
Relu or Rectified Linear Activation Function is the most common choice of activation function in the world of deep learning. Relu provides state of the art results and is computationally very efficient at the same time.
The basic concept of Relu activation function is as follows:
Return 0 if the input is negative otherwise return the input as it is.
We can represent it mathematically as follows:
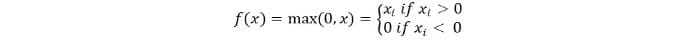
The pseudo code for Relu is as follows:
if input > 0:
return input
else:
return 0
In this tutorial, we will learn how to implement our own ReLu function, learn about some of its disadvantages and learn about a better version of ReLu.
Recommended read: Linear Algebra for Machine Learning [Part 1/2]
Let’s get started!
Implementing ReLu function in Python
Let’s write our own implementation of Relu in Python. We will use the inbuilt max function to implement it.
The code for ReLu is as follows :
def relu(x):
return max(0.0, x)
To test the function, let’s run it on a few inputs.
x = 1.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -10.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 0.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 15.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -20.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
Complete Code
The complete code is given below :
def relu(x):
return max(0.0, x)
x = 1.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -10.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 0.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = 15.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
x = -20.0
print('Applying Relu on (%.1f) gives %.1f' % (x, relu(x)))
Output :
Applying Relu on (1.0) gives 1.0
Applying Relu on (-10.0) gives 0.0
Applying Relu on (0.0) gives 0.0
Applying Relu on (15.0) gives 15.0
Applying Relu on (-20.0) gives 0.0
Gradient of ReLu function
Let’s see what would be the gradient (derivative) of the ReLu function. On differentiating we will get the following function :
f'(x) = 1, x>=0
= 0, x<0
We can see that for values of x less than zero, the gradient is 0. This means that weights and biases for some neurons are not updated. It can be a problem in the training process.
To overcome this problem, we have the Leaky ReLu function. Let’s learn about it next.
Leaky ReLu function
The Leaky ReLu function is an improvisation of the regular ReLu function. To address the problem of zero gradient for negative value, Leaky ReLu gives an extremely small linear component of x to negative inputs.
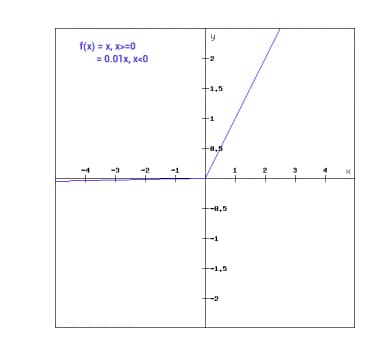
Mathematically we can express Leaky ReLu as:
f(x)= 0.01x, x<0
= x, x>=0
Mathematically:
- f(x)=1 (x<0)
- (αx)+1 (x>=0)(x)
Here a is a small constant like the 0.01 we’ve taken above.
Graphically it can be shown as :
The gradient of Leaky ReLu
Let’s calculate the gradient for the Leaky ReLu function. The gradient can come out to be:
f'(x) = 1, x>=0
= 0.01, x<0
In this case, the gradient for negative inputs is non-zero. This means that all the neuron will be updated.
Implementing Leaky ReLu in Python
The implementation for Leaky ReLu is given below :
def relu(x):
if x>0 :
return x
else :
return 0.01*x
Let’s try it out onsite inputs.
x = 1.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -10.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 0.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 15.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -20.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
Complete Code
The complete code for Leaky ReLu is given below :
def leaky_relu(x):
if x>0 :
return x
else :
return 0.01*x
x = 1.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -10.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 0.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = 15.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
x = -20.0
print('Applying Leaky Relu on (%.1f) gives %.1f' % (x, leaky_relu(x)))
Output :
Applying Leaky Relu on (1.0) gives 1.0
Applying Leaky Relu on (-10.0) gives -0.1
Applying Leaky Relu on (0.0) gives 0.0
Applying Leaky Relu on (15.0) gives 15.0
Applying Leaky Relu on (-20.0) gives -0.2
Conclusion
This tutorial was about the ReLu function in Python. We also saw an improved version of the ReLu function. The Leaky ReLu solves the problem of zero gradients for negative values in the ReLu function.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
