
Introduction
Our world is becoming increasingly digital. The transformative arc of digital innovation, from personal computing’s early days to the proliferation of email, social media, and e-commerce, the collective shift towards remote work as well as the adoption of Large Language Models and Agentic AI, has ignited an unprecedented need to digitize and extract information. Here, effective document processing acts as a bridge between the physical and digital worlds, capturing the essence of printed text and giving it life in the digital realm. It’s the technology that lets your phone translate foreign menu items, helps historians preserve ancient literature, and saves countless hours of manual data entry.
At its core, document processing involves converting images of text into machine-readable formats, facilitating use-cases like document conversion and understanding. Document conversion involves transforming scanned text into formats like Markdown, Word, or PDF, while document understanding goes beyond simple text recognition to extract meaningful insights and structure from the content.
SmolDocling
Enter SmolDocling, a compact multimodal vision language model designed for efficient document processing. At only 256 million parameters, it provides full-page conversion while preserving document layout, structure, and spatial positioning. Its small size offers a cost-effective option for document processing by requiring less computational power and memory, ideal for rapid prototyping and edge devices.
Prerequisites
For optimal performance, SmolDocling requires NVIDIA GPUs with CUDA support. DigitalOcean GPU Droplets with H100 GPUs offer the computational power needed for efficient processing at production scale.
Features and Capabilities
SmolDocling processes documents using DocTags, a markup format that captures context and layout information. It preserves formatting with bounding box detection and supports specialized recognition for code, formulas, charts, tables, and figures. The model maintains document structure by handling list grouping and caption linking.
The DocTags format identifies the type, location, and content of elements like text, tables, pictures, and code. DocTags uses nested tags to preserve relationships between elements - captions within pictures, items within lists, and specialized Optimized Table-Structure Language (OTSL) notation for table structures. This approach maintains both the visual organization and semantic structure of complex documents, making SmolDocling effective for end-to-end document conversion tasks.
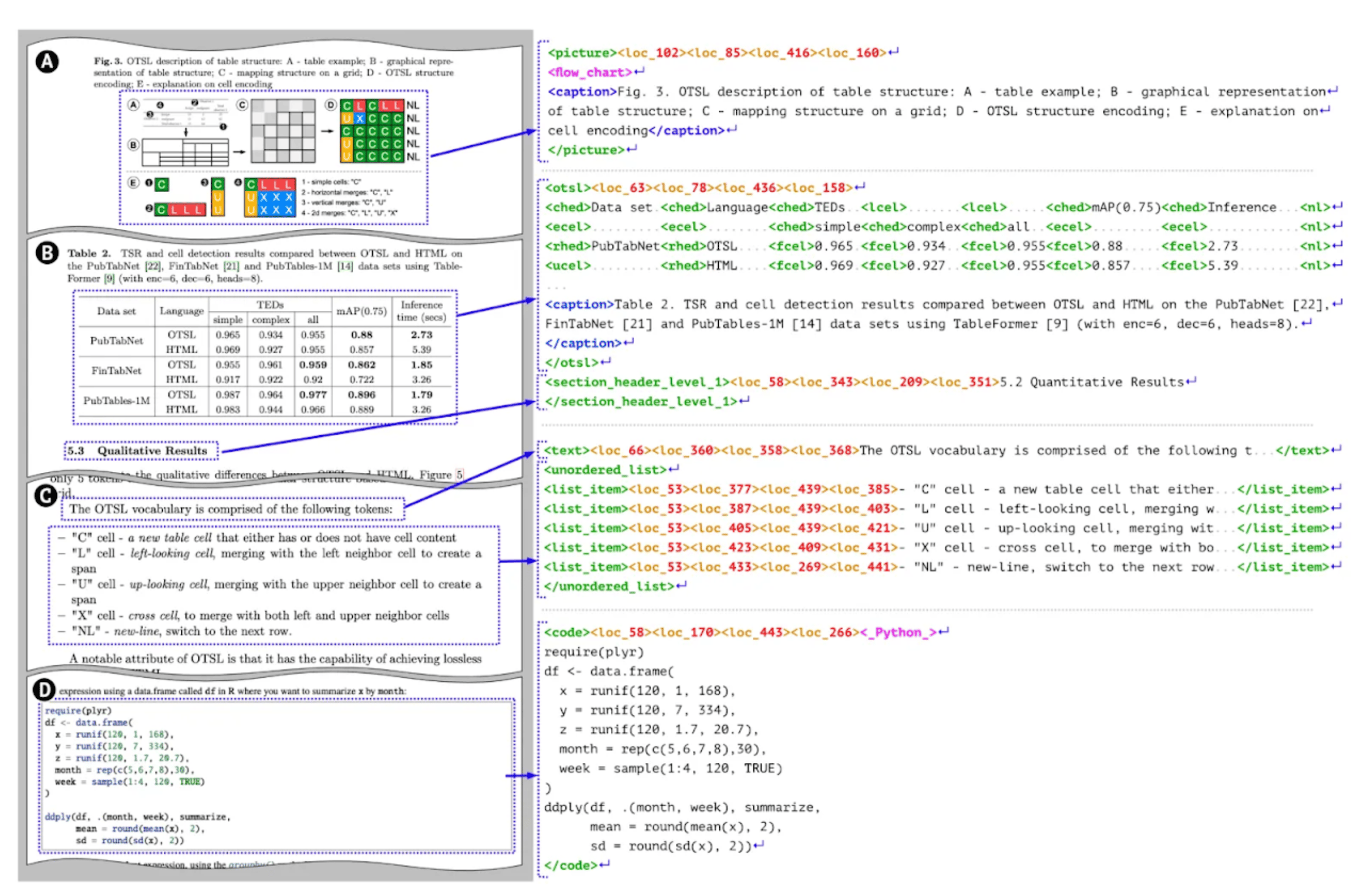
| Tag Type | Description |
|---|---|
| XML-like Syntax | Uses XML-style notation with opening/closing tags for text blocks and standalone tags for instructions (e.g., <text>hello world</text>, <page_break>) |
| Document Structure | Complete DocTags snippets enclosed in <doctag>…</doctag> can represent single or multiple pages separated by <page_break> tags |
| Block Type Tags | <text>, <caption>, <footnote>, <formula>, <title>, <page_footer>, <page_header>, <picture>, <section_header>, <document_index>, <code>, <otsl>, <list_item>, <ordered_list>, <unordered_list> |
| Location Encoding | Elements can include nested location tags specifying bounding box coordinates: <loc_x1><loc_y1><loc_x2><loc_y2> (0-500 grid system) |
| Table Structure | Incorporates OTSL vocabulary for tables with extensions: <fcel> (full cell), <ecel> (empty cell), <ched> (column headers), <rhed> (row headers), <srow> (table sections) |
| List Handling | <list_item> elements within <ordered_list> or <unordered_list> define list type |
| Captions | <picture> and <otsl> elements can encapsulate a <caption> tag for descriptive information |
| Code Handling | <code> elements preserve formatting and include <_programming-language_> classification tag (57 languages supported) |
| Image Classification | <picture> elements include <image_class> tags for 20+ image types including charts, diagrams, codes, etc. |
| Uniform Representation | Cropped page elements maintain the same DocTags representation as full-page counterparts |
Additional features of SmolDocling are summarized below:
| Feature | Description |
|---|---|
| OCR + Layout Preservation | Extracts text while maintaining spatial structure |
| Specialized Recognition | Supports code blocks, formulas, tables, and charts |
| Full-Page Conversion | Processes all elements simultaneously |
| Fast Inference | 0.35 seconds per page on A100 GPUs |
| DocTags Markup | Captures document content and layout in a structured format |
SmolDocling integrates with Docling for import and export flexibility. The roadmap includes one-shot multi-page inference, enhanced chart recognition, and chemical structure detection.
Model Architecture
SmolDocling is based on SmolVLM, a model from HuggingFace.
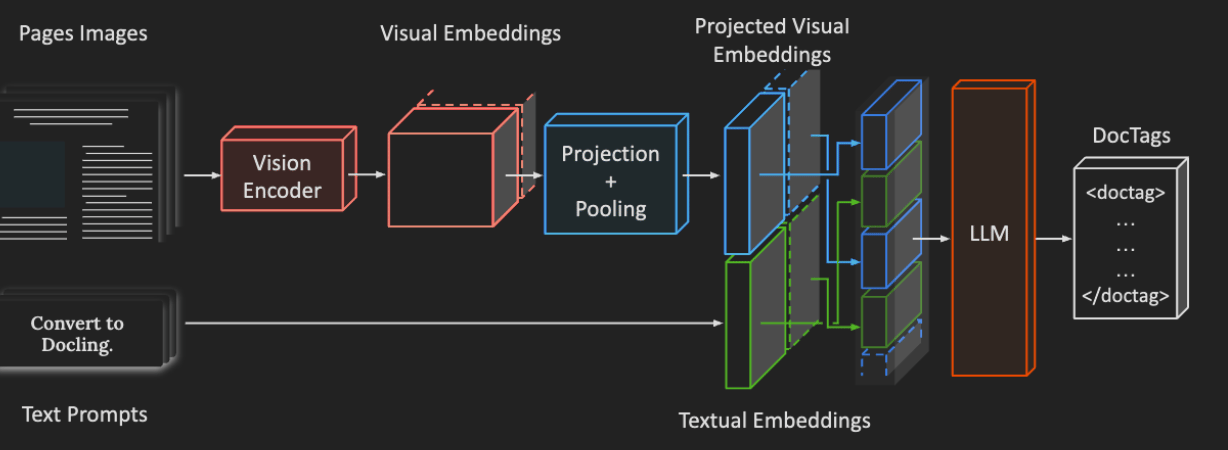
Let’s go over the process of how SmolDocling converts images of document pages to DocTags sequences. First, the input images are processed through a vision encoder and then reshaped using projection and pooling techniques. Next, these processed image embeddings are combined with the text embeddings derived from the user’s prompt, interleaving them. Finally, this combined sequence is fed into an LLM to autoregressively generate the DocTags sequence.
Data
Different collections of datasets were used to improve the model for different capabilities. Datasets used to train to emphasize document understanding and image captioning include The Cauldron, Docmatix, and MathWriting.
Competitive Performance
SmolDocling competes with models up to 27 times larger while reducing computational requirements. It performs well on business documents, academic papers, technical reports, patents, and forms. Unlike many OCR models that focus on scientific papers, SmolDocling is designed for a wide range of document types.
The model is available now, and additional datasets for charts, tables, equations, and code recognition will be released soon.
Implementing SmolDocling with DigitalOcean GPU Droplets
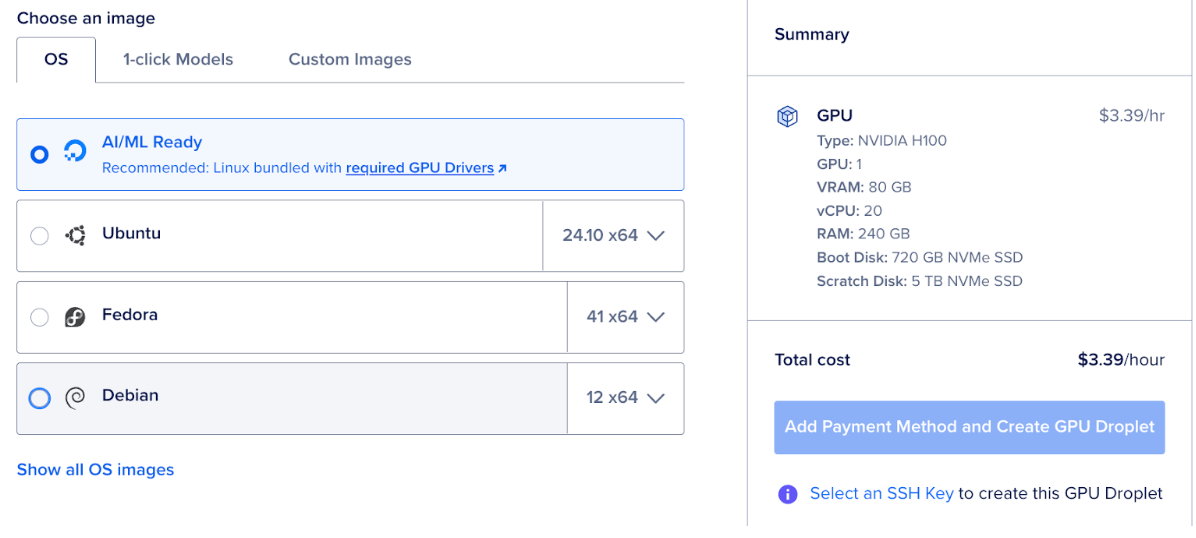
To run SmolDocling, set up a DigitalOcean GPU Droplet, select AI/ML and choose the NVIDA H100 option.
Launch the model in the web console using vLLM:
# Install pip:
apt install python3-pip
# Install vLLM from pip:
pip install vllm
# Load and run the model:
vllm serve "ds4sd/SmolDocling-256M-preview"
We will be passing in this image for OCR.

# Call the server using curl:
#replace url with your image
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "ds4sd/SmolDocling-256M-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe this image in one sentence."
},
{
"type": "image_url",
"image_url": {
"url": "https://i.sstatic.net/IvV2y.png"
}
}
]
}
]
}'
This script processes images/PDF files and outputs structured document data in JSON format.
Conclusion
In this tutorial, we’ve explored SmolDocling, a compact yet powerful vision language model designed specifically for document conversion tasks. By leveraging its unified DocTags output format, we’ve seen how SmolDocling efficiently handles various document types from standard text to complex forms and even code listings while requiring significantly fewer computational resources than larger alternatives. The model’s balanced approach to efficiency and accuracy makes it an excellent choice for developers and organizations seeking to implement document understanding capabilities.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
