
Introduction
We have reasoning models, such as DeepSeek R1, which methodically break down complex problems by undergoing internal chain-of-thought reasoning before producing a response.
We also have multimodal models, for example,CLIP and LLaVA, that process multiple modalities of data such as text, images, audio, etc. Reasoning models showcase the power of thinking step-by-step, whereas multimodal models demonstrate the advantages of processing information from several sources. While both model categories are impressive in their own right, they have their limitations. For example, many current visual-language models frequently struggle to effectively organize available information and perform deeper-level reasoning, resulting in inadequate performance on visual reasoning tasks.

To achieve improved capabilities, there’s been a collective shift towards developing multimodal reasoning models, as seen with models like R1-Onevision and OpenAI’s o1, which was initially released with reasoning but later updated to incorporate multimodal capabilities.
Prerequisites
This article is divided into two main sections, each with recommended prerequisite knowledge:
Model Overview: Familiarity with Large Language Model training methods (ex: Dataset Creation, Supervised Fine-Tuning, Reinforcement Learning, etc.) will provide valuable context for understanding the R1-Onevision overview section.
Implementation Details: This section includes code for running the model on DigitalOcean GPU Droplets. Modification of the code for your use-case will require previous coding experience and/or familiarity with tools like Cursor.
Feel free to skip any sections that aren’t useful for you.
R1-Onevision
R1-Onevision is an open-source multimodal reasoning model. Hailing from researchers at Zhejiang University, this model debuted in February 2025, followed by a series of updates in March 2025.
Here is a high-level summary of the release:
- A cross-modal reasoning pipeline was developed to construct the R1-Onevision Dataset, which encompasses a diverse array of images, questions, and their corresponding reasoning processes.
- The researchers introduced R1-Onevision, a visual language reasoning model specifically designed for complex problem-solving tasks.
- To evaluate its performance, they built R1-Onevision-Bench, a benchmark aimed at assessing multimodal reasoning across different educational levels and subject areas.
Through extensive experimentation, the researchers demonstrated that R1-Onevision exhibits superior performance compared to both the baseline Qwen2.5-VL model and closed-source models like GPT-4o.
Model Overview
 (source) Here, we have an overview of how R1-Onevision was trained.
(source) Here, we have an overview of how R1-Onevision was trained.
Dataset Creation
A cross-modal reasoning pipeline was used to generate reasoning data to derive the R1-Onevision dataset.

The data distribution of the dataset is represented in this table:
| CATEGORY | SUB-COMPONENT | SIZE (K) |
|---|---|---|
| Science | ScienceQA | 16.4 |
| AI2D | 10.6 | |
| Math | Geo170kQA | 31.8 |
| GeoMVerse | 4.8 | |
| Geometry3K | 4.7 | |
| IconQA | 7.4 | |
| Raven | 1.5 | |
| Doc/Chart/Screen | DVQA | 30.2 |
| RoBUTWTQ | 24.2 | |
| Chart2Text | 4.4 | |
| DocVQA | 2.5 | |
| Infographic VQA | 2.5 | |
| Screen2Words | 1.6 | |
| VisText | 1.3 | |
| General Vision | IconQA | 8.2 |
| Visual7w | 3.2 | |
| VizWiz | 1.8 | |
| VSR | 0.9 |
Image Captioning

| Image Type | Tools Used | Process | Output |
|---|---|---|---|
| Charts and Diagrams | GPT-4o | GPT-4o is prompted to generate formal representations, which is essentially language presented in a precise and unambiguous format. | Examples of formal language outputs include SPICE for electronic circuits, PlantUML and Mermaid.js for diagrams, CSV and JSON for tabular data, and Matplotlib for annotated charts. |
| Natural Scenes | GPT-4o, Grounding DINO | GPT-4o creates detailed descriptions and Grounding DINO identifies key elements with bounding boxes. | Structured annotations combining descriptions and spatial data for key elements. |
| Text-Only Images (images containing printed or handwritten text) | EasyOCR, GPT-4o | EasyOCR extracts text and position and GPT-4o reconstructs the original document. | Text captured in original format with layout and context preserved. |
| Images with Text | GPT-4o, Grounding DINO, EasyOCR | GPT-4o descriptions, Grounding DINO bounding boxes, and EasyOCR text extraction were combined. | Reconstructed document format with aligned visual and textual elements. |
| Mathematical Images | GPT-4o | GPT-4o condenses captions, reasoning steps, and results. | Detailed summaries providing context for mathematical reasoning tasks. |
Generating Chain-of-Thought
 DeepSeek-R1 was prompted to generate Chain-of-Thought (CoT) data using image captions generated in the previous stage. A “role-playing” technique was used to allow the model to iteratively refine its understanding of the visual information. Here, the model was prompted to repeatedly revisit the image, extract more information, reflect on it, and refine its reasoning.
DeepSeek-R1 was prompted to generate Chain-of-Thought (CoT) data using image captions generated in the previous stage. A “role-playing” technique was used to allow the model to iteratively refine its understanding of the visual information. Here, the model was prompted to repeatedly revisit the image, extract more information, reflect on it, and refine its reasoning.
Answer Filtering
 GPT-4o was utilized to filter out inaccurate or irrelevant CoT steps, resulting in a high-quality dataset for multimodal reasoning.
GPT-4o was utilized to filter out inaccurate or irrelevant CoT steps, resulting in a high-quality dataset for multimodal reasoning.
Post-Training
There are two stages the researchers used in their post-training process: Supervised Fine-Tuning (SFT) and rule-based Reinforcement Learning (RL). SFT stabilizes the model’s reasoning process and standardizes its output format, whereas RL improves generalization across a variety of multimodal tasks.

Supervised Fine-Tuning
To standardize the output format and stabilize the reasoning process – that is, ensuring that it produces consistent and predictable results – researchers conducted Supervised Fine-Tuning (SFT) on Qwen2.5-VL-Instruct using the R1-Onevision dataset and LLaMA Factory.
Reinforcement Learning
A rule-based RL approach was implemented, employing two rules that assessed accuracy and formatting of the model’s response. Group Relative Policy Optimization (GRPO) was used to update the model.
Accuracy Reward
Checks the model’s answer against the ground truth using either a regex pattern, mathematical verification, or Intersection over Union (IoU). A match with the ground truth rewards the model, while a mismatch applies a penalty.
Format Reward
Ensures the reasoning process is occurring by verifying the presence and order of <think> and <answer> tags using a regex pattern. Correctly placed tags reward the model.
Group Relative Policy Optimization (GRPO)
GRPO is used due to its ability to balance making improvements to the decision-making policy while maintaining stability.
For each potential action (token), GRPO takes the ratio of how likely the action is under the new policy and how likely it is under the reference policy. To reiterate, GRPO calculates the ratio of the probabilities (actually, the ratio of the exponentials of the log probabilities to prevent numerical underflow and simplify calculations) to see how much the new policy’s probability for a token differs from the reference policy’s probability.
To prevent drastic changes that could destabilize training, a clipping mechanism is used to ensure the value of the calculated ratio is limited to a range [1-ε, 1+ε].
The clipped ratio is used in the clipped loss function below. This loss is essentially Proximal Policy Optimization (PPO)-style loss, but with the advantage function normalized.

| Component | Description |
|---|---|
| ℒclip | The clipped loss function in GRPO |
| -𝔼[…] | The negative expected value (average) of the expression inside the brackets |
| ratio𝑡 | The probability ratio between the new policy and reference policy for a given token/action at time t |
| Adv𝑡 | The advantage function at time t, which measures how much better (or worse) an action is compared to what was expected from the baseline policy |
| clipped_ratio𝑡 | The same ratio, but clipped to stay within bounds [1-ε, 1+ε] |
| min(ratio𝑡 · Adv𝑡, clipped_ratio𝑡 · Adv𝑡) | Takes the minimum value between the original policy ratio multiplied by the advantage and the clipped policy ratio multiplied by the advantage |
A KL divergence penalty is applied to the clipped loss function to ensure closeness with the reference distribution.

| Component | Description |
|---|---|
| ℒGRPO(θ) | The complete GRPO loss function with parameter θ |
| β · KL(π𝜃(y|x), π𝑟𝑒𝑓(y | x)) | The KL divergence penalty term weighted by β, measuring difference between new policy π𝜃 and reference policy π𝑟𝑒𝑓 |
| ratio𝑡 | Probability ratio between new and reference policies for a token at time t |
| Adv𝑡 | Advantage function at time t, measuring relative value of actions |
| clipped_ratio𝑡 | Policy ratio clipped to stay within bounds [1-ε, 1+ε] |
| β | Weight parameter controlling the influence of the KL divergence penalty |
For another explanation of GRPO, check out the article, “Running DeepScaleR-1.5B with vLLM on DigitalOcean”

The researchers also conducted ablation studies, with superior performance justifying the training approach of combining SFT with RL. Additionally, an interesting comparative study, SFT memorizes, RL generalizes, may help with providing an intuition around how this post-training strategy could be effective for multimodal models.
In the next section, we will elaborate on how the model performed on both existing benchmarks and the newly developed benchmark, R1-Onevision.
Model Performance
The benchmarks the researchers looked at when evaluating the performance of R1-Onevision in comparison to other models include MathVista, MathVision, MathVerse, and WeMath.

As evident from the table, R1-Onevision achieves superior performance on MathVerse. Furthermore, it trails only GPT-4o on MathVision and WeMath, and similarly demonstrates the second-best performance on MathVista, closely following InternVL2.5-8B.
Benchmark Creation: R1-Onevision-Bench
To align with cognitive growth, R1-Onevision-Bench features tests designed for junior high school, high school, and college levels, as well as a social reasoning evaluation. This structure allows for the measurement of reasoning skills across various developmental stages and real-world contexts.
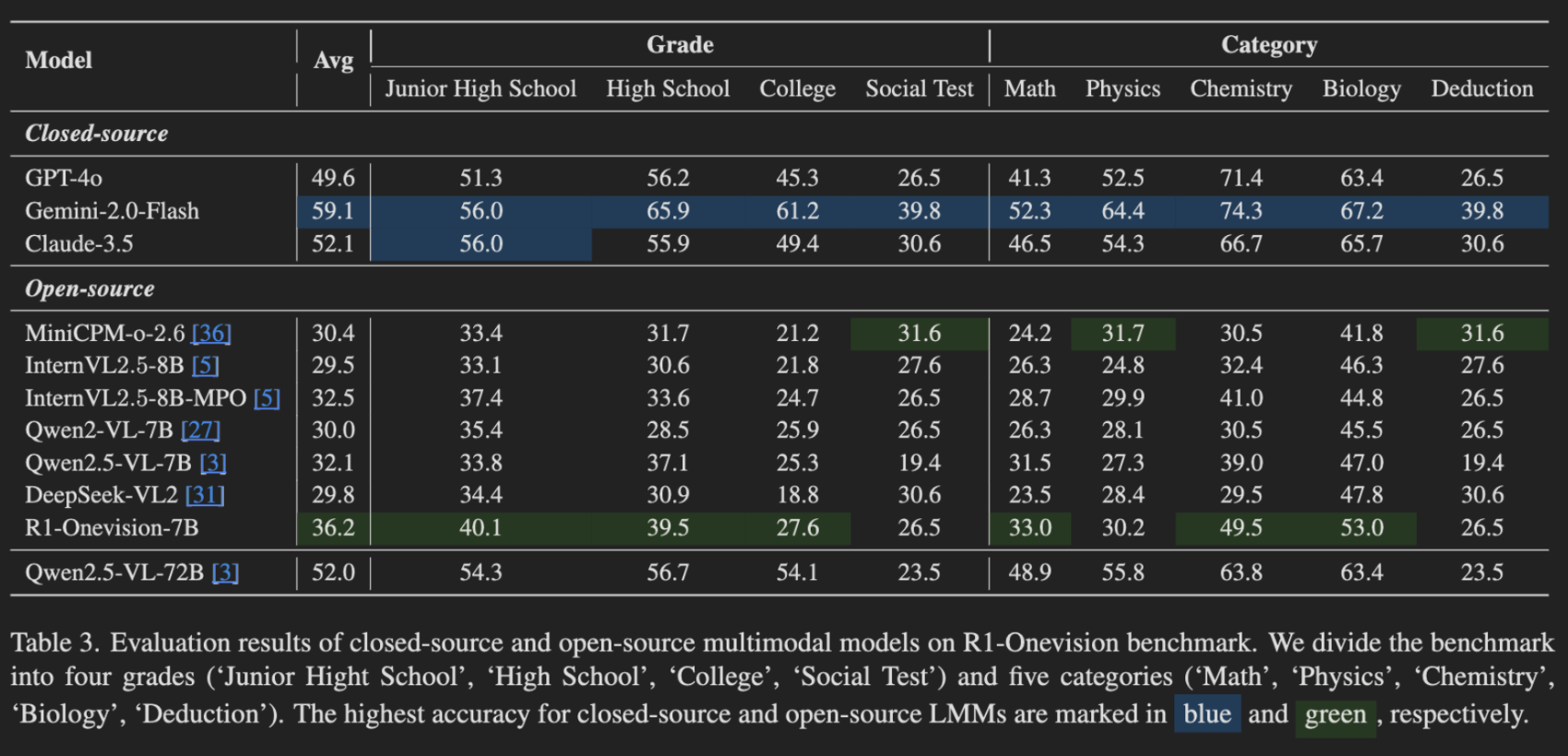
Among all models, Gemini-2.0-Flash stands out as the top performer, achieving the highest average score and excelling in several categories. Claude-3.5 ties with Gemini-2.0-Flash for the Junior High School category.
Among open-source models, R1-Onevision excels on average, achieving top performance in all categories except the Social Test, Physics, and Deduction. In those categories, MiniCPM-o-2.6 scores the highest.
Implementation
In this implementation, we will show you how you can run R1-Onevision on a GPU Droplet.
After setting up a GPU Droplet, enter these commands into the Web Console.
apt install python3-pip python3.10-venv pip install gradio_client
SSH into your preferred code editor (ex: Cursor) and create a new Python file. Copy and paste the provided code into the file, then modify it by replacing the image path with the location of your chosen image and inputting your desired text.
from gradio_client import Client, handle_file
client = Client("Fancy-MLLM/R1-Onevision")
result = client.predict(
image=handle_file('IMAGE PATH/LINK HERE'),
text_input="TEXT PROMPT HERE",
model_id="Fancy-MLLM/R1-Onevision-7B",
api_name="/run_example"
)
print(result)
| Parameter | Description |
|---|---|
| image | Path or url to the image |
| text_input | Text prompt |
Conclusion
Wow, that was a lot of content! This article provides an overview of R1-Onevision’s training, focusing on the construction of the R1-Onevision Dataset and the subsequent post-training optimization that occured through Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). Additionally, we looked at R1-Onevision’s performance in comparison to other models across benchmarks like MathVista, MathVision, MathVerse , and WeMath as well as R1-Onevision-Bench. Finally, we showed how you can run the model on a DigitalOcean GPU Droplet. We hope this article provides valuable insights into the training process of multimodal models like R1-Onevision.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.