By Meghna Gangwar

Web Scraping is the programming-based technique for extracting relevant information from websites and storing it in the local system for further use.
In modern times, web scraping has a lot of applications in the fields of Data Science and Marketing. Web scrapers across the world gather tons of information for either personal or professional use. Moreover, present-day tech giants rely on such web scraping methods to fulfill the needs of their consumer base.
In this article, we will be scraping product information from Amazon websites. Accordingly, we will take considering a “Playstation 4” as the target product.
Note: The website layout and tags might change over time. Therefore the reader is advised to understand the concept of scraping so that self-implementation does not become an issue.
Web Scraping Services
If you want to build a service using web scraping, you might have to go through IP Blocking as well as proxy management. It’s good to know underlying technologies and processes, but for bulk scraping, it’s better to work with scraping API providers like Zenscrape. They even take care of Ajax requests and JavaScript for dynamic pages. One of their popular offerings is residential proxy service.
Some basic requirements:
In order to make a soup, we need proper ingredients. Similarly, our fresh web scraper requires certain components.
- Python - The ease of use and a vast collection of libraries make Python the numero-uno for scraping websites. However, if the user does not have it pre-installed, refer here.
- Beautiful Soup - One of the many Web Scraping libraries for Python. The easy and clean usage of the library makes it a top contender for web scraping. After a successful installation of Python, user can install Beautiful Soup by:
pip install bs4
- Basic Understanding of HTML Tags - Refer to this tutorial for gaining necessary information about HTML tags.
- Web Browser - Since we have to toss out a lot of unnecessary information from a website, we need specific ids and tags for filtering. Therefore, a web browser like Google Chrome or Mozilla Firefox serves the purpose of discovering those tags.
Creating a User-Agent
Many websites have certain protocols for blocking robots from accessing data. Therefore, in order to extract data from a script, we need to create a User-Agent. The User-Agent is basically a string that tells the server about the type of host sending the request.
This website contains tons of user agents for the reader to choose from. Following is an example of a User-Agent within the header value.
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
There is an extra field in HEADERS called “Accept-Language”, which translates the webpage to English-US, if needed.
Sending a request to a URL
A webpage is accessed by its URL (Uniform Resource Locator). With the help of the URL, we will send the request to the webpage for accessing its data.
URL = "https://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/"
webpage = requests.get(URL, headers=HEADERS)
The requested webpage features an Amazon product. Hence, our Python script focuses on extracting product details like “The Name of the Product”, “The Current Price” and so on.
Note: The request to the URL is sent via
"requests"library. In case the user gets a “No module named requests” error, it can be installed by"pip install requests".
Creating a soup of information
The webpage variable contains a response received by the website. We pass the content of the response and the type of parser to the Beautiful Soup function.
soup = BeautifulSoup(webpage.content, "lxml")
lxml is a high-speed parser employed by Beautiful Soup to break down the HTML page into complex Python objects. Generally, there are four kinds of Python Objects obtained:
- Tag - It corresponds to HTML or XML tags, which include names and attributes.
- NavigableString - It corresponds to the text stored within a tag.
- BeautifulSoup - In fact, the entire parsed document.
- Comments - Finally, the leftover pieces of the HTML page that is not included in the above three categories.
Discovering the exact tags for Object Extraction
One of the most hectic part of this project is unearthing the ids and tags storing the relevant information. As mentioned before, we use web browsers for accomplishing this task.
We open the webpage in the browser and inspect the relevant element by pressing right-click.
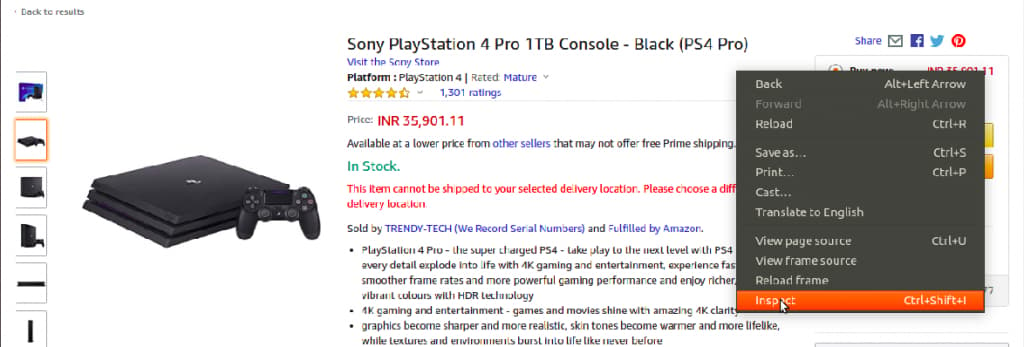
As a result, a panel opens on the right-hand side of the screen as shown in the following figure.
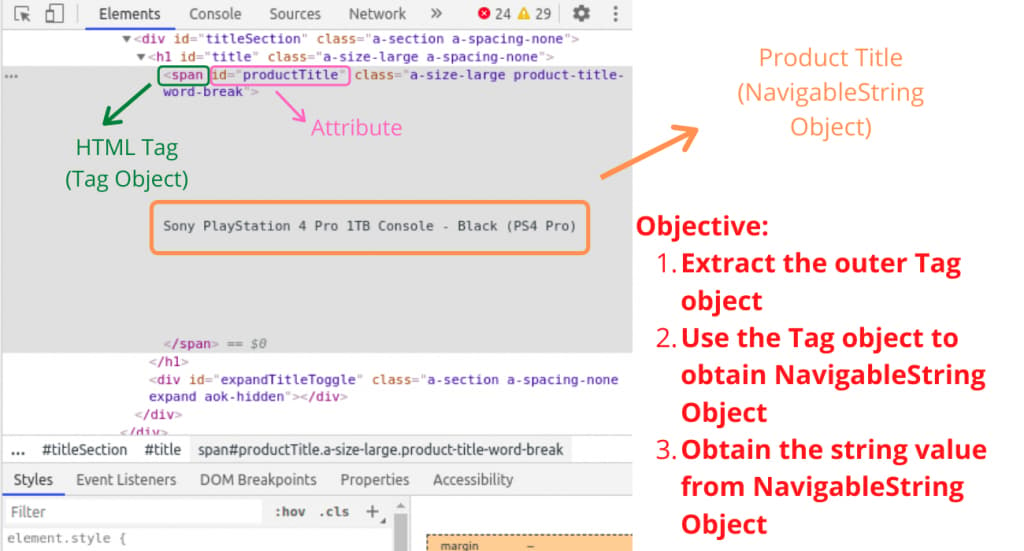
Once we obtain the tag values, extracting information becomes a piece of cake. However, we must learn certain functions defined for Beautiful Soup Object.
Extracting the Product Title
Using the find() function available for searching specific tags with specific attributes we locate the Tag Object containing title of the product.
# Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
Then, we take out the NavigableString Object
# Inner NavigableString Object
title_value = title.string
And finally, we strip extra spaces and convert the object to a string value.
# Title as a string value
title_string = title_value.strip()
We can take a look at types of each variable using type() function.
# Printing types of values for efficient understanding
print(type(title))
print(type(title_value))
print(type(title_string))
print()
# Printing Product Title
print("Product Title = ", title_string)
Output:
<class 'bs4.element.Tag'>
<class 'bs4.element.NavigableString'>
<class 'str'>
Product Title = Sony PlayStation 4 Pro 1TB Console - Black (PS4 Pro)
In the same way, we need to figure out the tag values for other product details like “Price of the Product” and “Consumer Ratings”.
Python Script to extract product information
The following Python script displays the following details for a product:
- The Title of the Product
- The Price of the Product
- The Rating of the Product
- Number of Customer Reviews
- Product Availability
from bs4 import BeautifulSoup
import requests
# Function to extract Product Title
def get_title(soup):
try:
# Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
# Inner NavigableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip()
# # Printing types of values for efficient understanding
# print(type(title))
# print(type(title_value))
# print(type(title_string))
# print()
except AttributeError:
title_string = ""
return title_string
# Function to extract Product Price
def get_price(soup):
try:
price = soup.find("span", attrs={'id':'priceblock_ourprice'}).string.strip()
except AttributeError:
price = ""
return price
# Function to extract Product Rating
def get_rating(soup):
try:
rating = soup.find("i", attrs={'class':'a-icon a-icon-star a-star-4-5'}).string.strip()
except AttributeError:
try:
rating = soup.find("span", attrs={'class':'a-icon-alt'}).string.strip()
except:
rating = ""
return rating
# Function to extract Number of User Reviews
def get_review_count(soup):
try:
review_count = soup.find("span", attrs={'id':'acrCustomerReviewText'}).string.strip()
except AttributeError:
review_count = ""
return review_count
# Function to extract Availability Status
def get_availability(soup):
try:
available = soup.find("div", attrs={'id':'availability'})
available = available.find("span").string.strip()
except AttributeError:
available = ""
return available
if __name__ == '__main__':
# Headers for request
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
# The webpage URL
URL = "https://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/"
# HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# Function calls to display all necessary product information
print("Product Title =", get_title(soup))
print("Product Price =", get_price(soup))
print("Product Rating =", get_rating(soup))
print("Number of Product Reviews =", get_review_count(soup))
print("Availability =", get_availability(soup))
print()
print()
Output:
Product Title = Sony PlayStation 4 Pro 1TB Console - Black (PS4 Pro)
Product Price = $473.99
Product Rating = 4.7 out of 5 stars
Number of Product Reviews = 1,311 ratings
Availability = In Stock.
Now that we know how to extract information from a single amazon webpage, we can apply the same script to multiple webpages by simply changing the URL.
Moreover, let us now attempt to fetch links from an Amazon search results webpage.
Fetching links from an Amazon search result webpage
Previously, we obtained information about a random PlayStation 4. It would be a resourceful idea to extract such information for multiple PlayStations for comparison of prices and ratings.
We can find a link enclosed in a <a><\a> tag as a value for the href attribute.
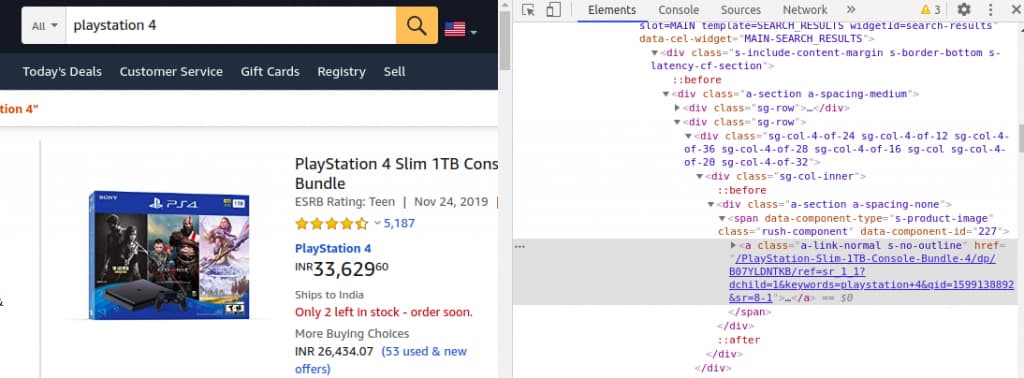
instead of fetching a single link, we can extract all the similar links using find_all() function.
# Fetch links as List of Tag Objects
links = soup.find_all("a", attrs={'class':'a-link-normal s-no-outline'})
The find_all() function returns an iterable object containing multiple Tag objects. As a result, we pick each Tag object and pluck out the link stored as a value for href attribute.
# Store the links
links_list = []
# Loop for extracting links from Tag Objects
for link in links:
links_list.append(link.get('href'))
We store the links inside a list so that we can iterate over each link and extract product details.
# Loop for extracting product details from each link
for link in links_list:
new_webpage = requests.get("https://www.amazon.com" + link, headers=HEADERS)
new_soup = BeautifulSoup(new_webpage.content, "lxml")
print("Product Title =", get_title(new_soup))
print("Product Price =", get_price(new_soup))
print("Product Rating =", get_rating(new_soup))
print("Number of Product Reviews =", get_review_count(new_soup))
print("Availability =", get_availability(new_soup))
We reuse the functions created before for extracting product information. Even though this process of producing multiple soups makes the code slow, but in turn, provides a proper comparison of prices between multiple models and deals.
Python Script to extract product details across multiple webpages
Below is the complete working Python script for listing multiple PlayStation deals.
from bs4 import BeautifulSoup
import requests
# Function to extract Product Title
def get_title(soup):
try:
# Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
# Inner NavigatableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip()
# # Printing types of values for efficient understanding
# print(type(title))
# print(type(title_value))
# print(type(title_string))
# print()
except AttributeError:
title_string = ""
return title_string
# Function to extract Product Price
def get_price(soup):
try:
price = soup.find("span", attrs={'id':'priceblock_ourprice'}).string.strip()
except AttributeError:
try:
# If there is some deal price
price = soup.find("span", attrs={'id':'priceblock_dealprice'}).string.strip()
except:
price = ""
return price
# Function to extract Product Rating
def get_rating(soup):
try:
rating = soup.find("i", attrs={'class':'a-icon a-icon-star a-star-4-5'}).string.strip()
except AttributeError:
try:
rating = soup.find("span", attrs={'class':'a-icon-alt'}).string.strip()
except:
rating = ""
return rating
# Function to extract Number of User Reviews
def get_review_count(soup):
try:
review_count = soup.find("span", attrs={'id':'acrCustomerReviewText'}).string.strip()
except AttributeError:
review_count = ""
return review_count
# Function to extract Availability Status
def get_availability(soup):
try:
available = soup.find("div", attrs={'id':'availability'})
available = available.find("span").string.strip()
except AttributeError:
available = "Not Available"
return available
if __name__ == '__main__':
# Headers for request
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US'})
# The webpage URL
URL = "https://www.amazon.com/s?k=playstation+4&ref=nb_sb_noss_2"
# HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# Fetch links as List of Tag Objects
links = soup.find_all("a", attrs={'class':'a-link-normal s-no-outline'})
# Store the links
links_list = []
# Loop for extracting links from Tag Objects
for link in links:
links_list.append(link.get('href'))
# Loop for extracting product details from each link
for link in links_list:
new_webpage = requests.get("https://www.amazon.com" + link, headers=HEADERS)
new_soup = BeautifulSoup(new_webpage.content, "lxml")
# Function calls to display all necessary product information
print("Product Title =", get_title(new_soup))
print("Product Price =", get_price(new_soup))
print("Product Rating =", get_rating(new_soup))
print("Number of Product Reviews =", get_review_count(new_soup))
print("Availability =", get_availability(new_soup))
print()
print()
Output:
Product Title = SONY PlayStation 4 Slim 1TB Console, Light & Slim PS4 System, 1TB Hard Drive, All the Greatest Games, TV, Music & More
Product Price = $357.00
Product Rating = 4.4 out of 5 stars
Number of Product Reviews = 32 ratings
Availability = In stock on September 8, 2020.
Product Title = Newest Sony Playstation 4 PS4 1TB HDD Gaming Console Bundle with Three Games: The Last of Us, God of War, Horizon Zero Dawn, Included Dualshock 4 Wireless Controller
Product Price = $469.00
Product Rating = 4.6 out of 5 stars
Number of Product Reviews = 211 ratings
Availability = Only 14 left in stock - order soon.
Product Title = PlayStation 4 Slim 1TB Console - Fortnite Bundle
Product Price =
Product Rating = 4.8 out of 5 stars
Number of Product Reviews = 2,715 ratings
Availability = Not Available
Product Title = PlayStation 4 Slim 1TB Console - Only On PlayStation Bundle
Product Price = $444.00
Product Rating = 4.7 out of 5 stars
Number of Product Reviews = 5,190 ratings
Availability = Only 1 left in stock - order soon.
The above Python script is not restricted to the list of PlayStations. We can switch the URL to some other link to an Amazon search result, like headphones or earphones.
As mentioned before, the layout and tags of an HTML page may change over time making the above code worthless in this regard. However, the reader must bring home the concept of web scraping and techniques learnt in this article.
Conclusion
There can be various advantages of Web Scraping ranging from “comparing product prices” to “analyzing consumer tendencies”. Since the internet is accessible to everyone and Python is a very easy language, anyone can perform Web Scraping to meet their needs.
We hope this article was easy to understand. Feel free to comment below for any queries or feedback. Until then, Happy Scraping!!!.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
