AI Technical Writer

1. Introduction
YOLO continues to evolve in the world of computer vision. Real-time object detection plays a major role in powering various applications across industries. Quite a number of start-ups are coming forward with the vision of using algorithms like YOLO to power their applications—from autonomous vehicles to surveillance systems to robotics to smart retail and smart sunglasses. At the heart of these advancements, the YOLO series continues to play a major role in revolutionizing object detection.
YOLO (You Only Look Once) is a single-shot object detection model that processes an entire image in one pass, making it extremely fast and efficient. Unlike traditional object detection models that first propose regions and then classify them (like Faster R-CNN), YOLO directly predicts objects and their locations in a single neural network run. This modernized approach allows YOLO models to detect objects with speed, accuracy, and efficiency.
YOLOv12 introduces novel advancements that make it faster, more accurate, and more efficient than ever before. By using attention centric YOLO framework, optimized feature aggregation, and redefined architecture, YOLOV12 surpasses previous YOLO models and also outperforms end-to-end detectors like RT-DETR.
In this article, we will understand how YOLOv12 takes things to the next level.
With innovations like the Area Attention (A²) module, Residual Efficient Layer Aggregation Networks (R-ELAN), and FlashAttention, YOLOv12 outperforms its predecessors while maintaining low latency. Notably, YOLOv12-N achieves 40.6% mAP with just 1.64 ms latency on a T4 GPU, surpassing YOLOv10-N and YOLOv11-N with a comparable speed. It also beats end-to-end real-time detectors like RT-DETR and RT-DETRv2, running 42% faster while using fewer parameters and computations.
Let’s understand YOLOv12 in detail and learn how to use It with DigitalOcean’s GPU Droplet powered by H100.
2. Prerequisites
- Object Detection Basics—Understanding concepts such as bounding boxes, Intersection over Union (IoU), and anchor boxes will be beneficial.
- Deep Learning Fundamentals – Neural networks, convolutional layers, and backpropagation.
- YOLO Architecture – How YOLO works, its evolution from YOLOv1 to YOLOv11, and key improvements.
- Evaluation Metrics – A good understanding of mAP, F1-score, Precision-Recall, FLOPs, and latency considerations.
- Python & Deep Learning Frameworks – Familiarity with concepts of PyTorch or TensorFlow for implementing and training models.
3. Key Metrics to understand object detection better
- Mean Average Precision (mAP): mAP is a measures which tells us how well a model detects objects by computing the area under the Precision-Recall (PR) curve.
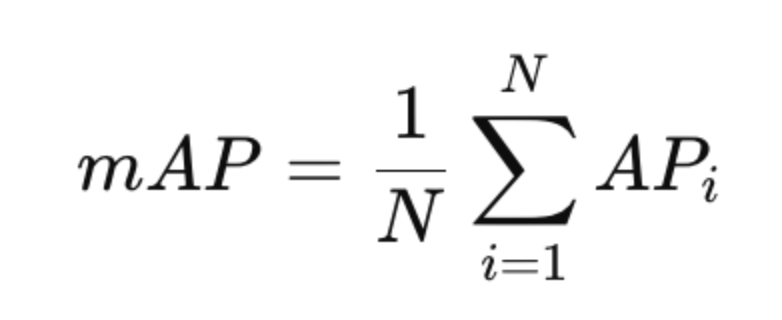
where AP (Average Precision) is computed for each class.
- F1-Score: F1-Score is the harmonic mean of precision and recall, balancing false positives and false negatives.
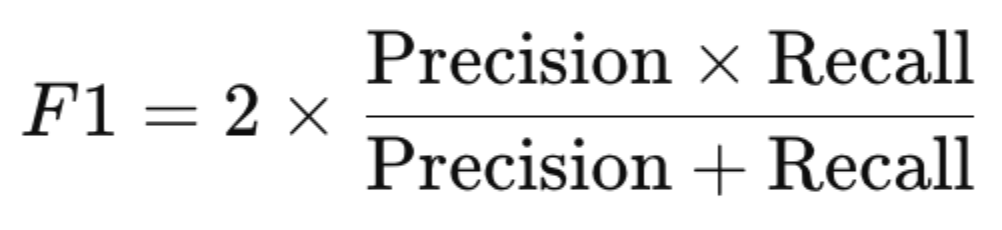
A higher F1-score indicates better performance.
- Intersection over Union (IoU): IoU measures the overlap between the predicted bounding box and the ground truth.

A higher IoU means better localization.
- Precision: A ratio of correctly predicted positive classes to total predicted positives.

- Recall: A ratio of correctly predicted positives to total actual positives.

Frames Per Second (FPS): Measures the inference speed (how fast the model processes images).
Higher FPS = Faster model.
- Floating Point Operations Per Second (FLOPs): Number of floating-point operations required for inference.
Lower FLOPs = Faster model, but might reduce accuracy.
- Latency: Time taken for a model to process an input image and return an output.
Lower latency = Faster inference.
4. What’s New in YOLOv12?
YOLOv12 introduces three major advancements to increase speed, accuracy, and efficiency while keeping computational costs low. These improvements focus on better attention mechanisms, optimized feature aggregation, and architectural refinements.
1. Faster and Smarter Attention with A² (Area Attention Module)
What is Attention?
- In deep learning, attention mechanisms help models focus on the most important parts of an image.
- Traditional attention methods (like Transformer-based models) often require complex calculations, making them slow and computationally expensive, especially for large images.
What Does A² (Area Attention) Do?
- Maintains a Large Receptive Field—This ensures that the model can “see” a wider area in the image while focusing on key objects.
- **Reduces Computational Complexity—**Unlike traditional attention mechanisms, A² simplifies the number of operations needed, increasing processing speed without compromising accuracy.
- Enhances Speed – By optimizing how the model processes attention, A² allows YOLOv12 to detect objects faster while using fewer resources.
Why is This Important?
- Faster attention means YOLOv12 can process images in real time, making it ideal for applications like autonomous vehicles, drones, and surveillance systems that require instant decisions.
2. Improved Optimization with R-ELAN (Residual Efficient Layer Aggregation Networks)
What is ELAN?
- ELAN (Efficient Layer Aggregation Network) was used in previous YOLO versions to improve how features are combined at different stages of the model.
- However, large models struggle with optimization, meaning they can be harder to train and may not learn efficiently.
What Does R-ELAN Improve?
-
Introduces a Block-Level Residual Design
- Residual connections allow the model to reuse learned information, preventing the loss of important details during training.
- Helps in training deeper networks without making them unstable.
-
Redesigned Feature Aggregation
- Instead of naively stacking layers, R-ELAN combines features more effectively, allowing the model to detect objects with better accuracy and less redundancy.
Why is R-ELAN Important?
- Improves the ability to train large models efficiently.
- Helps maintain accuracy while keeping the model lightweight and fast.
- Makes YOLOv12 more scalable, meaning it works well across different computing environments, from edge devices to cloud GPUs.
3. Architectural Improvements Beyond Standard Attention
To further optimize YOLOv12’s speed and efficiency, the architecture has been refined in several key ways:
1. Using FlashAttention for Memory Efficiency
- Problem: Traditional attention mechanisms suffer from memory bottlenecks, meaning they slow down when dealing with large images.
- Solution: YOLOv12 integrates FlashAttention, a technique that optimizes how memory is accessed, making it faster and more efficient.
2. Removing Positional Encoding for Simplicity
- Problem: Many Transformer-based models use positional encoding to keep track of where objects are in an image. However, this adds extra complexity.
- Solution: YOLOv12 removes positional encoding, simplifying the architecture without losing accuracy.
3. Adjusting MLP Ratio to Balance Attention & Feedforward Network
- Problem: In Transformer architectures, Multi-Layer Perceptrons (MLPs) process information after attention layers.
- Solution: YOLOv12 reduces the MLP ratio from 4 to 1.2, ensuring a better balance between computation spent on attention and feedforward operations, leading to faster inference.
4. Reducing the Depth of Stacked Blocks
- Problem: Deep models can become hard to train and computationally expensive.
- Solution: YOLOv12 reduces the number of layers in its network while keeping high performance, leading to faster optimization and lower latency.
5. Maximizing the Use of Convolution Operations
- Problem: Pure attention-based architectures rely heavily on self-attention, which can be slow.
- Solution: YOLOv12 incorporates more convolution layers, which are:
- Faster and more hardware-efficient
- Better at extracting local features
- Well-optimized for modern GPUs
Based on the designs above, YOLOv12 comes with five models again optimized for modern GPUs: YOLOv12-N, S, M, L, and X.
5. YOLOv12 vs Previous Versions (YOLOv11, YOLOv8, etc.)
The YOLO series introduces new advancements and innovations with each YOLO version. The early versions (YOLO 1-3) laid the framework and architectural foundations. In contrast, the later version (YOLO 7 to YOLO11) shifted towards better gradient flow using ELAN along with various techniques to improve the model’s efficiency.
| YOLO Version | Key Innovations | Improvements |
|---|---|---|
| YOLO (1-3) | Established the YOLO framework | Introduced real-time object detection with a single-stage pipeline |
| YOLOv4 | CSPNet, data augmentation, multiple feature scales | Improved model efficiency and accuracy |
| YOLOv5 | CSPNet enhancements, streamlined architecture | Faster inference, better deployment adaptability |
| YOLOv6 | BiC, SimCSPSPPF, anchor-aided training | Optimized backbone and neck for improved performance |
| YOLOv7 | EELAN (Efficient Layer Aggregation Networks), bag-of-freebies | Enhanced gradient flow and overall efficiency |
| YOLOv8 | C2f block for feature extraction | Improved accuracy and computational efficiency |
| YOLOv9 | GELAN for architecture optimization, PGI for better training | Reduced training overhead and model refinement |
| YOLOv10 | NMS-free training with dual assignments | Increased efficiency in object detection |
| YOLOv11 | C3K2 module, lightweight depthwise separable convolution | Lower latency and improved accuracy |
| RT-DETR | Efficient encoder, uncertainty-minimal query selection | Real-time end-to-end object detection |
| RT-DETRv2 | Additional bag-of-freebies | Further optimization of end-to-end detection models |
| YOLOv12 | Attention-centered architecture | Utilizes attention mechanisms for improved detection |
This table highlights how each YOLO iteration introduced advancements in model architecture, efficiency, and accuracy.
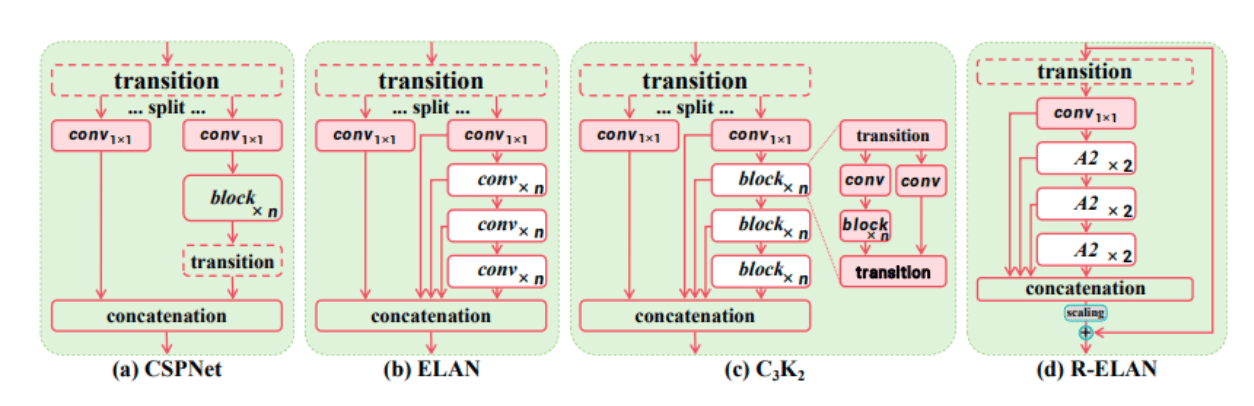
As depicted in the image, this progression from CSPNet → ELAN → C3K2 → R-ELAN represents increasing architectural complexity and is thus aimed to improve the gradient flow, feature reuse, and computational efficiency with each iteration.
6. YOLOv12 Using DigitalOcean’s GPU Droplet for Inference
With the increasing demand for high-performance object detection models, deploying YOLOv12 efficiently requires powerful hardware capable of handling real-time inference. DigitalOcean’s GPU Droplets can be a great solution for running YOLOv12 inference to deliver speed and optimal accuracy using high-performance NVIDIA GPUs.
1. Create a DigitalOcean GPU Droplet
To run YOLOv12, create a GPU Droplet with the following specifications:
2. Install Required Dependencies
Once the droplet is created, install the necessary libraries:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118
pip3 install ultralytics
Install PyTorch and Ultralytics YOLO, which supports YOLOv12 models.
3. Download the YOLOv12 Model
Use the following command to download a pre-trained YOLOv12 model:
git clone https://github.com/ultralytics/yolov12
cd yolov12
wget <model-url> -O yolov12.pt # Replace with actual model URL
4. Run Inference on GPU
To perform object detection on images or videos using DigitalOcean’s GPU, run the code provided below:
from ultralytics import YOLO
# Load a COCO-pretrained YOLO12n model
model = YOLO("yolo12n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO12n model on the 'bus.jpg' image
results = model("path/to/image.jpg", device="cuda")
# Show detection results
results[0].plot()
results[0].show()

7. Benchmarking and Performance Evaluation
YOLOv12 has been validated on the MSCOCO 2017 dataset, which includes five models: YOLOv12-N, S, M, L, and X. All models were trained for 600 epochs using the SGD optimizer with a 0.01 learning rate, similar to YOLOv11. Latencies are tested on a T4 GPU with TensorRT FP16. YOLOv11 is the baseline, maintaining its scaling strategy and C3K2 blocks without additional modifications.
Here’s a breakdown of how each version performs:
YOLOv12-N (smallest version) is more accurate than YOLOv6, YOLOv8, YOLOv10, and YOLOv11 by up to 3.6% in mean Average Precision (mAP). Despite this, it remains efficient, processing each image in just 1.64 milliseconds while using the same or fewer resources.
YOLOv12-S (small version) has 21.4G FLOPs (a measure of computing power) and 9.3 million parameters. It achieves 48.0 mAP while taking 2.61 milliseconds per image, making it faster and more efficient than YOLOv8-S, YOLOv9-S, YOLOv10-S, and YOLOv11-S. It also performs better than RT-DETR models, which are end-to-end detectors while using less computing power.
YOLOv12-M (medium version), with 67.5G FLOPs and 20.2 million parameters, reaches 52.5 mAP and processes each image in 4.86 milliseconds. It outperforms GoldYOLO-M, YOLOv8-M, YOLOv9-M, YOLOv10, YOLOv11, and RT-DETR models, making it a strong choice for medium-sized models.
YOLOv12-L (large version) is more efficient than YOLOv10-L, using 31.4G fewer FLOPs while achieving higher accuracy. It also outperforms YOLOv11 by 0.4% mAP while maintaining similar efficiency. Compared to RT-DETR models, it is 34.6% more efficient in computations and uses 37.1% fewer parameters, making it faster and lighter.
YOLOv12-X (largest version) achieves even better results, improving accuracy over YOLOv10-X and YOLOv11-X while maintaining similar speed and efficiency. It is also significantly faster and more efficient than RT-DETR models, using 23.4% less computing power and 22.2% fewer parameters.
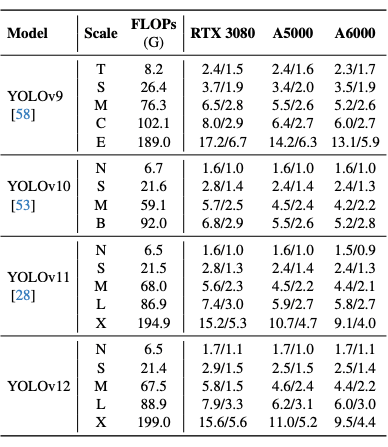
This table compares the performance of YOLOv12 with various models in the YOLO series (from YOLOv9 to YOLOv12). The table shows the performance evaluation on different GPUs across various model scales, from Tiny/Nano to Extra Large. The comparison is based on FLOPs (computational complexity) and inference speed, measured in frames per second (FPS) on three NVIDIA GPUs (RTX 3080, A5000, A6000).
Smaller models (Tiny, Nano, Small) tend to be faster but less accurate, while larger models (Large, Extra Large) have higher FLOPs and slower speeds. Inference speed is presented with two values, which likely correspond to different batch sizes. Overall, the performance across the different GPUs is quite similar, though the A6000 and A5000 GPUs exhibit slightly higher efficiency in some cases.
8. FAQs
What is YOLOv12?
YOLOv12 is the latest iteration of the YOLO object detection model. It introduces attention-based mechanisms to improve detection accuracy while maintaining real-time performance. Key innovations include Area Attention, Residual Efficient Layer Aggregation Networks (R-ELAN), and optimized training strategies. These advancements make YOLOv12 one of the most efficient and accurate object detection models to date.
How does YOLOv12 compare to YOLOv11?
YOLOv12 improves upon YOLOv11 in several ways:
- Better Accuracy: The introduction of Area Attention helps detect small and occluded objects more effectively.
- Improved Feature Aggregation: R-ELAN ensures richer feature extraction, leading to enhanced object recognition.
- Optimized Speed: YOLOv12 maintains real-time performance with optimized attention mechanisms.
- Higher Efficiency: The model is designed to work efficiently on modern GPUs, leveraging FlashAttention for faster inference.
Overall, YOLOv12 provides a better latency-accuracy trade-off than YOLOv11.
What are the real-world applications of YOLOv12?
YOLOv12’s ability to process images and videos in real-time makes it ideal for various applications, including:
- Autonomous Vehicles: Object detection for self-driving cars.
- Surveillance & Security: Real-time monitoring in public spaces.
- Healthcare: Detecting anomalies in medical imaging.
- Retail & Manufacturing: Automated product inspection and tracking.
- Augmented Reality (AR) & Robotics: Enhancing real-time object detection in AI-powered devices.
How can I train YOLOv12 on my dataset?
To train YOLOv12 on a custom dataset:
Prepare Your Data: Organize images and annotations in YOLO format. Install Dependencies
pip install ultralytics
Train the Model
from ultralytics import YOLO
model = YOLO("yolov12.pt")
model.train(
data=data.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6
device="0,1,2,3",
)
Evaluate Performance: Use model.val() to check mAP scores.
What are the best GPUs for YOLOv12?
YOLOv12 requires GPUs that support FlashAttention, including:
- NVIDIA H100, A100 (Best for large-scale inference & training)
- RTX 4090, 3090, A6000 (Great for training and real-time inference)
- T4, A40, A30 (Efficient for cloud-based deployment)
For optimal performance, H100 on platforms like DigitalOcean GPU Droplets is recommended.
9. Concluding thoughts
YOLOv12 successfully brings attention-based mechanisms into the YOLO framework while maintaining real-time performance. Traditionally, attention-based models have been considered inefficient for fast inference, but YOLOv12 successfully optimizes them using area attention and residual efficient layer aggregation networks (R-ELAN).
These enhancements improve feature extraction, making object detection more accurate while maintaining high-speed performance. By refining attention mechanisms to align with YOLO’s real-time constraints, YOLOv12 achieves state-of-the-art accuracy and efficiency. This advancement challenges the dominance of purely CNN-based YOLO models and paves the way for smarter, more efficient object detection systems.
Limitations
Despite its improvements, YOLOv12 has a few limitations:
- Hardware Dependency: It requires FlashAttention, which only works on newer GPUs (Turing, Ampere, Ada Lovelace, or Hopper), making it less accessible for users with older hardware.
- High Training Cost: Training YOLOv12 demands significant computational resources, as it relies on multiple high-end GPUs (e.g., 8× NVIDIA A6000).
- Increased Complexity: While the model improves efficiency, the added attention mechanisms introduce more complexity compared to traditional CNN-based YOLO models.
- Hyperparameter Sensitivity: The model’s performance depends on careful tuning of hyperparameters, requiring expertise to achieve the best results.
Despite its limitations, YOLOv12 marks a significant advancement in the field of object detection. It demonstrates that attention-based architectures can improve real-time detection without compromising speed. This model sets a new standard for balancing accuracy, efficiency, and scalability in this area.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
