellen erfassen, in ein einheitliches Format umwandeln und in eine andere Datenbank exportieren.
Installieren Sie Logstash mit diesem Befehl:
- sudo apt install logstash
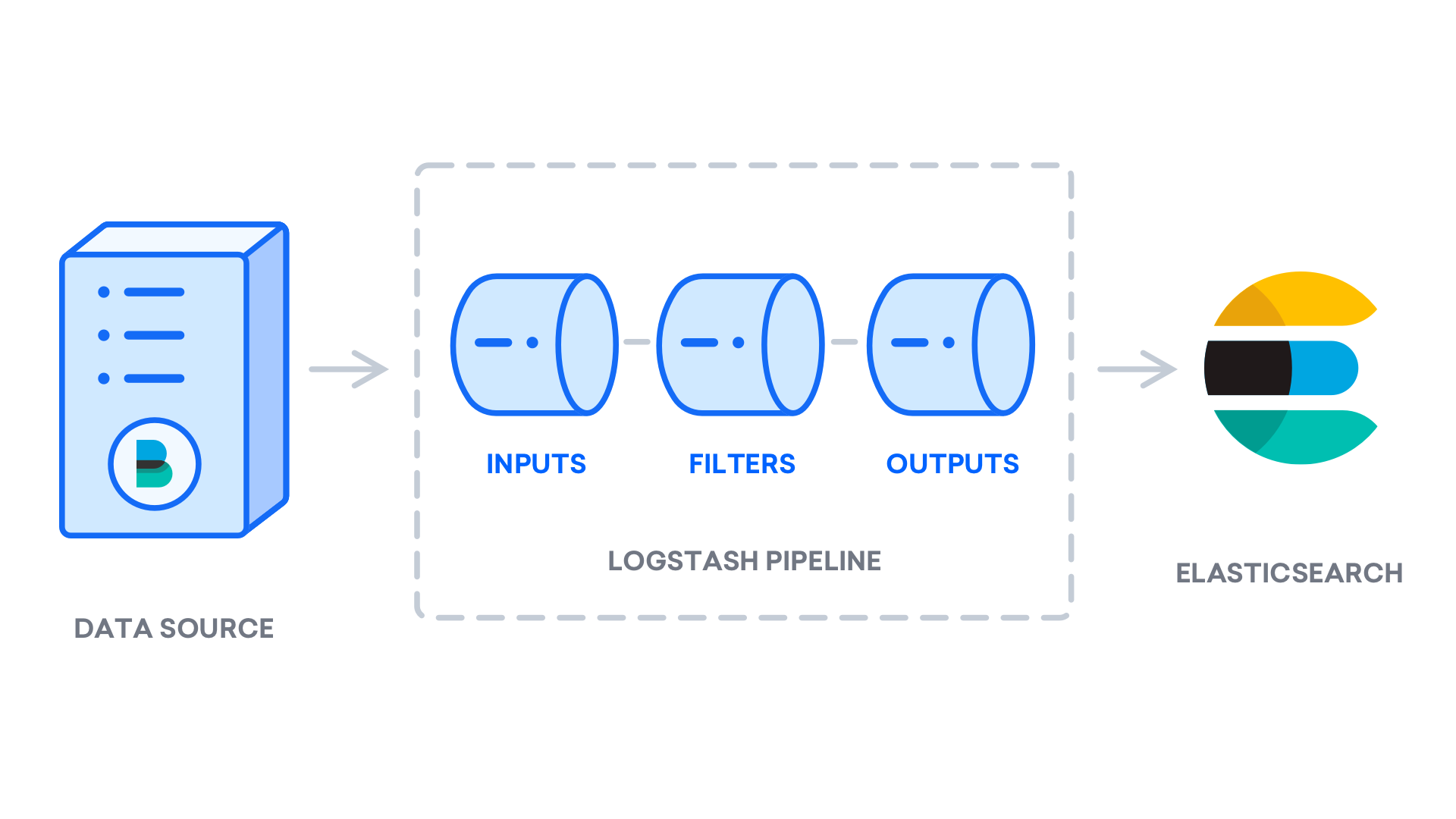
Nach der Installation von Logstash können Sie mit der Konfiguration fortfahren. Die Konfigurationsdateien von Logstash befinden sich im Verzeichnis /etc/logstash/conf.d. Weitere Informationen zur Konfigurationssyntax finden Sie in der von Elastic bereitgestellten Konfigurationsreferenz. Beim Konfigurieren der Datei ist es hilfreich, sich Logstash als Pipeline vorzustellen, die Daten an einem Ende annimmt, auf die eine oder andere Weise verarbeitet und dann an das Ziel sendet (in diesem Fall an Elasticsearch). Eine Logstash-Pipeline verfügt über zwei erforderliche Elemente (input und output) sowie ein optionales Element (filter). Die Input-Plugins konsumieren Daten aus einer Quelle, die Filter-Plugins verarbeiten die Daten und die Output-Plugins schreiben die Daten an ein Ziel.
Erstellen Sie eine Konfigurationsdatei namens 02-beats-input.conf, in der Sie Ihren Filebeat-Input einrichten werden:
- sudo nano /etc/logstash/conf.d/02-beats-input.conf
Geben Sie die folgende input-Konfiguration ein. Dadurch wird ein beats-Input angegeben, der an TCP-Port 5044 lauschen wird.
input {
beats {
port => 5044
}
}
Speichern und schließen Sie die Datei.
Erstellen Sie als Nächstes eine Konfigurationsdatei namens 30-elasticsearch-output.conf:
- sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
Fügen Sie die folgende output-Konfiguration ein. Im Wesentlichen konfiguriert dieser Output Logstash so, dass die Beats-Daten in Elasticsearch, das bei localhost:9200 ausgeführt wird, gespeichert werden – und zwar in einem nach dem verwendeten Beat benannten Index. Der in diesem Tutorial verwendete Beat ist Filebeat:
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
}
Speichern und schließen Sie die Datei.
Testen Sie Ihre Logstash-Konfiguration mit diesem Befehl:
- sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
Wenn keine Syntaxfehler vorhanden sind, wird Ihre Ausgabe nach ein paar Sekunden Config Validation Result: OK. Exiting Logstash anzeigen. Wenn Sie das nicht in Ihrer Ausgabe sehen, prüfen Sie auf Fehler, die in Ihrer Ausgabe aufgeführt sind, und aktualisieren Sie Ihre Konfiguration, um sie zu korrigieren. Beachten Sie, dass Sie Warnungen von OpenJDK erhalten werden; diese sollten jedoch keine Probleme verursachen und können ignoriert werden.
Wenn Ihr Konfigurationstest erfolgreich war, starten und aktivieren Sie Logstash, um die Konfigurationsänderungen anzuwenden:
- sudo systemctl start logstash
- sudo systemctl enable logstash
Nachdem Logstash nun korrekt ausgeführt wird und vollständig konfiguriert ist, installieren wir Filebeat.
Schritt 4 — Installieren und Konfigurieren von Filebeat
Der Elastic Stack verwendet verschiedene schlanke Datenversender namens Beats, um Daten aus verschiedenen Quellen zu erfassen und zu Logstash oder Elasticsearch zu transportieren. Hier sind die Beats, die derzeit bei Elastic verfügbar sind:
- Filebeat: erfasst und versendet Protokolldateien.
- Metricbeat: erfasst Metriken aus Ihren Systemen und Diensten.
- Packetbeat: erfasst und analysiert Netzwerkdaten.
- Winlogbeat: erfasst Windows-Ereignisprotokolle.
- Auditbeat: erfasst Linux-Audit-Frameworkdaten und überwacht die Dateiintegrität.
- Heartbeat: überwacht Dienste durch aktive Sondierung auf ihre Verfügbarkeit.
In diesem Tutorial werden wir Filebeat verwenden, um lokale Protokolle an unseren Elastic Stack weiterzuleiten.
Installieren Sie Filebeat mit apt:
- sudo apt install filebeat
Konfigurieren Sie als Nächstes Filebeat so, dass eine Verbindung zu Logstash hergestellt wird. Hier werden wir die Beispielkonfigurationsdatei ändern, die mit Filebeat geliefert wird.
Öffnen Sie die Filebeat-Konfigurationsdatei:
- sudo nano /etc/filebeat/filebeat.yml
Hinweis: Wie bei Elasticsearch liegt die Konfigurationsdatei von Filebeat im YAML-Format vor. Das bedeutet, dass eine richtige Einrückung von entscheidender Bedeutung ist; stellen Sie also sicher, dass Sie die gleiche Anzahl von Leerzeichen verwenden, die in diesen Anweisungen angegeben ist.
Filebeat unterstützt verschiedene Ausgaben; Sie werden in der Regel Ereignisse jedoch nur zur weiteren Verarbeitung direkt an Elasticsearch oder Logstash senden. In diesem Tutorial verwenden wir Logstash, um eine weitere Verarbeitung der von Filebeat erfassten Daten vorzunehmen. Filebeat muss Daten nicht direkt an Elasticsearch senden; lassen Sie uns diese Ausgabe also deaktivieren. Suchen Sie dazu nach dem Abschnitt output.elasticsearch und kommentieren Sie die folgenden Zeilen aus, indem Sie ihnen ein # voranstellen:
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...
Konfigurieren Sie dann den Abschnitt output.logstash. Heben Sie die Kommentierung der Zeilen output.logstash: und hosts: ["localhost:5044"] auf, indem Sie das # entfernen. Dadurch wird Filebeat so konfiguriert, dass auf Ihrem Elastic Stack-Server an Port 5044 eine Verbindung hergestellt wird. Das ist der Port, für den wir zuvor ein Logstash-Input angegeben haben:
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
Speichern und schließen Sie die Datei.
Die Funktionalität von Filebeat kann mit Filebeat-Modulen erweitert werden. In diesem Tutorial werden wir das system-Modul verwenden, das Protokolle erfasst und analysiert, die vom Systemprotokollierungsdienst gängiger Linux-Distributionen erstellt werden.
Aktivieren wir es:
- sudo filebeat modules enable system
Sie können eine Liste aktivierter und deaktivierter Module anzeigen, indem Sie Folgendes ausführen:
- sudo filebeat modules list
Sie sehen eine Liste, die der folgenden ähnelt:
OutputEnabled:
system
Disabled:
apache2
auditd
elasticsearch
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
traefik
...
Standardmäßig ist Filebeat so konfiguriert, dass für die syslog- und authorization-Protokolle Standardpfade verwendet werden. Im Fall dieses Tutorials müssen Sie in der Konfiguration nichts ändern. Sie können die Parameter des Moduls in der Konfigurationsdatei /etc/filebeat/modules.d/system.yml anzeigen.
Als Nächstes müssen wir die Filebeat-Aufnahme-Pipelines einrichten, die die Protokolldaten analysieren, bevor sie über Logstash an Elasticsearch gesendet werden. Um die Aufnahme-Pipeline für das system-Modul zu laden, geben Sie folgenden Befehl ein:
- sudo filebeat setup --pipelines --modules system
Laden Sie als Nächstes die Indexvorlage in Elasticsearch. Ein Elasticsearch-Index ist eine Sammlung von Dokumenten, die ähnliche Merkmale aufweisen. Indizes werden mit einem Namen identifiziert, der bei der Ausführung verschiedener Operationen darin zum Verweisen auf den Index verwendet wird. Die Indexvorlage wird bei Erstellung eines neuen Index automatisch angewendet.
Um die Vorlage zu laden, verwenden Sie folgenden Befehl:
- sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
OutputIndex setup finished.
Filebeat ist mit beispielhaften Kibana-Dashboards ausgestattet, mit denen Sie Filebeat-Daten in Kibana visualisieren können. Bevor Sie die Dashboards verwenden können, müssen Sie das Indexmuster erstellen und die Dashboards in Kibana laden.
Während die Dashboards geladen werden, verbindet sich Filebeat mit Elasticsearch, um Versionsdaten zu überprüfen. Um Dashboards zu laden, wenn Logstash aktiviert ist, müssen Sie die Logstash-Ausgabe deaktivieren und die Elasticsearch-Ausgabe aktivieren:
- sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
Sie sollten eine Ausgabe erhalten, die der folgenden ähnelt:
OutputOverwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
Jetzt können Sie Filebeat starten und aktivieren:
- sudo systemctl start filebeat
- sudo systemctl enable filebeat
Wenn Sie Ihren Elastic Stack richtig eingerichtet haben, wird Filebeat mit dem Versand Ihrer syslog- und authorization-Protokolle an Logstash beginnen, was die Daten dann in Elasticsearch laden wird.
Um zu prüfen, ob Elasticsearch diese Daten tatsächlich erhält, fragen Sie den Filebeat-Index mit folgendem Befehl ab:
- curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
Sie sollten eine Ausgabe erhalten, die der folgenden ähnelt:
Output...
{
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4040,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.7.1-2020.06.04",
"_type" : "_doc",
"_id" : "FiZLgXIB75I8Lxc9ewIH",
"_score" : 1.0,
"_source" : {
"cloud" : {
"provider" : "digitalocean",
"instance" : {
"id" : "194878454"
},
"region" : "nyc1"
},
"@timestamp" : "2020-06-04T21:45:03.995Z",
"agent" : {
"version" : "7.7.1",
"type" : "filebeat",
"ephemeral_id" : "cbcefb9a-8d15-4ce4-bad4-962a80371ec0",
"hostname" : "june-ubuntu-20-04-elasticstack",
"id" : "fbd5956f-12ab-4227-9782-f8f1a19b7f32"
},
...
Wenn Ihre Ausgabe insgesamt 0 Treffer anzeigt, lädt Elasticsearch keine Protokolle unter dem Index, den Sie angefragt haben; in diesem Fall müssen Sie Ihre Einrichtung auf Fehler prüfen. Wenn Sie die erwartete Ausgabe erhalten haben, fahren Sie mit dem nächsten Schritt fort, in dem Sie erfahren werden, wie Sie durch einige Kibana-Dashboards navigieren können.
Schritt 5 — Erkunden von Kibana-Dashboards
Kehren wir zurück zur Kibana-Weboberfläche, die wir zuvor installiert haben.
Rufen Sie in einem Webbrowser den FQDN oder die öffentliche IP-Adresse Ihres Elastic Stack-Servers auf. Wenn Ihre Sitzung unterbrochen wurde, müssen Sie die in Schritt 2 festgelegten Anmeldedaten erneut eingeben. Sobald Sie sich angemeldet haben, sollten Sie die Homepage von Kibana angezeigt werden:
Klicken Sie in der linken Navigationsleiste auf den Link Discover (Erkunden) (Sie müssen möglicherweise links unten auf das Symbol zum Erweitern klicken, um die Elemente des Navigationsmenüs anzuzeigen). Wählen Sie auf der Seite Discover das vordefinierte filebeat-*-Indexmuster aus, um Filebeat-Daten anzuzeigen. Standardmäßig werden Ihnen die Protokolldaten der letzten 15 Minuten angezeigt. Im Folgenden sehen Sie ein Histogramm mit Protokollereignissen und einige Protokollnachrichten:
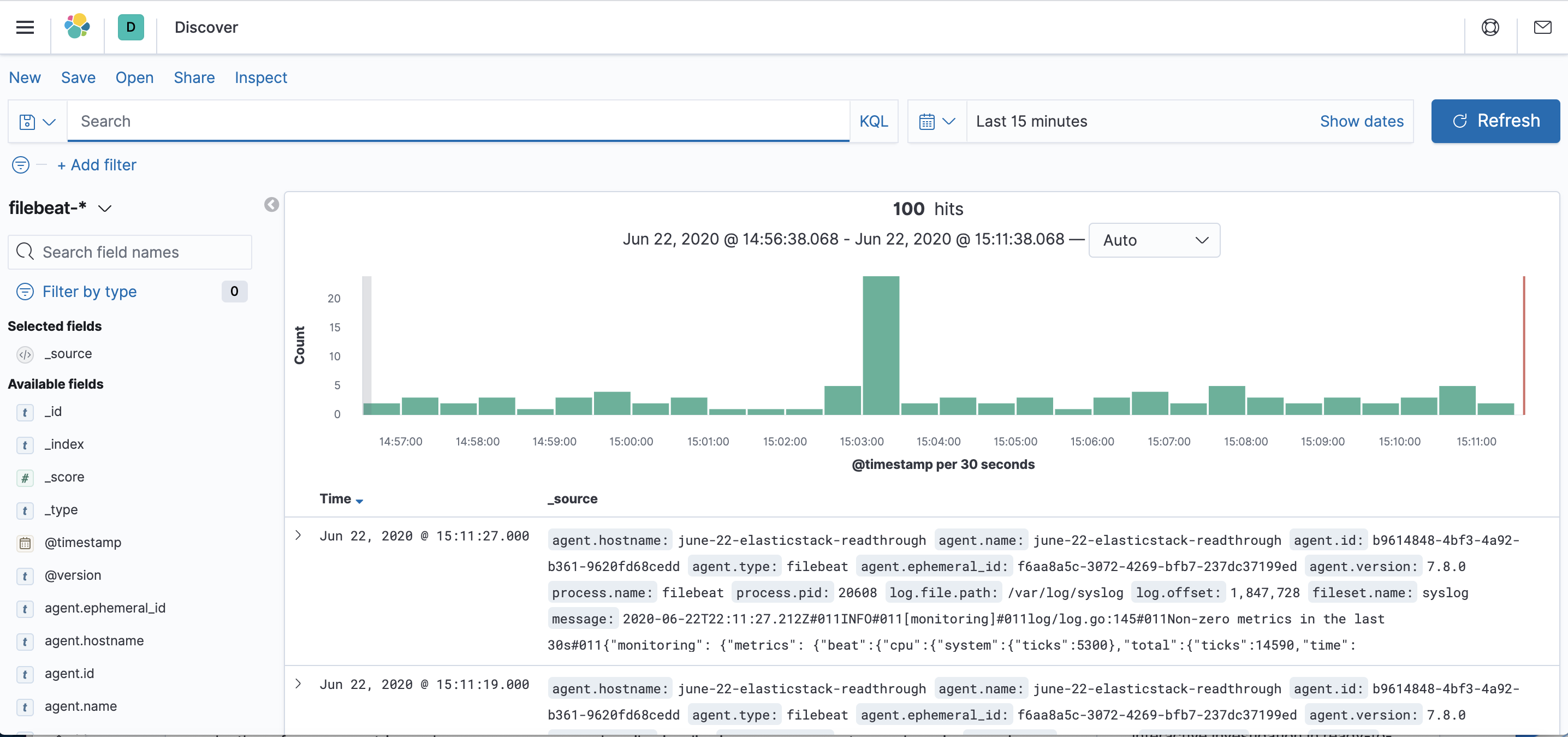
Hier können Sie Ihre Protokolle durchsuchen sowie Ihr Dashboard anpassen. An diesem Punkt wird es hier jedoch nicht viel geben, da Sie nur Syslogs von Ihrem Elastic Stack-Server erfassen.
Verwenden Sie den linken Bereich, um zur Dashboard-Seite zu navigieren und nach den Filebeat System-Dashboards zu suchen. Nun können Sie die Beispiel-Dashboards auswählen, die mit dem system-Modul von Filebeat geliefert werden.
Beispielsweise können Sie anhand Ihrer syslog-Nachrichten genaue Statistiken anzeigen:
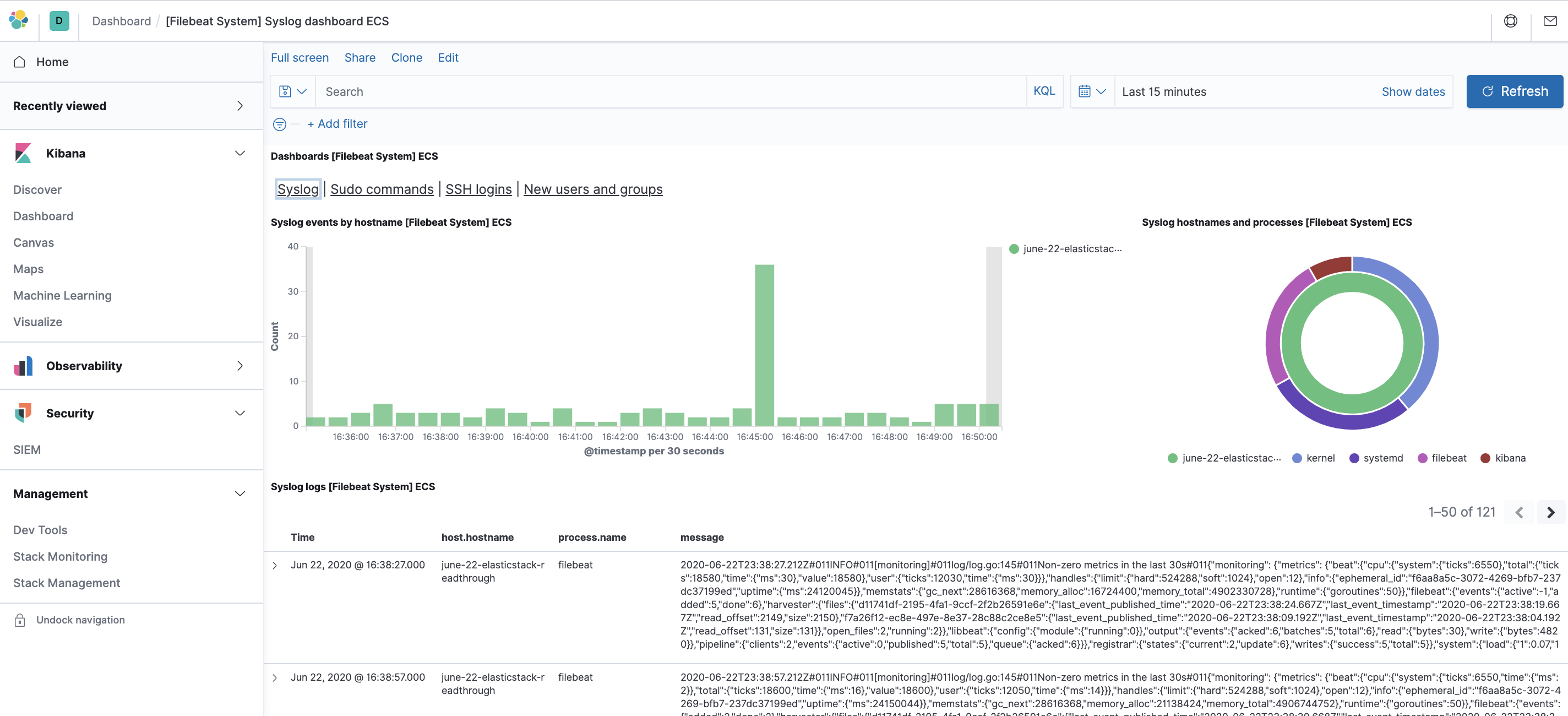
Außerdem können Sie sehen, welche Benutzer den sudo-Befehl verwendet haben und wann:
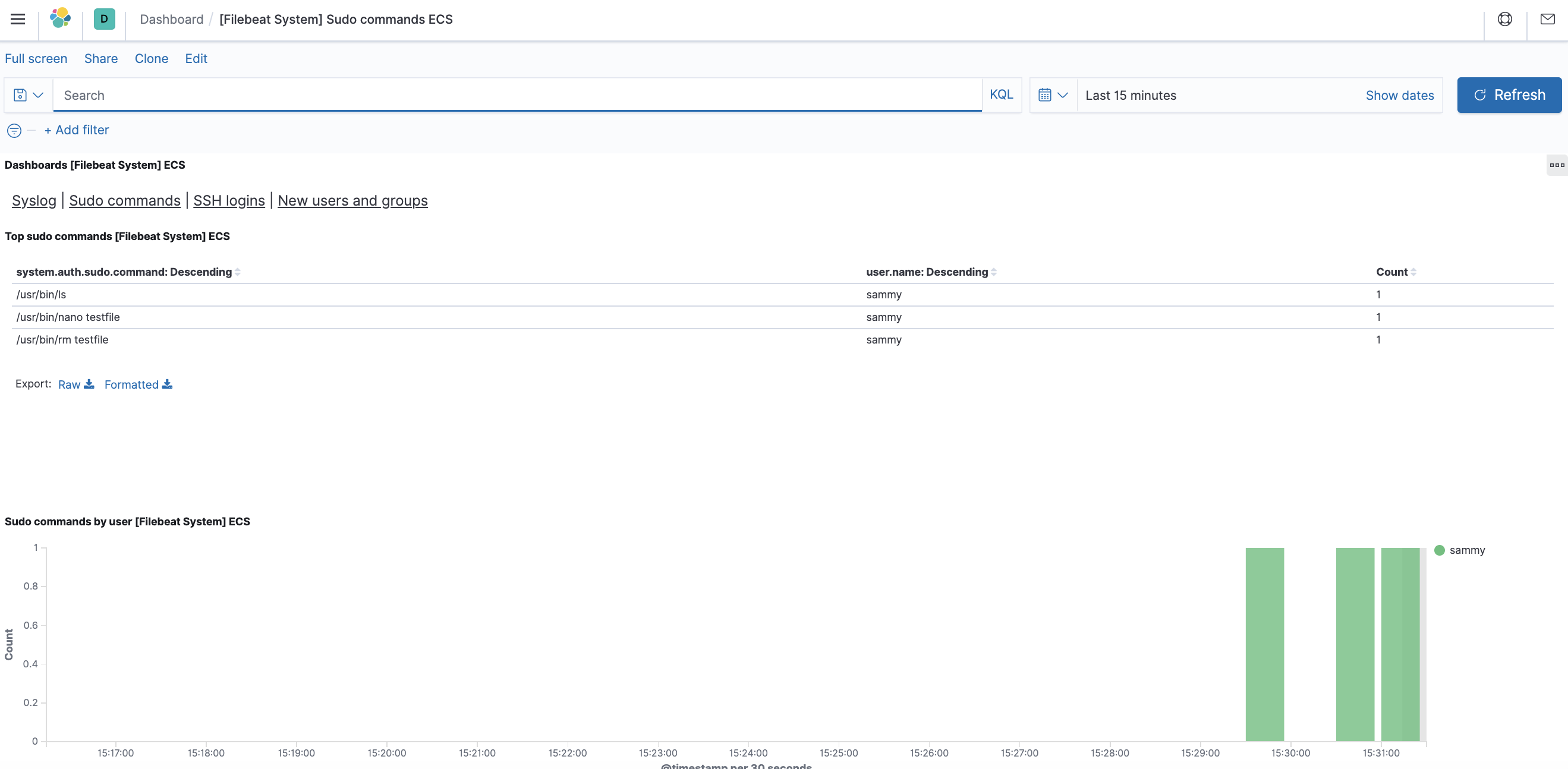
Kibana verfügt über viele andere Funktionen wie Diagrammerstellung und Filter; sehen Sie sich diese Funktionen bei Interesse genauer an.
Zusammenfassung
In diesem Tutorial haben Sie gelernt, wie Sie den Elastic Stack installieren und so konfigurieren können, dass er Systemprotokolle erfasst und analysiert. Denken Sie daran, dass Sie mit Beats fast jede Art von Protokoll oder indizierten Daten an Logstash senden können. Die Daten werden jedoch noch nützlicher, wenn sie mit einem Logstash-Filter analysiert und strukturiert werden; dabei werden die Daten in ein konsistentes Format umgewandelt, das von Elasticsearch leicht gelesen werden kann.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Open source advocate and lover of education, culture, and community.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.