
Introduction
A high-availability web application setup offers advantages to developers who are looking to eliminate single points of failure and minimize downtime. Within this general framework, however, there are a number of possible variations. Developers will make choices based on the specific needs of their application and their performance goals.
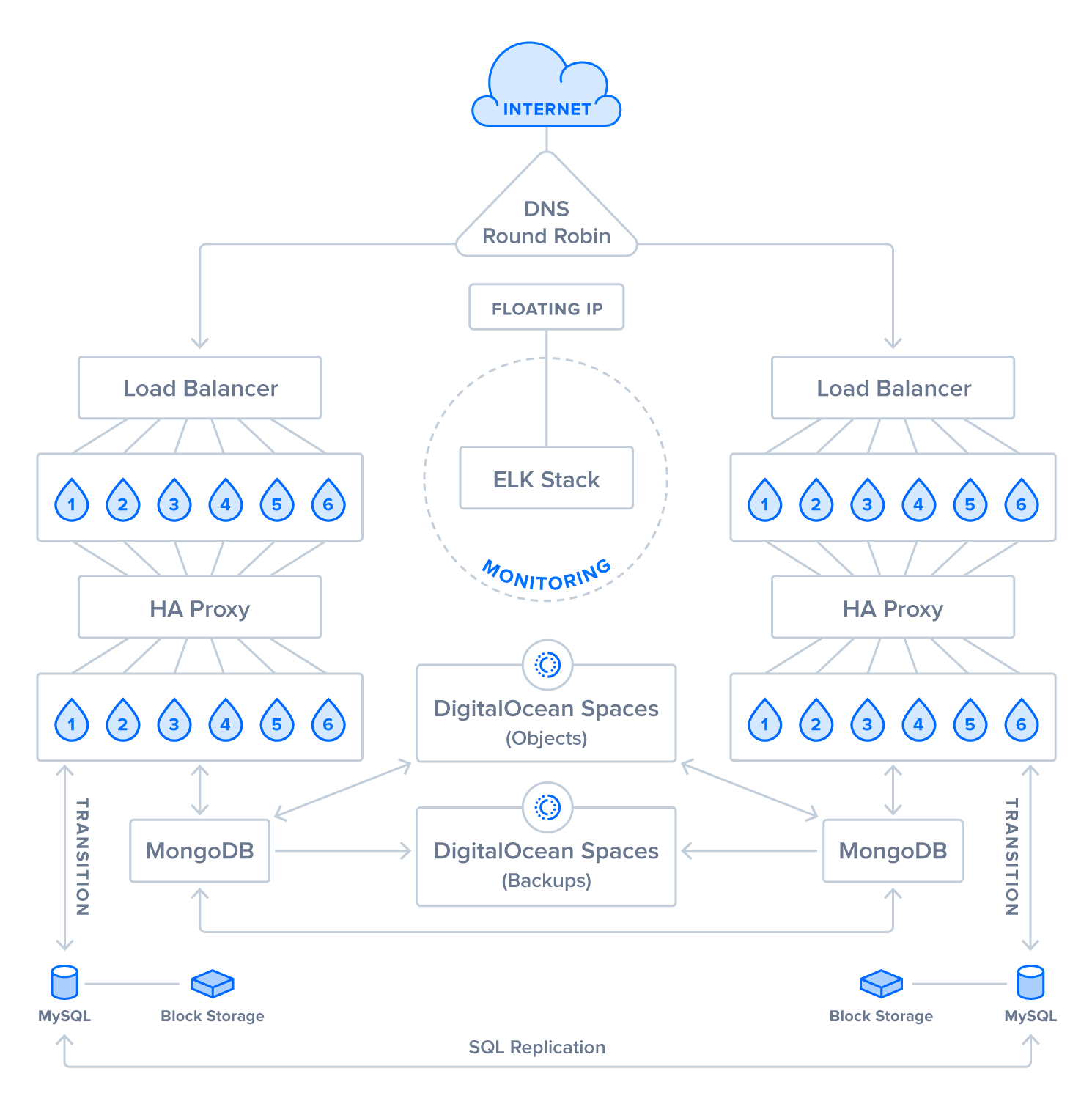
This high-availability application setup was designed as a hypothetical solution to potentially offer:
- A processing solution for images, documents, and videos, with a focus on storage, retrieval, and concatenation.
- A scorekeeping, leaderboard, or purchasing solution that could be scaled, modified, or integrated with an ecommerce solution.
- A blogging solution that could also be integrated with an ecommerce solution.
In this article, we will go over the specific features of this setup and discuss its components at a more general level. At the end of each section, we’ll link out to additional resources on the topic to support you as you consider methodologies and best practices.
Step 1: Creating Front-End Servers with Private Networking

A typical multi-tier setup separates the presentation layer from our application logic. Separating application functions into layers makes the processes of troubleshooting and scaling easier in the long term.
As we select servers and resources, we can consider the following factors:
- What type of work will we be doing with media and image assets?
- What will our compute requirements look like?
- What type and volume of traffic do we anticipate?
- What are our plans to monitor it?
Our monitoring tools will help us scale our application and build out resources at this and other levels. An additional step we can take for cost-saving and security measures is to assign our application’s resources, including our front-end servers, to a shared private network. Data can then be transferred between servers without incurring additional bandwidth costs or leaving a single datacenter.
Step 2: Creating Load Balancers for Front-End Servers

To ensure that our application’s resources remain highly available and performant, we can create load balancers to manage our front-end workload. These load balancers will redirect incoming traffic, using regular health checks and failover mechanisms to manage server failure or malfunction. They will also balance traffic more generally, making sure individual servers don’t become overloaded.
To optimize their configuration, we can consider the following factors:
- Will we be storing state information about requests and users?
- Will we need to redirect requests based on CPU loads?
These factors will enable us to select the optimal algorithm for our configuration. There is an additional security component to the load balancers’ work as well: we can configure them to listen on specific ports and to redirect traffic between ports. It is also possible to use them to decrypt messages for our back-end servers.
Step 3: Creating Back-End Servers with Private Networking

Creating our application’s backend involves another set of resource calculations. Again, the nature of our application’s work will determine the size and resources of our servers. Factors to consider include the type and volume of processing work our servers will do at this level. This is where distinctions between data types and processing tasks will come into play. If, for example, we are working with image assets and consumer data, we can consider load and latency requirements as they apply to each.
Monitoring will also be important at this level to address issues like:
- What kind of processing are we doing with image and media assets?
- Are we pulling information from these assets, or simply retrieving or recombining them?
- What volume and type of consumer transactions do we have?
We can place the resources at this level within our shared private network to account for potential bandwidth charges.
Step 4: Installing HAProxy

Similarly to how our load balancers handle external requests, HAProxy manages the flow of communication between our front-end and application layers. In its function as a load balancer, HAProxy can be configured to listen on and redirect traffic from particular ports. This can add another layer of security to our application’s internal operations. When we need to scale, we can configure HAProxy to add and remove nodes automatically.
Step 5: Creating SQL Databases

For a certain segment of our application data we will use a SQL database. This is for data that needs to be current, accurate, and consistent. Things like sales transactions, login/logoff information, and password changes, which are uniform in structure and need to be secure, make a reasonable case for the use of a SQL database.
Again, we will want to consider our metrics: How many transactional or secure requests are we processing? If our load is high, we may want to consider using tools like ProxySQL to balance incoming requests. We can take an additional step to improve performance and ensure high availability if we set up replication between our SQL databases. This will also prove useful if we need to scale our data processing.
Step 6: Creating NoSQL Databases

With data that is less uniform or schematic, we can use a NoSQL database. For pictures, videos, or blog posts, for example, a NoSQL database offers the ability to store item metadata in a non-schematic way. When using this type of solution, our data will be highly available, and its consistency will be eventual. As we think about performance, we want to consider the type and volume of requests we anticipate to these databases.
Factors that can optimize performance, depending on request load and type, include: using a load balancing solution to manage traffic between databases, distributing data across databases and storage solutions, and adding or destroying databases (rather than replicating them).
Step 7: Adding Block Storage

Our setup separates database storage functionality from our application’s other operations. The goal is to enhance the security of our data and our application’s overall performance. As another part of this isolation process, we can create a backup solution for our SQL database files. Block storage solutions such as DigitalOcean’s Block Storage volumes can do this job well, thanks to their low latency I/O, and schematic file system structure. They also offer options for scaling, since they can be easily destroyed, resized, or multiplied.
Step 8: Creating an Elastic/ELK Stack

Monitoring our application’s performance will inform the decisions we make as we scale and refine our setup. To do this work, we can use a centralized logging solution such as an Elastic/ELK stack. Our stack includes components that gather and visualize logs: Logstash, which processes logs; Elasticsearch, which stores them; and Kibana, which allows them to be searched and visually organized. If we situate this stack behind a Reserved IP, we will be able to access it remotely with a static IP. Additionally, if we include our stack in our shared private network, we will have another security advantage: our reporting agents will not need to transfer information to the stack over the internet.
Step 9: Creating Object Stores

When storing our application’s static assets, we want to ensure their availability while maintaining a high performance. Object storage solutions like DigitalOcean Spaces can meet this need. Specifically, if we decide to store large objects in our databases, they may experience performance issues with the influx of data, making our backups very large. In this scenario, we could move our data to object storage. By storing a URL in our database, we can point to our resources from the database without impacting its storage capacity. This is an optimal solution for data that we anticipate will remain static, and offers additional options for scaling.
Step 10: Configuring DNS Records

Once our high-availability setup is in place, we can point our application’s domain name to our load balancers using DNS. With a round robin algorithm, we can balance query responses between our application’s distributed resources. This will maximize the availability of these resources, while also distributing workloads across resource clusters. Additionally, we can use geographic routing to match requests to proximate resources.
Step 11: Planning for Recovery Strategy
Our recovery strategy will include tools and functions to back up and restore our data in the case of administrative or other failures. For each of our Droplets, we can leverage and automate DigitalOcean Snapshots to copy and store images of Droplets on DigitalOcean servers. Additionally, we can use dedicated tools and services such as Percona, Restic, or Bacula, along with storage devices like DigitalOcean Backups and Spaces to copy our data. As we evaluate these tools and create our strategy, we will think about the data at each layer of our application, and how often it needs to be backed up in order for us to have a reasonable point from which to restore our application’s functionality.
Conclusion
In this article, we have discussed a potential setup for a highly-available web application that depends on infrastructure components like Droplets, Load Balancers, Spaces, and Block Storage to deliver a high level of operational performance. This setup could support a processing solution for images and other media, with a focus on storage and retrieval, as well as purchasing, scorekeeping, or blogging capabilities that could be integrated with ecommerce solutions.
Ultimately, there are many directions developers can take to meet particular needs and use cases while maintaining high availability, and each application setup will reflect these differences in the specificity of its architecture.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Former Developer at DigitalOcean community. Expertise in areas including Ubuntu, Docker, Ruby on Rails, Debian, and more.
Former Developer at DigitalOcean community. Expertise in areas including Ubuntu, Docker, Ruby on Rails, Debian, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Since you’re using floating IPs, I assume you describe a setup within a single data center. But then you don’t need the DNS round robin and multiple DO load balancers as these load balancers are already implemented redundant and are not a SPOF (according to Justin Ellingwood).
This comment has been deleted
This comment has been deleted
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.