By Safa Mulani

Hello, readers! In this article, we will be focusing on Outlier Analysis in R programming, in detail.
So, let us begin!!
What are outliers in data?
Before diving deep into the concept of outliers, let us focus on the pre-processing of data values.
In the domain of data science and machine learning, pre-processing of data values is a crucial step. By pre-processing, we mean to say, that getting all the errors and noise removed from the data prior to modeling.
In our last post, we had understood about missing value analysis in R programming.
Today, we would be a focus on an advanced level of the same - Outlier detection and removal in R.
Outliers, as the name suggests, are the data points that lie away from the other points of the dataset. That is the data values that appear away from other data values and hence disturb the overall distribution of the dataset.
This is usually assumed as an abnormal distribution of the data values.
Effect of Outliers on the model -
- The data turns out to be in a skewed format.
- Changes the overall statistical distribution of data in terms of mean, variance, etc.
- Leads to obtain a bias in the accuracy level of the model.
Having understood the effect of outliers, it is now the time to work on its implementation.
Outlier Analysis - Get set GO!
At first, it is very important for us to detect the presence of outliers in the dataset.
So, let us begin. We have made use of the Bike Rental Count Prediction dataset. You can find the dataset here!
1. Loading the Dataset
Initially, we have loaded the dataset into the R environment using the read.csv() function.
Prior to outlier detection, we have performed missing value analysis just to check for the presence of any NULL or missing values. For the same, we have made use of sum(is.na(data)) function.
#Removed all the existing objects
rm(list = ls())
#Setting the working directory
setwd("D:/Ediwsor_Project - Bike_Rental_Count/")
getwd()
#Load the dataset
bike_data = read.csv("day.csv",header=TRUE)
### Missing Value Analysis ###
sum(is.na(bike_data))
summary(is.na(bike_data))
#From the above result, it is clear that the dataset contains NO Missing Values.
The data here contains NO missing values
2. Detect Outliers With Boxplot Function
Having said this now is the time to detect the presence of outliers in the dataset. To achieve this, we have saved the numeric data columns into a separate data structure/variable using c() function.
Further, we have made use of boxplot() function to detect the presence of outliers in the numeric variables.
BoxPlot:
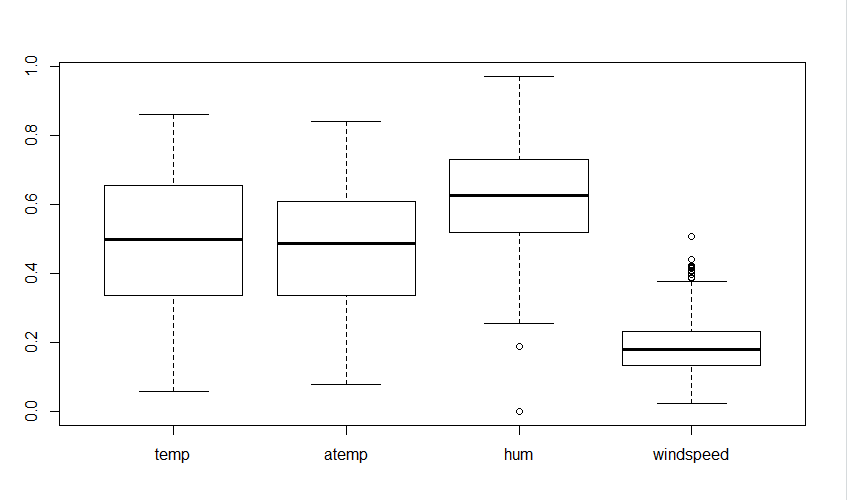
From the visuals, it is clear that the variables ‘hum’ and ‘windspeed’ contain outliers in their data values.
3. Replacing Outliers with NULL Values
Now, after performing outlier analysis in R, we replace the outliers identified by the boxplot() method with NULL values to operate over it as shown below.
##############################Outlier Analysis -- DETECTION###########################
# 1. Outliers in the data values exists only in continuous/numeric form of data variables. Thus, we need to store all the numeric and categorical independent variables into a separate array structure.
col = c('temp','cnt','hum','windspeed')
categorical_col = c("season","yr","mnth","holiday","weekday","workingday","weathersit")
# 2. Using BoxPlot to detect the presence of outliers in the numeric/continuous data columns.
boxplot(bike_data[,c('temp','atemp','hum','windspeed')])
# From the above visualization, it is clear that the data variables 'hum' and 'windspeed' contains outliers in the data values.
#OUTLIER ANALYSIS -- Removal of Outliers
# 1. From the boxplot, we have identified the presence of outliers. That is, the data values that are present above the upper quartile and below the lower quartile can be considered as the outlier data values.
# 2. Now, we will replace the outlier data values with NULL.
for (x in c('hum','windspeed'))
{
value = bike_data[,x][bike_data[,x] %in% boxplot.stats(bike_data[,x])$out]
bike_data[,x][bike_data[,x] %in% value] = NA
}
#Checking whether the outliers in the above defined columns are replaced by NULL or not
sum(is.na(bike_data$hum))
sum(is.na(bike_data$windspeed))
as.data.frame(colSums(is.na(bike_data)))
4. Verify All Outliers Are Replaced With NULL
Now, we check for the presence of missing data i.e. whether the outlier values have been converted to missing values properly using the sum(is.na()) function.
Output:
> sum(is.na(bike_data$hum))
[1] 2
> sum(is.na(bike_data$windspeed))
[1] 13
> as.data.frame(colSums(is.na(bike_data)))
colSums(is.na(bike_data))
instant 0
dteday 0
season 0
yr 0
mnth 0
holiday 0
weekday 0
workingday 0
weathersit 0
temp 0
atemp 0
hum 2
windspeed 13
casual 0
registered 0
cnt 0
As a result, we have converted the 2 outlier points from the ‘hum’ column and 13 outlier points from the ‘windspeed’ column into missing(NA) values.
5. Drop Columns With Missing Values
At last, we treat the missing values by dropping the NULL values using drop_na() function from the ‘tidyr’ library.
#Removing the null values
library(tidyr)
bike_data = drop_na(bike_data)
as.data.frame(colSums(is.na(bike_data)))
Output:
As a result, all the outliers have been effectively removed now!
> as.data.frame(colSums(is.na(bike_data)))
colSums(is.na(bike_data))
instant 0
dteday 0
season 0
yr 0
mnth 0
holiday 0
weekday 0
workingday 0
weathersit 0
temp 0
atemp 0
hum 0
windspeed 0
casual 0
registered 0
cnt 0
Conclusion
By this, we have come to the end of this topic. Feel free to comment below, in case you come across any question. For more such posts related to R programming, stay tuned!!
Till then, Happy Learning!!:)
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
