By Erin Glass
Senior Manager, DevEd
 sur Ubuntu 20.04")
Introduction
Elastic Stack - anciennement connue sous le nom de ELK Stack - est une collection de logiciels open-source produite par Elastic qui vous permet de rechercher, d’analyser et de visualiser des journaux générés à partir de n’importe quelle source dans n’importe quel format, une pratique connue sous le nom de journalisation centralisée. La journalisation centralisée peut être utile lorsque vous tentez d’identifier des problèmes avec vos serveurs ou vos applications, car elle vous permet de consulter tous vos journaux en un seul endroit. Elle est également utile car elle vous permet d’identifier les problèmes qui concernent plusieurs serveurs, en corrélant leurs journaux pendant une période spécifique.
La Elastic Stack comporte quatre composants principaux :
- Elasticsearch : un moteur de recherche RESTful distribué qui stocke toutes les données recueillies.
- Logstash : le composant traitement des données de Elastic Stack, qui envoie les données entrantes à Elasticsearch.
- Kibana : une interface web pour la recherche et la visualisation des journaux.
- Beats : des expéditeurs de données légers et à usage unique qui peuvent envoyer des données provenant de centaines ou de milliers de machines à Logstash ou à Elasticsearch.
Au cours de ce tutoriel, vous allez installer l’Elastic Stack sur un serveur Ubuntu 20.04. Vous apprendrez comment installer tous les composants de l’Elastic Stack - y compris Filebeat, un Beat utilisé pour transmettre et centraliser les journaux et les fichiers - et les configurer pour rassembler et visualiser les journaux du système. En outre, comme Kibana n’est normalement disponible que sur le localhost, nous utiliserons Nginx comme proxy afin qu’il soit accessible via un navigateur web. Nous installerons tous ces composants sur un seul serveur, que nous appellerons notre serveur Elastic Stack.
Note : lorsque vous installez l’ElasticStack, vous devez utiliser la même version sur l’ensemble de la pile. Dans ce tutoriel, nous allons installer les dernières versions de la pile entière qui sont, au moment de la rédaction de ce document, Elasticsearch 7.7.1, Kibana 7.7.1, Logstash 7.7.1 et Filebeat 7.7.1.
Conditions préalables
Pour terminer ce tutoriel, vous aurez besoin des éléments suivants :
-
Un serveur Ubuntu 20.04 avec 4 Go de RAM et 2 CPU installé avec un utilisateur sudo non root. Vous pouvez y parvenir en suivant la configuration initiale du serveur avec Ubuntu 20.04. Pour ce tutoriel, nous travaillerons avec la quantité minimale de CPU et de RAM requise pour exécuter Elasticsearch. Notez que la quantité de CPU, de RAM et de stockage dont votre serveur Elasticsearch aura besoin dépend du volume de journaux que vous prévoyez.
-
OpenJDK 11 installé. Voir la section Installation du JRE/JDK par défaut dans notre guide Comment installer Java avec Apt sur Ubuntu 20.04 pour configurer cela.
-
Nginx installé sur votre serveur, que nous configurerons plus loin dans ce guide comme un proxy inverse pour Kibana. Suivez notre guide Comment installer Nginx sur Ubuntu 20.04 pour le configurer.
En outre, comme l’Elastic Stack est utilisé pour accéder à des informations précieuses sur votre serveur auxquelles vous ne voudriez pas que des utilisateurs non autorisés accèdent, il est important que vous mainteniez votre serveur sécurisé en installant un certificat TLS/SSL. Cette action est facultative mais fortement encouragée.
Cependant, comme vous allez finalement apporter des modifications à votre bloc serveur Nginx au cours de ce guide, il serait sans doute plus logique que vous exécutiez les étapes du guide Let’s Encrypt sur Ubuntu 20.04 à la fin de la deuxième étape de ce tutoriel. Dans cette optique, si vous prévoyez de configurer Let’s Encrypt sur votre serveur, vous devrez au préalable mettre en place les éléments suivants :
-
Un nom de domaine entièrement qualifié (FQDN). Ce tutoriel utilisera
your_domain. Vous pouvez acheter un nom de domaine sur Namecheap, en obtenir un gratuitement sur Freenom, ou utiliser le bureau d’enregistrement de domaine de votre choix. -
Les deux enregistrements DNS suivants ont été configurés pour votre serveur. Vous pouvez suivre cette introduction à DigitalOcean DNS pour savoir comment les ajouter.
- Un enregistrement A avec
your_domainpointant sur l’adresse IP publique de votre serveur. - Un enregistrement A avec
www.your_domain pointant à l’adresse IP publique de votre serveur.
- Un enregistrement A avec
Étape 1 — Installation et configuration d’Elasticsearch
Les composants Elasticsearch ne sont pas disponibles dans les dépôts de paquets par défaut d’Ubuntu. Ils peuvent cependant être installés avec APT après avoir ajouté la liste des sources des paquets d’Elastic.
Tous les paquets sont signés avec la clé de signature Elasticsearch afin de protéger votre système contre l’usurpation de paquets. Les paquets qui ont été authentifiés à l’aide de la clé seront considérés comme fiables par votre gestionnaire de paquets. Dans cette étape, vous allez importer la clé GPG publique d’Elasticsearch et ajouter la liste des sources du paquet Elastic afin d’installer Elasticsearch.
Pour commencer, utilisez cURL, l’outil de ligne de commande pour le transfert de données avec URL pour importer la clé GPG publique d’Elasticsearch dans APT. Notez que nous utilisons les arguments -fsSL pour faire taire toute progression et toute erreur éventuelle (sauf en cas de panne de serveur) et pour permettre à cURL d’effectuer une requête sur un nouvel emplacement s’il est redirigé. Transmettez la sortie de la commande cURL au programme apt-key qui ajoute la clé GPG publique à l’APT.
- curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Ensuite, ajoutez la liste des sources Elastic au répertoire sources.list.d où APT cherchera de nouvelles sources :
- echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Ensuite, mettez à jour vos listes de paquets afin qu’APT puisse lire la nouvelle source Elastic :
- sudo apt update
Installez ensuite Elasticsearch avec cette commande :
- sudo apt install elasticsearch
Elasticsearch est maintenant installé et prêt à être configuré. Utilisez votre éditeur de texte préféré pour modifier le fichier de configuration principal d’Elasticsearch, elasticsearch.yml. Ici, nous utiliserons nano :
- sudo nano /etc/elasticsearch/elasticsearch.yml
Note : Le fichier de configuration d’Elasticsearch est au format YAML, ce qui signifie que nous devons conserver le format d’indentation. Veillez à ne pas ajouter d’espaces supplémentaires lorsque vous modifiez ce fichier.
Le site elasticsearch.yml fournit des options de configuration pour votre/vos cluster, nœud, chemins, mémoire, réseau, découverte et passerelle. La plupart de ces options sont préconfigurées dans le fichier, mais vous pouvez les modifier en fonction de vos besoins. Pour les besoins de notre démonstration d’une configuration à serveur unique, nous n’ajusterons les paramètres que pour l’hôte du réseau.
Elasticsearch écoute le trafic de partout sur le port 9200. Vous voudrez limiter l’accès extérieur à votre instance Elasticsearch pour empêcher les personnes extérieures de lire vos données ou de fermer votre cluster Elasticsearch par le biais de son [API REST] (https://en.wikipedia.org/wiki/Representational_state_transfer). Pour restreindre l’accès et donc accroître la sécurité, trouvez la ligne qui précise network.host, décommentez-la et remplacez sa valeur parlocalhostcomme ceci :
. . .
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .
Nous avons spécifié localhost de sorte qu’Elasticsearch écoute sur toutes les interfaces et les IP liés. Si vous souhaitez qu’il n’écoute que sur une interface spécifique, vous pouvez spécifier son IP au lieu de localhost. Sauvegardez et fermez elasticsearch.yml. Si vous utilisez nanovous pouvez le faire en appuyant sur CTRL+X, suivi de Y et ensuite ENTRÉE.
Ce sont les paramètres minimums avec lesquels vous pouvez commencer pour utiliser Elasticsearch. Vous pouvez maintenant lancer Elasticsearch pour la première fois.
Démarrez le service Elasticsearch avec systemctl. Donnez à Elasticsearch quelques instants pour démarrer. Dans le cas contraire, vous risquez d’obtenir des erreurs en ne pouvant pas vous connecter.
- sudo systemctl start elasticsearch
Ensuite, exécutez la commande suivante pour permettre à Elasticsearch de démarrer à chaque fois que votre serveur démarre :
- sudo systemctl enable elasticsearch
Vous pouvez tester si votre service Elasticsearch fonctionne en envoyant une requête HTTP :
- curl -X GET "localhost:9200"
Vous verrez une réponse montrant quelques informations de base sur votre nœud local, similaire à celle-ci :
Output{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qqhFHPigQ9e2lk-a7AvLNQ",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Maintenant qu’Elasticsearch est opérationnel, installons Kibana, le prochain composant de l’Elastic Stack.
Étape 2 — Installation et configuration du tableau de bord Kibana
Selon la documentation officielle, vous ne devez installer Kibana qu’après avoir installé Elasticsearch. L’installation dans cet ordre garantit que les composants dont dépend chaque produit sont correctement en place.
Comme vous avez déjà ajouté le paquet source Elastic dans l’étape précédente, vous pouvez simplement installer les composants restants de l’Elastic Stack en utilisant apt :
- sudo apt install kibana
Ensuite, activez et démarrez le service Kibana :
- sudo systemctl enable kibana
- sudo systemctl start kibana
Étant donné que Kibana est configuré pour n’écouter que sur localhost, nous devons mettre en place un proxy inverse pour permettre un accès externe à celui-ci. Nous utiliserons pour cela Nginx, qui devrait déjà être installé sur votre serveur.
Tout d’abord, utilisez la commande openssl pour créer un utilisateur administratif Kibana que vous utiliserez pour accéder à l’interface web de Kibana. À titre d’exemple, nous nommerons ce compte kibanaadmin, mais pour assurer une plus grande sécurité, nous vous recommandons de choisir un nom non standard pour votre utilisateur, un nom difficile à deviner.
La commande suivante créera l’utilisateur et le mot de passe administratifs de Kibana, et les stockera dans le fichier htpasswd.users. Vous allez configurer Nginx pour qu’il vous demande ce nom d’utilisateur et ce mot de passe, puis lire ce fichier momentanément :
- echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
Entrez et confirmez un mot de passe à l’invite. Rappelez-vous ou prenez note de ce login, car vous en aurez besoin pour accéder à l’interface web de Kibana.
Ensuite, nous allons créer un fichier de bloc serveur Nginx. À titre d’exemple, nous appellerons ce fichier your_domain, bien que vous puissiez trouver utile de donner au vôtre un nom plus descriptif. Par exemple, si vous avez un FQDN et des enregistrements DNS configurés pour ce serveur, vous pourriez nommer ce fichier en fonction de votre FQDN.
En utilisant nano ou votre éditeur de texte préféré, créez le fichier de bloc serveur Nginx :
- sudo nano /etc/nginx/sites-available/your_domain
Ajoutez le bloc de code suivant dans le fichier, en veillant à mettre à jour your_domain pour qu’il corresponde au FQDN ou à l’adresse IP publique de votre serveur. Ce code configure Nginx pour diriger le trafic HTTP de votre serveur vers l’application Kibana, qui est à l’écoute sur localhost:5601. De plus, il configure Nginx pour qu’il lise le fichier htpasswd.users et exige une authentification de base.
Notez que si vous avez suivi le tutoriel Nginx jusqu’à la fin, vous avez peut-être déjà créé ce fichier et y avez peut-être ajouté du contenu. Dans ce cas, supprimez tout le contenu existant dans le fichier avant d’ajouter ce qui suit :
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Lorsque vous avez terminé, sauvegardez et fermez le fichier.
Ensuite, activez la nouvelle configuration en créant un lien symbolique vers le répertoire sites-enabled. Si vous avez déjà créé un fichier de bloc de serveur avec le même nom dans les pré-requis Nginx, vous n’avez pas besoin d’exécuter cette commande :
- sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
Ensuite, vérifiez que la configuration ne contient pas d’erreurs de syntaxe :
- sudo nginx -t
Si des erreurs sont signalées dans votre sortie, revenez en arrière et vérifiez que le contenu que vous avez placé dans votre fichier de configuration a été ajouté correctement. Une fois que vous voyez syntax is ok dans la sortie, continuez et redémarrez le service Nginx :
- sudo systemctl reload nginx
Si vous avez suivi le guide de configuration initiale du serveur, vous devriez disposer d’un pare-feu UFW activé. Pour permettre les connexions à Nginx, nous pouvons ajuster les règles en tapant :
- sudo ufw allow 'Nginx Full'
Note : si vous avez suivi le tutoriel Nginx, vous avez peut-être créé une règle UFW permettant au profil HTTP de Nginx de passer à travers le pare-feu. Comme le profil Nginx Full autorise le trafic HTTP et HTTPS à travers le pare-feu, vous pouvez supprimer en toute sécurité la règle que vous avez créée dans le tutoriel des prérequis. Faites-le avec la commande suivante :
- sudo ufw delete allow 'Nginx HTTP'
Kibana est désormais accessible via votre FQDN ou l’adresse IP publique de votre serveur Elastic Stack. Vous pouvez consulter la page d’état du serveur Kibana en vous rendant à l’adresse suivante et en saisissant vos identifiants de connexion lorsque vous y êtes invité :
http://your_domain/status
Cette page d’état affiche des informations sur l’utilisation des ressources du serveur et énumère les plugins installés.
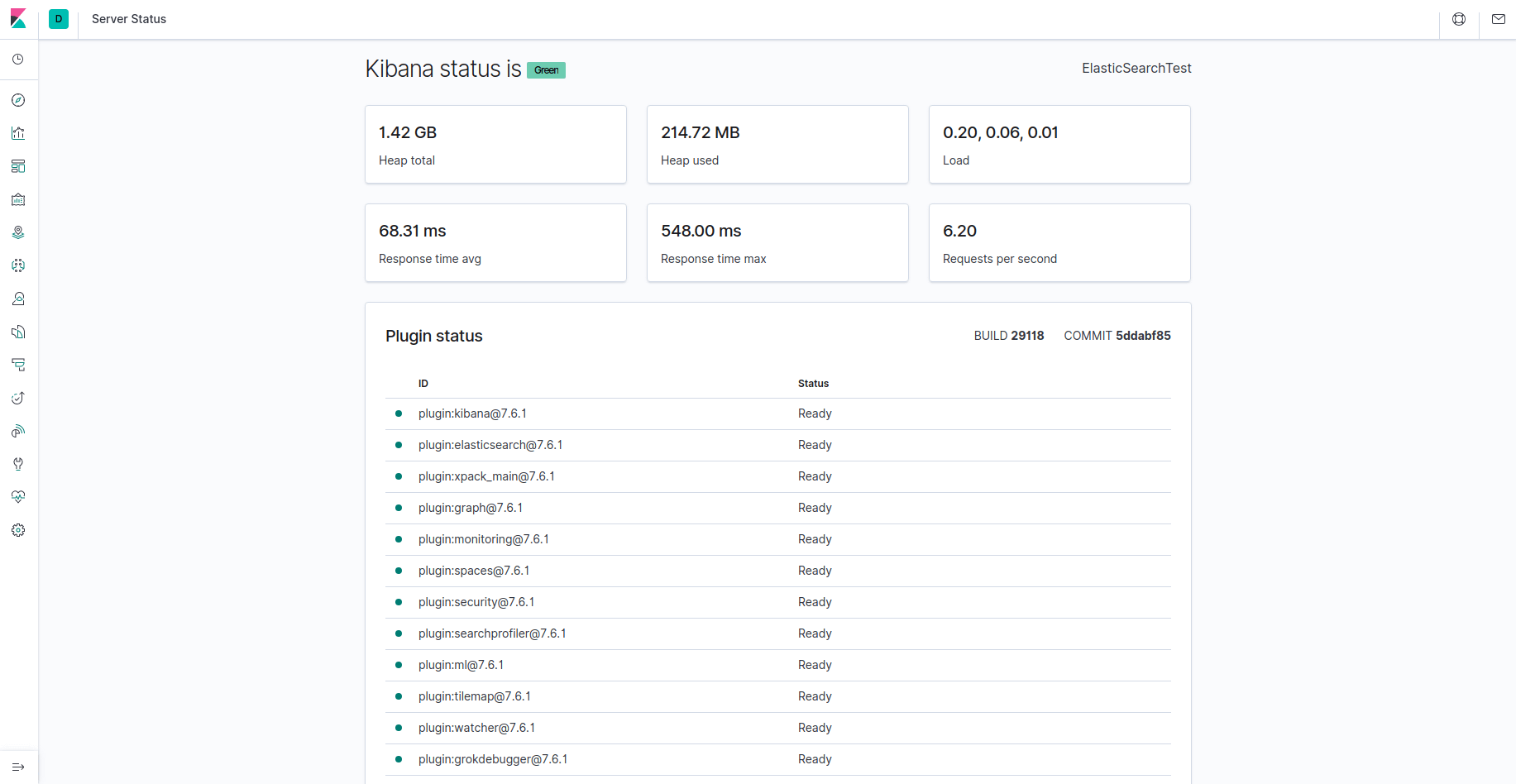
Note : comme mentionné dans la section « Conditions préalables », il est recommandé d’activer SSL/TLS sur votre serveur. Vous pouvez suivre le guide Let’s Encrypt dès maintenant pour obtenir un certificat SSL gratuit pour Nginx sur Ubuntu 20.04. Après avoir obtenu vos certificats SSL/TLS, vous pouvez revenir et compléter ce tutoriel.
Maintenant que le tableau de bord de Kibana est configuré, installons le composant suivant : Logstash.
Étape 3 — Installation et configuration de Logstash
Bien qu’il soit possible pour Beats d’envoyer des données directement à la base de données Elasticsearch, il est courant d’utiliser Logstash pour traiter les données. Cela vous donnera plus de flexibilité pour collecter des données provenant de différentes sources, les transformer en un format commun et les exporter vers une autre base de données.
Installez Logstash avec cette commande :
- sudo apt install logstash
Après avoir installé Logstash, vous pouvez passer à la configuration. Les fichiers de configuration de Logstash se trouvent dans le répertoire /etc/logstash/conf.d. Pour plus d’informations sur la syntaxe de configuration, vous pouvez consulter la référence de configuration fournie par Elastic. Lorsque vous configurez le fichier, il est utile de considérer Logstash comme un pipeline qui prend les données à une extrémité, les traite d’une manière ou d’une autre et les envoie à leur destination (dans ce cas, la destination est Elasticsearch). Un pipeline Logstash comporte deux éléments obligatoires, input (l’entrée) et output (la sortie), et un élément optionnel, filter (le filtre). Les plugins d’entrée consomment les données d’une source, les plugins de filtrage traitent les données, et les plugins de sortie écrivent les données vers une destination.
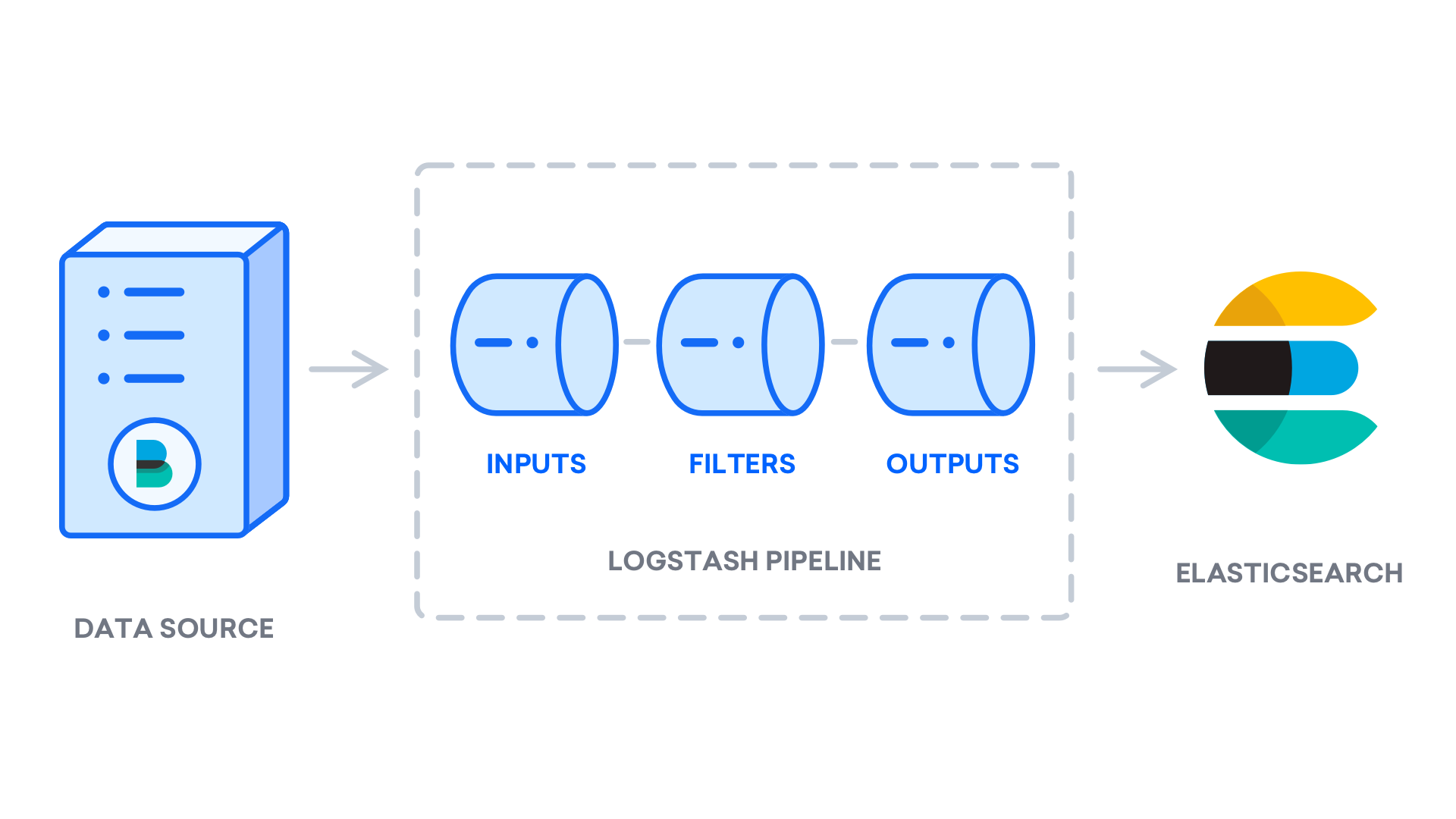
Créez un fichier de configuration appelé 02-beats-input.conf où vous configurerez votre entrée Filebeat :
- sudo nano /etc/logstash/conf.d/02-beats-input.conf
Insérez la configuration input suivante. Elle spécifie une entrée de beats qui écoutera sur le port TCP 5044.
input {
beats {
port => 5044
}
}
Enregistrez et fermez le fichier.
Ensuite, créez un fichier de configuration appelé 30-elasticsearch-output.conf :
- sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
Insérez la configuration output suivante. Globalement, cette sortie configure Logstash pour stocker les données des Beats dans Elasticsearch, qui tourne sur localhost:9200, dans un index nommé en fonction du Beat utilisé. Le Beat utilisé dans ce tutoriel est Filebeat :
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
}
Enregistrez et fermez le fichier.
Testez votre configuration Logstash avec cette commande :
- sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
S’il n’y a pas d’erreurs de syntaxe, votre sortie affichera Config Validation Result: OK. Exiting Logstash après quelques secondes. Si cela n’apparaît pas dans votre sortie, vérifiez les erreurs constatées dans votre sortie et mettez à jour votre configuration pour les corriger. Notez que vous recevrez des avertissements de la part d’OpenJDK, mais ils ne devraient pas causer de problèmes et peuvent être ignorés.
Si votre test de configuration est réussi, démarrez et activez Logstash pour implémenter les changements de configuration :
- sudo systemctl start logstash
- sudo systemctl enable logstash
Maintenant que Logstash fonctionne correctement et est entièrement configuré, installons Filebeat.
Étape 4 — Installation et configuration de Filebeat
L’Elastic Stack utilise plusieurs expéditeurs de données légers appelés Beats pour collecter des données de diverses sources et les transporter vers Logstash ou Elasticsearch. Voici les Beats qui sont actuellement disponibles chez Elastic :
- Filebeat : recueille et expédie les fichiers journaux.
- Metricbeat : collecte les métriques de vos systèmes et services.
- Packetbeat : recueille et analyse les données du réseau.
- Winlogbeat : collecte les journaux des événements Windows.
- Auditbeat : collecte les données du framework de vérification Linux et surveille l’intégrité des fichiers.
- Heartbeat : surveille activement la disponibilité des services.
Dans ce tutoriel, nous utiliserons Filebeat pour transmettre les journaux locaux à notre Elastic Stack.
Installez Filebeat en utilisant apt :
- sudo apt install filebeat
Ensuite, configurez Filebeat pour vous connecter à Logstash. Ici, nous allons modifier l’exemple de fichier de configuration fourni avec Filebeat.
Ouvrez le fichier de configuration Filebeat :
- sudo nano /etc/filebeat/filebeat.yml
Note : comme celui d’Elasticsearch, le fichier de configuration de Filebeat est au format YAML. Cela signifie qu’une indentation correcte est cruciale, aussi veillez à utiliser le même nombre d’espaces que ceux qui sont indiqués dans ces instructions.
Filebeat prend en charge de nombreuses sorties, mais vous n’enverrez généralement les événements que directement à Elasticsearch ou à Logstash pour un traitement supplémentaire. Dans ce tutoriel, nous utiliserons Logstash pour effectuer des traitements supplémentaires sur les données collectées par Filebeat. Filebeat n’aura pas besoin d’envoyer de données directement à Elasticsearch. Désactivons donc cette sortie. Pour ce faire, trouvez la section output.elasticsearch et commentez les lignes suivantes en les faisant précéder d’un # :
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...
Ensuite, configurez la section output.logstash. Décommentez les lignes output.logstash: et hosts: ["localhost:5044"] en supprimant le #. Cela permettra de configurer Filebeat pour qu’il se connecte à Logstash sur votre serveur Elastic Stack au port 5044, le port pour lequel nous avons spécifié une entrée Logstash plus tôt :
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
Enregistrez et fermez le fichier.
La fonctionnalité de Filebeat peut être étendue avec des modules Filebeat. Dans ce tutoriel, nous utiliserons le module system, qui collecte et analyse les journaux créés par le service de journalisation du système des distributions Linux courantes.
Activons-le :
- sudo filebeat modules enable system
Vous pouvez consulter la liste des modules activés et désactivés en exécutant :
- sudo filebeat modules list
Vous verrez une liste semblable à celle qui suit :
OutputEnabled:
system
Disabled:
apache2
auditd
elasticsearch
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
traefik
...
Par défaut, Filebeat est configuré pour utiliser les itinéraires par défaut pour le syslog et les journaux d’autorisation. Dans le cas de ce tutoriel, vous n’avez pas besoin de modifier quoi que ce soit dans la configuration. Vous pouvez voir les paramètres du module dans le fichier de configuration /etc/filebeat/modules.d/system.yml.
Ensuite, nous devons mettre en place les pipelines d’ingestion de Filebeat, qui analysent les données du journal avant de les envoyer à Elasticsearc via Logstash. Pour charger le pipeline d’ingestion pour le module system, entrez la commande suivante :
- sudo filebeat setup --pipelines --modules system
Ensuite, chargez le modèle d’index dans Elasticsearch. Un index Elasticsearch est une collection de documents qui présentent des caractéristiques similaires. Les index sont identifiés par un nom, qui est utilisé pour se référer à l’index lors de l’exécution de diverses opérations en son sein. Le modèle d’index sera automatiquement appliqué lors de la création d’un nouvel index.
Pour charger le modèle, utilisez la commande suivante :
- sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
OutputIndex setup finished.
Filebeat contient des exemples de tableaux de bord Kibana qui vous permettent de visualiser les données Filebeat dans Kibana. Avant de pouvoir utiliser les tableaux de bord, vous devez créer le modèle d’index et charger les tableaux de bord dans Kibana.
Lors du chargement des tableaux de bord, Filebeat se connecte à Elasticsearch pour vérifier les informations de version. Pour charger des tableaux de bord lorsque Logstash est activé, vous devez désactiver la sortie Logstash et activer la sortie Elasticsearch :
- sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
Vous devriez recevoir un résultat qui ressemble à ça :
OutputOverwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
Vous pouvez maintenant démarrer et activer Filebeat :
- sudo systemctl start filebeat
- sudo systemctl enable filebeat
Si vous avez correctement configuré votre Elastic Stack, Filebeat commencera à envoyer votre syslog et vos journaux d’autorisation à Logstash, qui chargera ensuite ces données dans Elasticsearch.
Pour vérifier que Elasticsearch reçoit bel et bien ces données, interrogez l’index Filebeat avec cette commande :
- curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
Vous devriez recevoir un résultat qui ressemble à ça :
Output...
{
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4040,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.7.1-2020.06.04",
"_type" : "_doc",
"_id" : "FiZLgXIB75I8Lxc9ewIH",
"_score" : 1.0,
"_source" : {
"cloud" : {
"provider" : "digitalocean",
"instance" : {
"id" : "194878454"
},
"region" : "nyc1"
},
"@timestamp" : "2020-06-04T21:45:03.995Z",
"agent" : {
"version" : "7.7.1",
"type" : "filebeat",
"ephemeral_id" : "cbcefb9a-8d15-4ce4-bad4-962a80371ec0",
"hostname" : "june-ubuntu-20-04-elasticstack",
"id" : "fbd5956f-12ab-4227-9782-f8f1a19b7f32"
},
...
Si votre sortie affiche 0 résultat total, cela signifie qu’Elasticsearch ne charge aucun journal sous l’index que vous avez recherché, et vous devrez revoir votre configuration pour détecter les erreurs. Si vous avez obtenu la sortie attendue, passez à l’étape suivante, dans laquelle nous verrons comment naviguer dans certains des tableaux de bord de Kibana.
Étape 5 — Exploration des tableaux de bord Kibana
Revenons à l’interface web Kibana que nous avons installée précédemment.
Dans un navigateur web, rendez-vous à la FQDN ou à l’adresse IP publique de votre serveur Elastic Stack. Si votre session a été interrompue, vous devrez y rentrer en entrant les identifiants que vous avez définis lors de l’étape 2. Une fois connecté, vous devriez voir la page d’accueil de Kibana :
Cliquez sur le lien Discover (Découvrir) dans la barre de navigation de gauche (vous devrez peut-être cliquer sur l’icône Expand (Développer) tout en bas à gauche pour voir les éléments du menu de navigation). Sur la page Discover (Découvrir), sélectionnez le modèle d’index filebeat-* prédéfini pour voir les données Filebeat. Par défaut, cela vous montrera toutes les données du journal au cours des 15 dernières minutes. Vous verrez un histogramme avec les événements du journal, et quelques messages du journal ci-dessous :
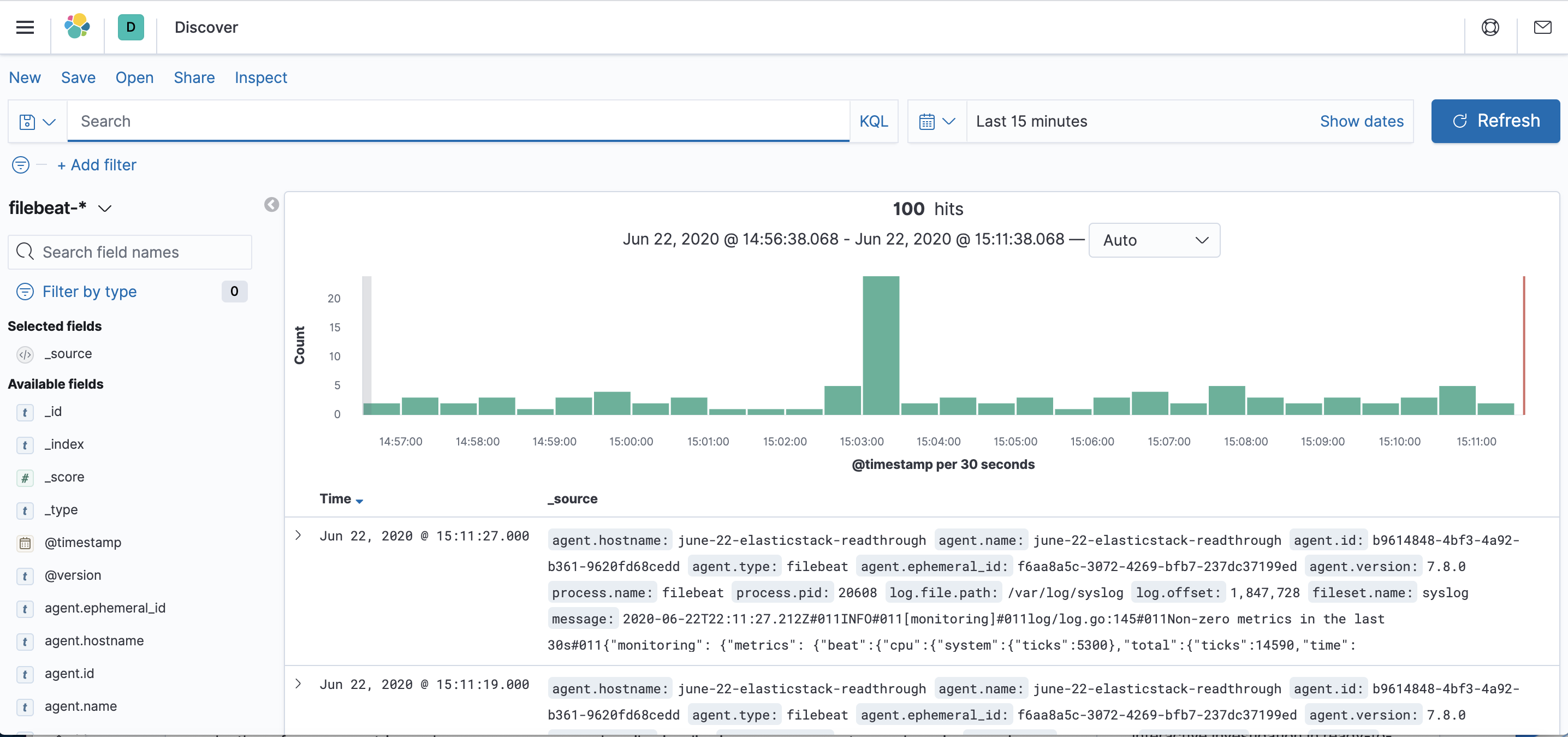
Ici, vous pouvez rechercher des journaux et les parcourir, et également personnaliser votre tableau de bord. A ce stade, cependant, il n’y aura pas grand chose dedans, parce que vous ne recueillez que les syslogs de votre serveur Elastic Stack.
Utilisez le panneau de gauche pour naviguer jusqu’à la page Dashboard (Tableau de bord) et rechercher les tableaux de bord Filebeat System. Une fois sur la page, vous pouvez sélectionner les exemples de tableaux de bord fournis avec le module system de Filebeat.
Par exemple, vous pouvez consulter des statistiques détaillées en fonction de vos messages syslog :
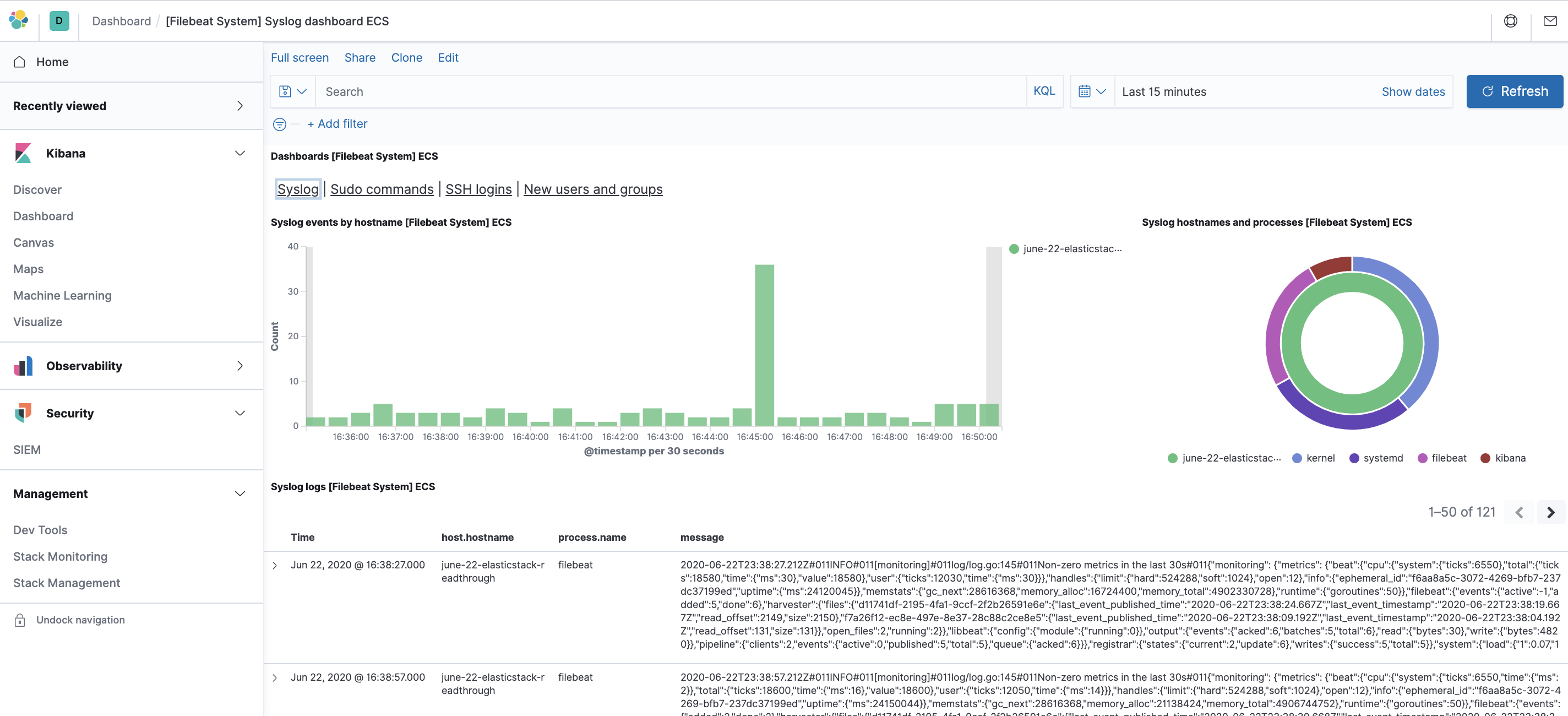
Vous pouvez également voir quels utilisateurs ont utilisé la commande sudo et à quel moment :
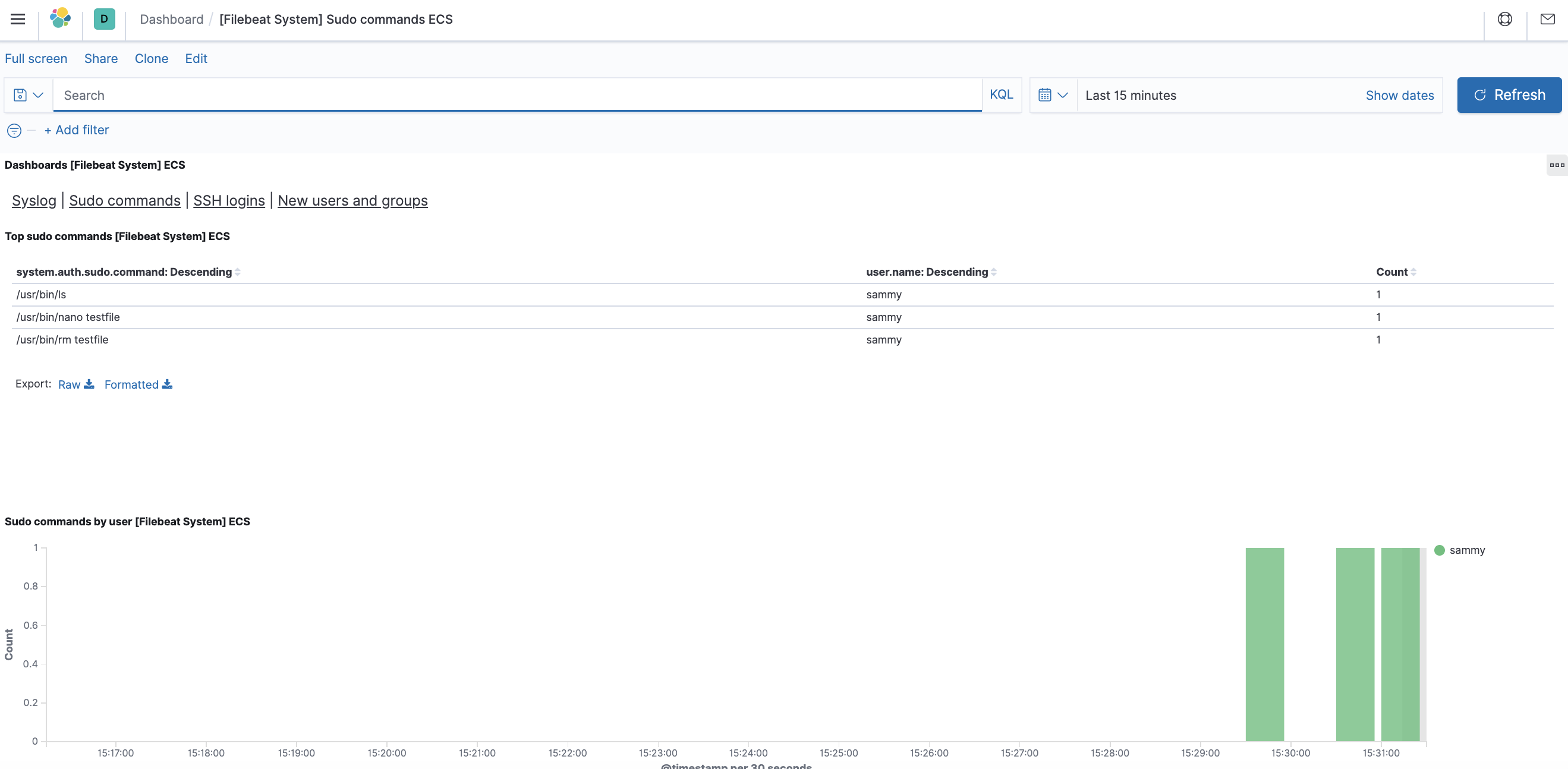
Kibana offre de nombreuses autres fonctionnalités, telles que le graphisme et le filtrage : n’hésitez pas à les explorer.
Conclusion
Dans ce tutoriel, vous avez appris comment installer et configurer l’Elastic Stack pour collecter et analyser les journaux du système. N’oubliez pas que vous pouvez envoyer à peu près n’importe quel type de journal ou de données indexées à Logstash en utilisant Beats, mais que les données deviennent encore plus utiles si elles sont analysées et structurées avec un filtre Logstash, car cela les transforme en un format cohérent qui peut être lu facilement par Elasticsearch.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Open source advocate and lover of education, culture, and community.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.