AI Technical Writer

Introduction
YOLOv8, developed by Ultralytics in 2023, has emerged as one of the unique object detection algorithms in the YOLO series and comes with significant architectural and performance enhancements over its predecessors, like YOLOv5. These improvements include a CSPNet backbone for better feature extraction, an FPN+PAN neck for improved multi-scale object detection, and a shift to an anchor-free approach. These changes significantly improve the model’s accuracy, efficiency, and usability for real-time object detection.
Using a GPU with YOLOv8 can significantly boost performance for object detection tasks, providing faster training and inference. This guide will walk you through setting up YOLOv8 for GPU usage, including configuration, troubleshooting, and optimization tips.
YOLOv8
YOLOv8 builds upon its predecessors with advanced neural network design and training techniques to enhance performance in object detection. It unifies object localization and classification in a single, efficient framework, balancing speed and accuracy. The architecture comprises three key components:
- Backbone: A highly optimized CNN backbone, potentially based on CSPDarknet, extracts multi-scale features using efficient layers like depthwise separable convolutions, ensuring high performance with minimal computational overhead.
- Neck: An enhanced Path Aggregation Network (PANet) refines and integrates multi-scale features to better detect objects across varying sizes. It is optimized for efficiency and memory usage.
- Head: The anchor-free head predicts bounding boxes, confidence scores, and class labels, simplifying predictions and improving adaptability to diverse object shapes and scales.
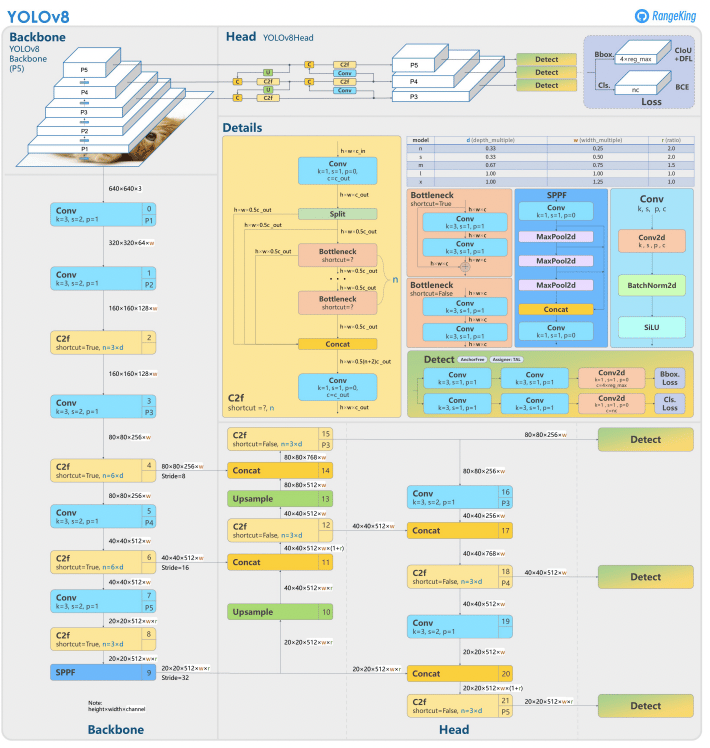
These innovations make YOLOv8 faster, more accurate, and versatile for modern object detection tasks. Furthermore, YOLOv8 introduces an anchor-free approach to bounding box prediction, moving away from the anchor-based methods of earlier versions.
Why Use a GPU with YOLOv8?
YOLOv8 (You Only Look Once, Version 8) is a powerful object detection framework. While it runs on CPUs, utilizing a GPU offers a few key benefits, such as:
- Speed: GPUs handle parallel computations more efficiently, reducing training and inference times.
- Scalability: Larger datasets and models are manageable with GPUs.
- Enhanced Performance: Real-time object detection becomes feasible, enabling applications such as autonomous vehicles, surveillance, and live video processing.

GPUs are the clear choice for achieving faster results and handling more complex tasks with YOLOv8.
CPU vs.GPU
While working with YOLOv8 or any object detection model, the choice between CPU and GPU can significantly impact the model’s performance for both training and inference. CPUs, as we know, are great for general purposes and can efficiently handle smaller tasks. However, CPUs fail when the task becomes computationally expensive. Tasks like object detection require speed and parallel computing, and GPUs are designed to handle high-performance parallel processing tasks. Hence, they are ideal for running deep learning models like YOLO. For instance, training and inference on a GPU can be 10–50 times faster than on a CPU, depending on the hardware and model size.
| Aspect | CPU | GPU |
|---|---|---|
| Inference Time (per image) | ~500 ms | ~15 ms |
| Training Speed (epochs/hr) | ~2 epochs/hour | ~30 epochs/hour |
| Batch Size Capability | Small (2-4 images) | Large (16-32 images) |
| Real-Time Performance | No | Yes |
| Parallel Processing | Limited | Excellent (thousands of cores) |
| Energy Efficiency | Lower for large tasks | Higher for parallel workloads |
| Cost Efficiency | Suitable for small tasks | Ideal for any deep learning tasks |
The difference becomes even more pronounced during training, where GPUs dramatically shorten epochs compared to CPUs. This speed boost allows GPUs to process larger datasets and perform real-time object detection more efficiently.
Prerequisites for Using YOLOv8 with GPU
Before configuring YOLOv8 for GPU, ensure you meet the following requirements:
1. Hardware Requirements
- NVIDIA GPU: YOLOv8 relies on CUDA for GPU acceleration, so you’ll need an NVIDIA GPU with a CUDA Compute Capability of 6.0 or higher.
- Memory: At least 8GB of GPU memory is recommended for moderate datasets. For larger datasets, 16GB or more is preferred.
2. Software Requirements
- Python: Version 3.8 or later.
- PyTorch: Installed with GPU support (via CUDA). Preferably NVIDIA GPU.
- CUDA Toolkit and cuDNN: Ensure these are compatible with your PyTorch version.
- YOLOv8: Installable from the Ultralytics repository.
3. Driver Requirements
- Download and install the latest NVIDIA drivers from the NVIDIA website.
- Check your GPU availability using
nvidia-smiafter driver installation.
Step-by-Step Guide to Configure YOLOv8 for GPU
1. Install NVIDIA Drivers
To install NVIDIA drivers:
- Identify your GPU using the below code:
nvidia-smi
- Visit the NVIDIA Drivers Download page and download the appropriate driver.
- Follow the installation instructions for your operating system.
- Restart your computer to apply changes.
- Verify installation by running:
nvidia-smi
- This command displays GPU information and confirms driver functionality.
2. Install CUDA Toolkit and cuDNN
To use YOLOv8, we need to select the appropriate PyTorch version, which in turn requires CUDA version.
Steps to Install CUDA Toolkit
- Download the appropriate version of the CUDA Toolkit from the NVIDIA Developer site.
- Install CUDA Toolkit and set environment variables (e.g.,
PATH,LD_LIBRARY_PATH). - Verify the installation by running:
nvcc --version
Ensuring you have the latest version of CUDA will allow PyTorch to utilize GPU effectively
Steps to Install cuDNN
- Download cuDNN from the NVIDIA Developer site.
- Extract the contents and copy them into the corresponding CUDA directories (e.g.,
bin,include,lib). - Ensure that the cuDNN version matches your CUDA installation.
3. Install PyTorch with GPU Support
To install PyTorch with GPU support, visit the PyTorch Get Started page and select the appropriate installation command. For example:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
4. Install and Run YOLOv8
Install YOLOv8 by following these steps:
- Install Ultralytics to work with yolov8 and import the necessary libraries
pip install ultralytics
- Example for Python Script:
from Ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
model = YOLO("yolov8n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device = ‘cuda’)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
results = model("path/to/image.jpg")
- Example for Command Line:
# use the CLI commands to directly run the model:
from Ultralytics import YOLO
# Load a COCO-pretrained YOLOv8n model
model = YOLO("yolov8n.pt")
# Display model information (optional)
model.info()
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLOv8n model on the 'bus.jpg' image
results = model("path/to/image.jpg")
5. Verify GPU Configuration in YOLOv8
Use the following Python command to check if your GPU is detected and CUDA is enabled:
import torch
# Check if GPU is available
print("CUDA Available:", torch.cuda.is_available())
# Get GPU details
if torch.cuda.is_available():
print("GPU Name:", torch.cuda.get_device_name(0))
6. Train or Infer with GPU
Specify the device as cuda in your training or inference commands:
Command-Line Example
yolo task=detect mode=train data=coco.yaml model=yolov8n.pt device=0 epochs = 128 plots = True
Validate the custom model
yolo task=detect mode=val model={HOME}/runs/detect/train/weights/best.pt data={dataset.location}/data.yaml
Python Script Example
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Train the model on GPU
model.train(data='coco.yaml', epochs=50, device='cuda')
# Perform inference on GPU
results = model.predict(source='input.jpg', device='cuda')
Why DigitalOcean GPU Droplets?
DigitalOcean GPU droplets are designed to handle high-performance AI and machine-learning tasks. H100s power these GPU Droplets to deliver exceptional speed and parallel processing capabilities, making them ideal for training and running YOLOv8 models efficiently. To add more, these droplets are pre-installed with the latest version of CUDA, ensuring you can start leveraging GPU acceleration without spending time on manual configurations. This streamlined environment allows you to focus entirely on optimizing your YOLOv8 models and scaling your projects effortlessly.
Troubleshooting Common Issues
1. YOLOv8 Not Using GPU
- Verify GPU availability using
torch.cuda.is_available()
- Check CUDA and PyTorch compatibility.
- Ensure you specify
device=0ordevice='cuda'in commands or scripts. - Update NVIDIA drivers and reinstall CUDA Toolkit if necessary.
2. CUDA Errors
- Ensure that the CUDA Toolkit version matches the PyTorch requirements.
- Verify cuDNN installation by running diagnostic scripts.
- Check the environment variables for CUDA (
PATHandLD_LIBRARY_PATH).
3. Slow Performance
- Enable mixed precision training to optimize memory usage and speed:
model.train(data='coco.yaml', epochs=50, device='cuda', amp=True)
- Reduce batch size if memory usage is too high.
- Ensure you have an optimized system for running parallel processing, and consider using batch processing in your detection script to enhance performance.
from Ultralytics import YOLO
# Load the models
vehicle_model = YOLO('yolov8l.pt')
license_model = YOLO('Registration.pt')
# Process each stream, example for one stream
results = vehicle_model(source='stream1.mp4', batch=4) # Modify as needed for parallel processing
FAQs
How do I enable GPU for YOLOv8?
Specify device='cuda' or device=0 (if using the first GPU) in your commands or scripts when loading the model. This will enable YOLOv8 to utilize the GPU for faster computation during inference and training. Ensure that your GPU is properly set up and detected.
model = YOLO("yolov8n.pt")
model.to('cuda')
Why is YOLOv8 not using my GPU?
YOLOv8 might not be using the GPU if there are issues with the hardware, drivers or setup. To start with, verify CUDA installation and compatibility with PyTorch. Update drivers if necessary. Ensure that your CUDA and CuDNN are Compatible with your PyTorch installation. Install torchvision and check the configuration that is being installed and used.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118`
import torch print(torch.cuda.get_device_name())
Additionally, if PyTorch is not installed with GPU support (e.g., a CPU-only version), or the device parameter in your YOLOv8 commands may not be explicitly set to cuda. Running YOLOv8 on a system without a CUDA-compatible GPU or insufficient VRAM can also cause it to default to CPU.
To resolve this, ensure your GPU is CUDA-compatible, verify the installation of all required dependencies, check that torch.cuda.is_available() returns True, and explicitly specify the device='cuda' parameter in your YOLOv8 scripts or commands.
What are the hardware requirements for YOLOv8 on GPU?
To effectively install and run YOLOVv8 on a GPU, Python 3.7 or higher is recommended, and a CUDA-compatible GPU is required to use GPU acceleration.
A modern NVIDIA GPU with at least 8GB of memory is recommended. For large datasets, more memory is beneficial. For optimal performance, it is recommended to use Python 3.8 or newer, PyTorch 1.10 or higher, and an NVIDIA GPU compatible with CUDA 11.2+. The GPU should ideally have at least 8GB of VRAM to handle moderate datasets efficiently, although more VRAM is beneficial for larger datasets and complex models. Additionally, your system should have at least 8GB of RAM and 50GB of free disk space to store datasets and facilitate model training. Ensuring these hardware and software configurations will help you achieve faster training and inference with YOLOv8, especially for computationally intensive tasks.
Please Note: AMD GPUs may not support CUDA, so choosing an NVIDIA GPU for YOLOv8 compatibility is essential.
Can YOLOv8 run on multiple GPUs?
To train YOLOv8 using multiple GPUs, you can use PyTorch’s DataParallel or specify multiple devices directly (e.g., cuda:0,1). For distributed training, YOLOv8 employs PyTorch’s Multi-GPU DistributedDataParallel (DDP) by default. Ensure that your system has multiple GPUs available and specify the GPUs you want to use in the training script or command line. For instance, set --device 0,1,2,3 in the CLI or device=[0,1,2,3] in Python to utilize GPUs 0, 1, 2, and 3. YOLOv8 automatically handles parallel training across the specified GPUs without requiring an explicit data_parallel argument. While all GPUs are utilized during training, the validation phase typically runs on a single GPU by default, as it is less resource-intensive than training.
How do I optimize YOLOv8 for inference on GPU?
Enable mixed precision and adjust batch sizes to balance memory and speed. Depending on your dataset, training YOLOv8 requires quite a bit of computation power to run efficiently. Use a smaller or quantized model variant (e.g., YOLOv8n or INT8 quantized versions) to reduce memory usage and inference time. In your inference script, explicitly set the device parameter to cuda for GPU execution. Use techniques like batch inference to process multiple images simultaneously and maximize GPU utilization. If applicable, utilize TensorRT to optimize the model further for faster GPU inference. Regularly monitor GPU memory and performance to ensure efficient resource usage.
The below code snippet will allow you to process images in parallel within the defined batch size.
from Ultralytics import YOLO
model = YOLO('yolov8n.pt', device='cpu', batch=4) # specify the batch size as needed
# pass the argument ‘images’, which is the list of preprocessed images
results = model.predict(images) # 'images' should have the shape (N, 3, H, W)
If using the CLI, specify the batch size with -b or --batch-size. With Python, ensure the batch argument is correctly set when initializing your model or calling the prediction method.
How do I resolve CUDA Out-of-memory issues?
To resolve CUDA out-of-memory errors, reduce the validation batch size in your YOLOv8 configuration file, as smaller batches require less GPU memory. Additionally, if you have access to multiple GPUs, consider distributing the validation workload across them using PyTorch’s DistributedDataParallel or similar functionality, though this requires advanced knowledge of PyTorch. You can also try clearing cached memory using torch.cuda.empty_cache() in your script and ensure that no unnecessary processes run on your GPU. Upgrading to a GPU with more VRAM or optimizing your model and dataset for memory efficiency are further steps to mitigate such issues.
Conclusion
Configuring YOLOv8 to utilize a GPU is a straightforward process that can significantly enhance performance. By following this detailed guide, you can accelerate training and inference for your object detection tasks. Optimize your setup, troubleshoot common issues, and unlock the full potential of YOLOv8 with GPU acceleration.
References
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
