AI Technical Writer

Introduction
In this guide, we will understand Mistral 7B, a state-of-the-art large language model with 7 billion parameters, designed to deliver remarkable performance and efficiency. Despite its relatively compact size, Mistral 7B surpasses larger models—outperforming LLaMA 2 (13B) across all major benchmarks and even exceeding LLaMA 1 (34B) in tasks involving reasoning, mathematics, and code generation.
What sets Mistral 7B apart is its innovative architecture, featuring Grouped-Query Attention (GQA) for faster inference and Sliding Window Attention (SWA) for efficient handling of long sequences—ensuring high throughput with reduced inference costs.
In this tutorial, you’ll learn how to fine-tune Mistral 7B using LoRA (Low-Rank Adaptation) on the GPU of your choice. While we demonstrate the process using the powerful yet affordable NVIDIA A6000, you’re free to use any available GPU that meets the memory requirements. Whether you’re building a domain-specific chatbot or customizing the model for specialized tasks, this guide will help you optimize both performance and cost.
Prerequisites
- Hardware Requirements:
- A compatible GPU (e.g., H100, A100) with sufficient VRAM (at least 16 GB recommended).
- Adequate system memory (at least 32 GB RAM).
- Software Requirements:
- Python (version 3.7 or higher).
- Ensure deep learning libraries like PyTorch and Transformers are installed.
- LoRA library (e.g., PEFT or similar) for implementing low-rank adaptation.
- Data Preparation:
- A well-structured dataset relevant to the desired fine-tuning task.
- Data preprocessing tools to clean and format the data.
- Familiarity:
- Understanding of deep learning concepts and model fine-tuning.
- Experience with Python programming and using command-line interfaces.
- Environment Setup:
- An environment set up with necessary dependencies, possibly using virtual environments (e.g., conda or venv).
Fine-Tuning Mistral-7B
Our focus is on training the model using 4-bit double quantization with LoRa, specifically on the MosaicML instruct dataset. Further, we’ll narrow down to the ‘dolly_hhrlhf’ subset of the dataset, which is a clean response-input pair. Regardless of the dataset size, the process remains the same. The process involves the conversion of actual data into prompts.
Concept
Here’s the concept: We provide the model with a response from our dataset and challenge it to generate the original instruction that led to that response. It’s like the entire process but in reverse.
Let us start by importing the necessary packages:
!pip install transformers trl accelerate torch bitsandbytes peft datasets -qU
Next, we will download the dataset needed to fine-tune the model.
from datasets import load_dataset
instruct_tune_dataset = load_dataset("mosaicml/instruct-v3")
instruct_tune_dataset
type(instruct_tune_dataset)
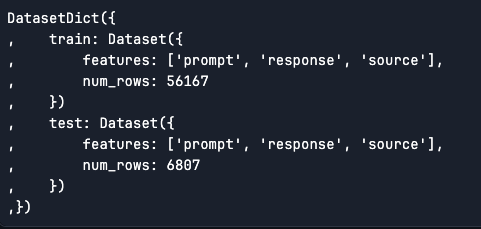
As we can see, the training data is a pair of 56.2k rows, and the test data is 6.8k rows and is a ‘datasets.dataset_dict.DatasetDict’ type dataset.
Further, we will narrow down the dataset to obtain the subset of the data by filtering on ‘dolly_hhrlhf.’
instruct_tune_dataset = instruct_tune_dataset.filter(lambda x: x["source"] == "dolly_hhrlhf")
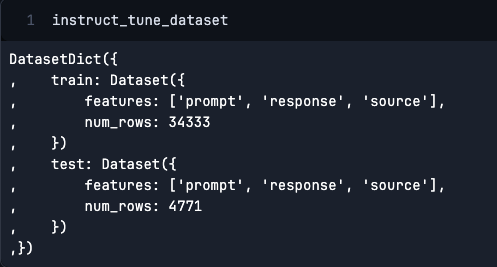
We’re going to train and test on a smaller subset of the data, which would reduce the amount of time spent training!
instruct_tune_dataset["train"] = instruct_tune_dataset["train"].select(range(3000))
instruct_tune_dataset["test"] = instruct_tune_dataset["test"].select(range(200))
We will create a function that takes a sample input and generates a sequence, which consists of the message and the prompt to obtain that response.
def create_prompt(sample):
bos_token = "<s>"
original_system_message = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
system_message = "Use the provided input to create an instruction that could have been used to generate the response with an LLM."
response = sample["prompt"].replace(original_system_message, "").replace("\n\n### Instruction\n", "").replace("\n### Response\n", "").strip()
input = sample["response"]
eos_token = "</s>"
full_prompt = ""
full_prompt += bos_token
full_prompt += "### Instruction:"
full_prompt += "\n" + system_message
full_prompt += "\n\n### Input:"
full_prompt += "\n" + input
full_prompt += "\n\n### Response:"
full_prompt += "\n" + response
full_prompt += eos_token
return full_prompt
for example:-
instruct_tune_dataset["train"][0]
{‘prompt’: ‘Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction\nHow can I cook food while camping?\n\n### Response\n’,
‘response’: ‘The best way to cook food is over a fire. You’ll need to build a fire and light it first, and then heat food in a pot on top of the fire.’,
‘source’: ‘dolly_hhrlhf’}
create_prompt(instruct_tune_dataset["train"][0])
‘### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.\n\n### Input:\nThe best way to cook food is over a fire. You’ll need to build a fire and light it first, and then heat food in a pot on top of the fire.\n\n### Response:\nHow can I cook food while camping?’
Load and Train the Model
This step is crucial as the model needs sufficient GPU space. We will proceed with the quantized version of the model from 32-bit to 4-bit.
We’ve decided to implement BFloat16, a 16-bit or half-precision quantization, for our compute data type, while the storage data type will be four bits. This means that we’ll store all weights using 4 bits, but during training, we’ll temporarily upcast them to 16 bits. This approach allows us to efficiently train while benefiting from the space savings achieved through 4-bit quantization.
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
Next, load the model and the tokenizer
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-Instruct-v0.1",
device_map='auto',
quantization_config=nf4_config,
use_cache=False
)
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
Let us now move to the fine-tuning part!
Since we are using a quantized version of the model, we should use something called LoRa. We highly recommend gaining a deeper knowledge of LoRa to better understand the tutorial.
But for now, we will understand LoRa briefly.
LoRa
In this fine-tuning process, we employ Parameter Efficient Fine Tuning (PEFT) using the Low-Rank Adaptation (LoRA) method. In simpler terms, when we train our model, we utilize a large set of information known as a matrix. There are many of these matrices involved. LoRA is a technique that allows us to work with much smaller matrices that represent the larger ones. This approach takes advantage of the repetitive patterns found in the big matrix, especially in relation to our specific objectives.
So, think of the full matrix like a big list of all the tasks it could ever learn, but our specific task only needs a small part of that list. With LoRa, we figure out how to focus just on that small part. This way, we don’t have to deal with the whole list every time we train our model for our specific job. That’s the basic idea behind LoRa!
This approach further reduces the amount of GPU space needed, as the model doesn’t have to process and store unnecessary information. Essentially, LoRa optimizes the use of GPU resources and making the training process more efficient and saving valuable computing resources.
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM"
)
Prepare the model for k-bit training.
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
Next, set the hyperparameter to this so as not to make the model overfit the training data.
args = TrainingArguments(
output_dir = "mistral_instruct_generation",
#num_train_epochs=5,
max_steps = 100,
per_device_train_batch_size = 4,
warmup_steps = 0.03,
logging_steps=10,
save_strategy="epoch",
#evaluation_strategy="epoch",
evaluation_strategy="steps",
eval_steps=20,
learning_rate=2e-4,
bf16=True,
lr_scheduler_type='constant',
)
In the process of supervised fine-tuning (SFT), the pre-trained Language Model (LLM) undergoes adjustments using labeled data through supervised learning techniques. The model’s weights are modified according to the gradients obtained from the task-specific loss, which is measured by the difference between the predictions made by the LLM and the actual ground truth labels.
max_seq_length = 2048
trainer = SFTTrainer(
model=model,
peft_config=peft_config,
max_seq_length=max_seq_length,
tokenizer=tokenizer,
packing=True,
formatting_func=create_prompt,
args=args,
train_dataset=instruct_tune_dataset["train"],
eval_dataset=instruct_tune_dataset["test"]
)
Next, we will call the train function. Here, we train the model for 100 steps.
import time
start = time.time()
trainer.train()
print(time.time()- start)
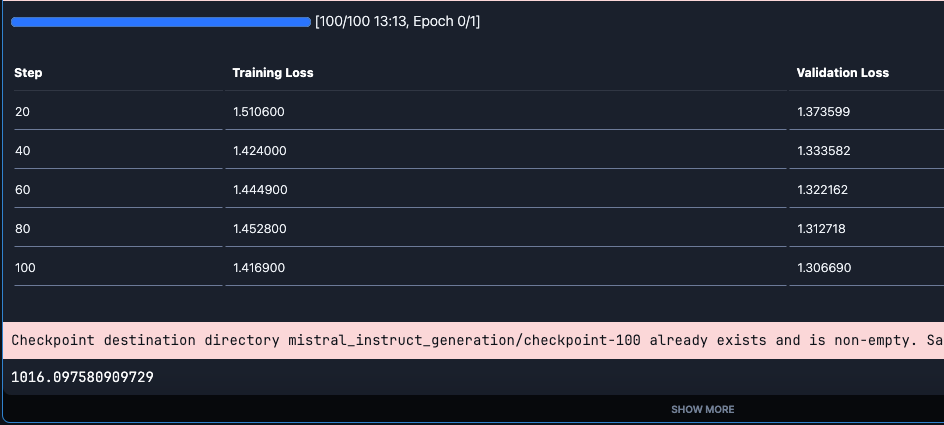
We can see that the loss gradually decreases with the steps. Also, note that it takes approximately 16 minutes to train the model. Please note that you need to add a wand credential before the training.
We will save this trained model locally,
trainer.save_model("mistral_instruct_generation")
We can push the model to the Hugging Face hub and make sure to authorize Hugging Face to push the model.
In this scenario, we are using an adapter instead of pushing the full model. When we utilize LoRa for training, we create a component known as an adapter. This adapter acts as an extension to the base model, allowing it to acquire specific capabilities that were developed during the fine-tuning process.
trainer.push_to_hub("shaoni/mistral-instruct-generation")
View the system metrics and model performance by checking the recent run on wandb.ai.
Please keep in mind that the model can still underperform as it is fine-tuned on a small sample dataset.
generate_response("### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.### Input:\nThere are more than 12,000 species of grass. The most common is Kentucky Bluegrass, because it grows quickly, easily, and is soft to the touch. Rygrass is shiny and bright green colored. Fescues are dark green and shiny. Bermuda grass is harder but can grow in drier soil.\n\n### Response:", model)
‘### Instruction:\nUse the provided input to create an instruction that could have been used to generate the response with an LLM.### Input:\nThere are more than 12,000 species of grass. The most common is Kentucky Bluegrass, because it grows quickly, easily, and is soft to the touch. Ryegrass is shiny and bright green colored. Fescues are dark green and shiny. Bermuda grass is harder but can grow in drier soil.\n\n### Response:\nWhich type of grass is the most common and why is it popular?’
This response is much better, and the model is not just adding random words about the grass.
And with this, we have come to the end of fine-tuning Mistral-7B using PEFT LoRa.
We also recommend checking out the references section to find out more. We hope you enjoyed the article!
FAQ’s
Q: What is Mistral 7B and how many parameters does it have? A: Mistral 7B is a high-performance language model with 7 billion parameters.
Q: How does Mistral 7B compare to Llama 2 13B and Llama 1 34B in performance? A: It outperforms LLaMA 2 (13B) on several benchmarks and exceeds LLaMA 1 (34B) in reasoning, math, and coding tasks.
Q: What types of tasks does Mistral 7B excel at? A: Reasoning, mathematics, code generation, and general NLP tasks.
Q: What is grouped-query attention (GQA) and how does it benefit inference speed? A: GQA reduces the number of attention heads, increasing the inference speed while preserving model quality.
Q: What kind of GPU is recommended for fine-tuning Mistral 7B? A: A GPU with at least 24GB VRAM, such as NVIDIA A6000, A100, or 3090, is recommended.
Q: What are the minimum hardware requirements for running Mistral 7B? A: Minimum 24GB GPU VRAM, 100GB disk space, and 32GB system RAM.
Q: What are the software prerequisites for fine-tuning this model? A: Python, PyTorch, Transformers, Datasets, Accelerate, PEFT, and LoRA libraries.
Q: Which version of Python is required to run Mistral 7B fine-tuning scripts? A: Python 3.9 or later is recommended for compatibility.
Q: What deep learning libraries need to be installed beforehand? A: Install PyTorch, Transformers, PEFT, Accelerate, and Datasets.
Q: Why is the LoRA library used, and what is its purpose in fine-tuning? A: LoRA enables parameter-efficient fine-tuning by injecting trainable rank-decomposition matrices into transformer layers.
Conclusion
In this article, we were able to successfully fine-tune Mistral-7B using LoRa. This finetuning can be done using less powerful GPUs, but it may take longer to achieve results. Consider using DigitalOcean’s GPU Droplet to get access to the powerful, high-performance H100 GPU for all AI/ML workloads, deep learning model training, and resource-intensive tasks with exceptional speed and efficiency.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
