AI Technical Writer

Introduction
Deci AI’s YOLO-NAS has marked the advancement in the field of object detection with its cutting-edge foundational model. This model stands out as a result of sophisticated Neural Architecture Search technology, YOLO-NAS overcomes the gaps found in earlier YOLO models. The model successfully brings notable enhancements in areas such as quantization support and finding the right balance between accuracy and latency. This marks a significant advancement in the field of object detection.
YOLO-NAS includes quantization blocks which involves converting the weights, biases, and activations of a neural network from floating-point values to integer values (INT8), resulting in enhanced model efficiency. The transition to its INT8 quantized version results in a minimal precision reduction. This has marked as a major improvement when compared to other YOLO models.
These small enhancements resulted in an exceptional architecture, delivering unique object detection capabilities and outstanding performance.

Evolution of YOLO: A Foundational Object Detection Model
Prerequisites for YOLO
- Python : Ensure Python is installed.
- PyTorch: Install PyTorch with GPU support (pip install torch torchvision).
- CUDA Toolkit: For GPU acceleration (NVIDIA drivers required).
- OpenCV: For image processing (pip install opencv-python).
About the Article
This article provides an overview of YOLO-NAS, an innovative model for object detection. The article begins with a concise exploration of the model’s architecture, followed by an in-depth explanation of the Auto NAC concept. Additionally, the article offers a comparative analysis of YOLO-NAS within the broader YOLO series.
YOLO-NAS - A New Object Detection Foundation Model
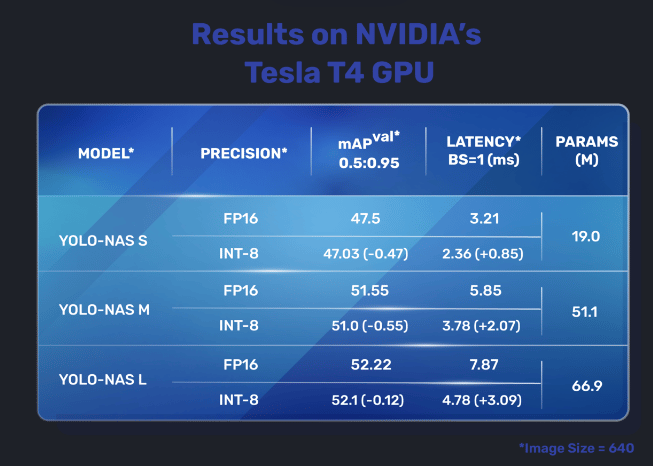
YOLO-NAS outshines its predecessors with a 20.5% performance boost over YOLOv7, slightly surpassing YOLOv5 by over 11%, and showing a 1.75% improvement compared to YOLOv8. Developed by Deci, YOLO-NAS stands as the latest addition to the YOLO model series, boasting its fastest model with a latency of just 2.36 milliseconds and a MAP (mean average precision) of 47.
Deci designed YOLO-NAS to overcome key limitations seen in current YOLO models, addressing issues like insufficient quantization support and accuracy-latency trade-offs. This effort has significantly expanded the capabilities of real-time object detection, pushing the boundaries of what’s possible in the field.
NAS models undergoes pre-training on the Object 365 dataset, consisting of 365 categories with a vast collection of 2 million images and 30 million bounding boxes. Subsequently, they undergo training on 118,000 pseudo-labeled images extracted from Coco unlabeled images. The training process is further enriched through the integration of knowledge distillation and Distribution Focal Loss (DFL). During pre-training, knowledge distillation is employed to enhance performance. A teacher model generates predictions, serving as soft targets for the student model, which strives to match them while adjusting for the original labeled data. This approach mitigates overfitting and enhances accuracy, particularly beneficial in scenarios where labeled data is limited. Additionally, the integration of distribution focal loss (DFL) further refines the training process, addressing class imbalance and boosting detection accuracy for underrepresented classes.
YOLO-NAS has three models. The small model, medium and large model. These models are also quantized into INT8. The quantized models have a very small drop in accuracy.
Neural Architecture Search
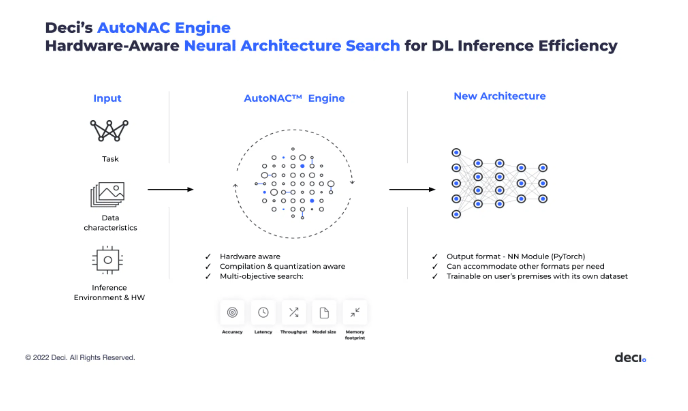
YOLO-NAS employs optimization algorithms like Automated Neural Architecture Construction or AutoNAC. The Automated Neural Architecture Construction (AutoNAC) technology is like a smart tool that makes the most out of any computer hardware. It has a part called Neural Architecture Search (NAS), which can improve, how quickly a computer understands and processes information (throughput), how fast it responds (latency), and how efficiently it uses memory. This NAS component redesigns an already trained computer model to work even better on specific types of hardware, all while keeping its basic accuracy.
AutoNAC is a special technology developed by Deci, and it’s what makes their Deep Learning Acceleration Platform work well. This technology increases the inference performance of a trained model on a specific hardware, optimizing throughput, latency, and memory utilization while maintaining baseline accuracy. AutoNAC is a proprietary technology powering Deci’s Deep Learning Acceleration Platform.
Multiple quantization-aware RepVGG blocks combines to form quantization-aware QSP and QCI blocks, creating YOLO-NAS models through permutations as depicted in the video. These blocks are based on a methodology proposed by Chu et al., ensuring minimal accuracy loss in post-training quantization.
0:00
/0:13
1×
AutoNAC Architecture
Performance of YOLO-NAS
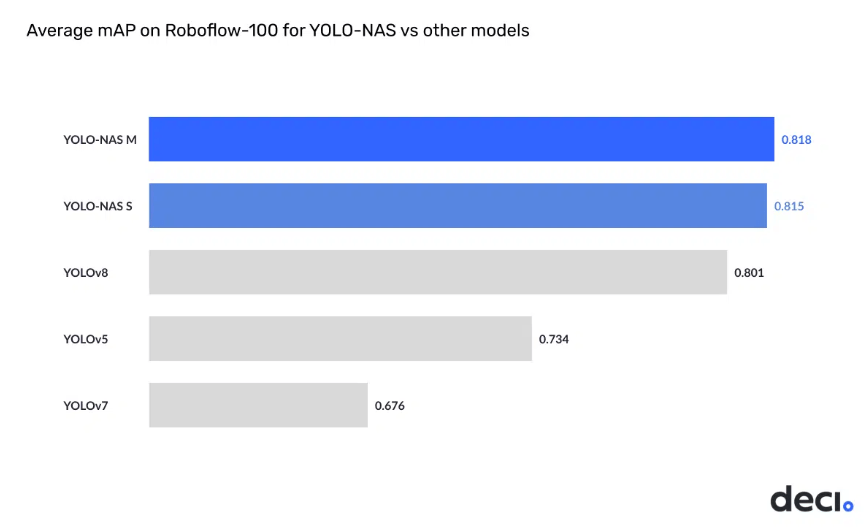
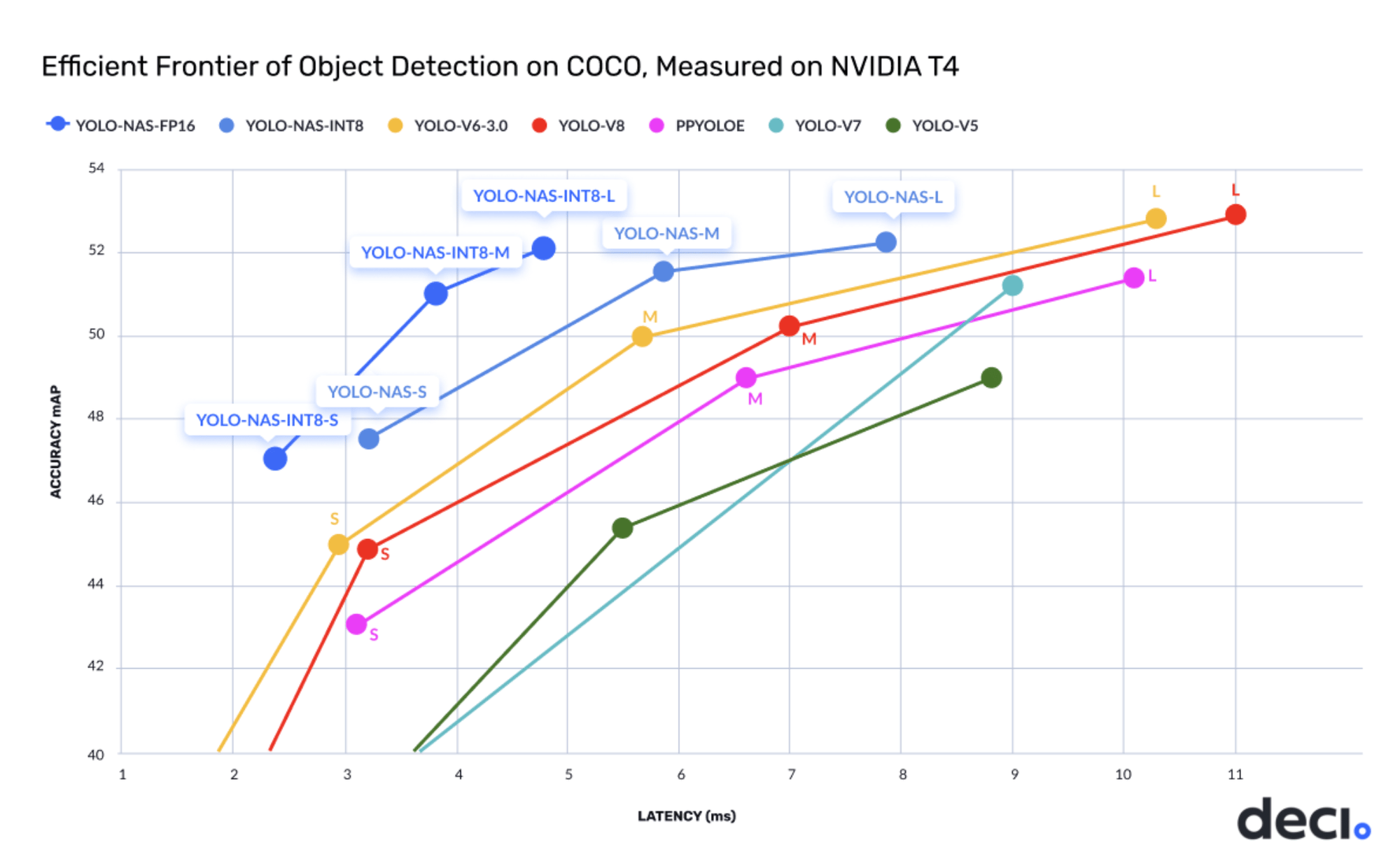
The YOLO-NAS showcases State-of-the-Art performance, outperforming other models such as YOLOv5, YOLOv6, YOLOv7, and YOLOv8, with an unparalleled combination of accuracy and speed. Examining the below graph reveals that all iterations of YOLO-NAS—small, medium, and large, both with and without quantization—achieves impressive accuracy. Furthermore, the Mean Average Precision (MAP) value has notably increased compared to the previous State-of-the-Art mode.
Benchmarking YOLO series model
Model
mAP
%improvement
YOLO-NAS
0.815
-
YOLO-v7
0.676
20.56%
YOLO-v5
0.734
11.04%
YOLO-v8
0.801
1.75%
In the field of AI research, the growing complexity of deep learning models has spurred a surge in diverse applications. Nevertheless, deploying these models on cloud platforms requires a significant computational resources, translating to substantial costs for developers.
Implementation of YOLO-NAS
Let’s see how YOLO NAS performs. In this notebook, we will:
- Install YOLO NAS and all its dependencies,
- Download the models and view the architectures,
- Run inference on images as well as videos.
Before we start, let us find out what kind of GPU we are running on our platform.
!nvidia-smi
As shown in the screenshot we are using the NVIDIA RTX A6000 GPU.
Install packages
Install the necessary packages using pip, YOLO-NAS model reside inside super-gradients package.
!pip install super-gradients
Import the packages
The SuperGradients model function includes a function called GET, designed to facilitate the downloading of models. Users have the flexibility to select their preferred model along with the corresponding pre-trained weights. Subsequently, load the chosen model onto the GPU for further use.
import super_gradients
yolo_nas = super_gradients.training.models.get("yolo_nas_l", pretrained_weights="coco").cuda()
#yolo_nas_m
#yolo_nas_s
View the summary
To view the summary of the model we need ‘torch’
!pip install torchinfo
With the ‘summary’ function, when any model is passed, given an input size, the function returns the model architecture. Let’s see what YOLO-NAS model architecture is.
from torchinfo import summary
summary(model=yolo_nas_l,
input_size=(16, 3, 640, 640),
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)

Model Summary and Architecture Output
In the screen shot of Model summary we can see the total number of parameters of a large model.
- Next, let us try the running inference on this large YOLO-NAS model. A convenient function named “predict,” where the image along with a confidence threshold is passed. This will provide us with the inference output.
url = "https://previews.123rf.com/images/freeograph/freeograph2011/freeograph201100150/158301822-group-of-friends-gathering-around-table-at-home.jpg"
yolo_nas_l.predict(url, conf=0.25).show()
show() will display the inference output. This is what it looks like.

YOLO-NAS output
Now to run inference on videos, we use the same function predict and pass the video path along with the output path to save the video.
input_video_path = "/notebooks/input_video/traffic.mp4"
output_video_path = "/notebooks/output_video/detections.mp4"
device=0
yolo_nas_l.to(device).predict(input_video_path).save(output_video_path)
Key Features of YOLO-NAS
- YOLO-NAS is different from other object detection models in the market by providing the optimal balance between accuracy and latency.
- Three versions of YOLO-NAS have been released by Deci i.e., small, medium, and large with and without quantization.
- YOLO-NAS, have successfully incorporated quantization-aware blocks and selective quantization to ensure optimized performance.
- Utilizing AutoNAC optimization, YOLO-NAS undergoes pre-training on well-known datasets like COCO, Objects365, and Roboflow 100. This pre-training enhances its suitability for object detection tasks in production environments, making it highly effective for downstream applications.
- Ultralytics has simplified the integration of YOLO-NAS models into Python applications through the ultralytics Python package. This package offers a user-friendly Python API, streamlining the integration process.
- Post releasing YOLO-NAS, Deci has successfully launched YOLO-NAS Pose Estimation-A new SOTA pose estimation foundation model. YOLO-NAS pose architecture is based on the YOLO-NAS architecture which includes similar backbone and neck designs.
- What distinguishes YOLO-NAS Pose is its innovative head design tailored for a multi-task objective, enabling simultaneous single-class object detection (specifically, detecting a person) and pose estimation for that individual.
Very soon we will bring a detailed article on YOLO-NAS pose so stay tuned for more articles on YOLO series!!
Conclusions
In this article we introduced YOLO-NAS, a unique SOTA model for object detection by Deci. The model’s advanced architecture incorporates state-of-the-art techniques, including attention mechanisms, quantization-aware blocks, and reparametrization during inference, enhancing its object detection capabilities. These elements collectively contribute to YOLO-NAS’s outstanding performance in detecting objects with diverse sizes and complexities, establishing a new benchmark for various industry use cases.
This groundbreaking advancement in object detection has the potential to inspire novel research and transform the field, empowering machines to intelligently and autonomously perceive and interact with the world.
Thanks for reading!
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
