Before cloud GPUs became prevalent, on-premise GPUs were widely used. These GPUs, developed in the 1970s, were initially designed to handle complex graphics rendering, primarily in video game development, specialized visual applications, and data science. As industries evolved, it became clear that the parallel processing power of GPUs could be applied to more than just visuals. Sectors like healthcare, finance, and gaming, which deal with increasingly large and complex data processes, began to use the power of physical GPUs to overcome performance limitations and speed up processing capabilities.
Though physical GPUs were deployed to run machine learning algorithms, train deep learning models for natural language processing (NLP) in AI language translation, and handle applications requiring massive parallelism, they presented scalability and resource management limitations. This led to the emergence of cloud GPUs, which offer the same processing power as physical GPUs but with the cloud’s flexibility, scalability, and cost-efficiency. With Cloud GPUs, you can access powerful GPU resources on demand, eliminating the need for heavy upfront investments in physical hardware and enabling rapid scaling to meet the demands of large-scale tasks.
Read on to learn about cloud GPU, the difference between physical GPU and cloud GPU, the benefits of cloud GPU, and factors to consider when choosing the cloud GPU that best suits your project.
Summary
-
A cloud GPU is a high-performance processor hosted in the cloud, designed to handle complex graphical and parallel processing tasks like rendering, AI, and machine learning workloads.
-
When selecting a cloud GPU, consider factors like performance requirements, scalability for growing data volumes, cost, integration with existing infrastructure, and network data transfer speeds to ensure smooth processing and avoid vendor lock-in.
-
DigitalOcean GPU Droplets provide on-demand access to NVIDIA H100 GPUs with flexible configurations (single-GPU or 8-GPU setups), pre-installed Python and deep learning packages, and high-performance local storage, allowing developers to scale AI/ML projects quickly.
💡 Lepton AI, Supermaven, Nomic AI, and Moonvalley leverage DigitalOcean GPU Droplets to improve AI inference and training, refine code completion, derive insights from extensive unstructured datasets, and create high-definition cinematic media, delivering scalable and accessible AI-driven solutions.
What is a cloud GPU?
A cloud GPU is a high-performance processor hosted in the cloud, designed to handle complex graphical and parallel processing tasks, such as rendering and AI and ML workloads. Cloud GPUs are accessed remotely through cloud service providers, allowing users to deploy the immense processing power without needing physical hardware.
How does a cloud GPU work?
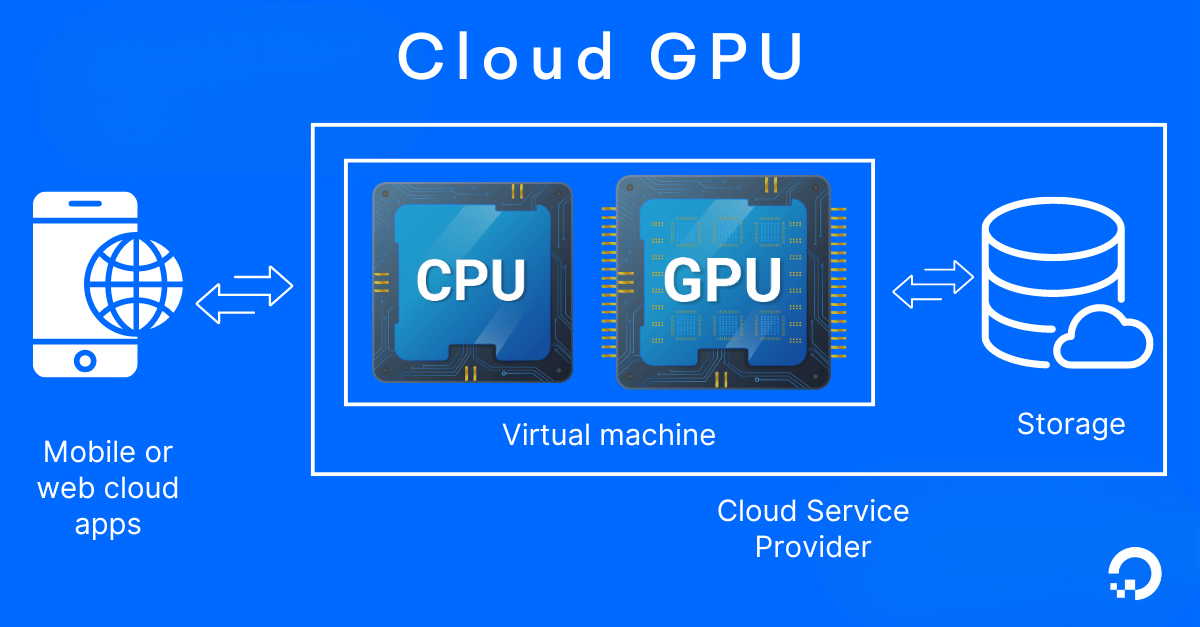
This image provides a simplified representation of Cloud GPU architecture for general understanding. The specific configurations, resource allocation, and data flow may vary based on the cloud service provider and the particular use case. GPUs are optional add-ons for specialized workloads (e.g., AI/ML, rendering) and are not part of every VM.
-
Request the GPU: Users select and request GPU resources from a cloud provider through a cloud platform interface or API.
-
Allocate the GPU: The cloud provider allocates virtualized GPU resources according to the users’ request— such as dedicated GPUs (exclusive to one user), shared GPUs (shared across multiple users), or GPU instances (virtual machines with attached GPU acceleration) from their data center infrastructure to the user’s instance or environment.
-
Setup instance: A virtual machine (VM) or container is spun up with the appropriate GPU drivers and software tools configured for the user’s specific workload.
-
Upload data: The user uploads datasets or applications to the cloud using cloud storage services, APIs, secure file transfers, or data ingestion tools, which are processed using the allocated cloud GPU.
-
Execute parallel processing: The cloud GPU performs computations in parallel by dividing tasks into smaller, independent operations that can be executed simultaneously across multiple cores. Each core handles a portion of the workload, allowing faster data processing and improved efficiency.
-
Receive output: Once the computations are complete, the results are returned to the user through the cloud platform’s interface or stored in cloud storage for later access.
-
Resource termination: After processing, users can terminate the instance, freeing up the shared cloud GPU resources for other users. However, for dedicated instances, the GPU remains exclusive until fully terminated.
Difference between a physical GPU and a cloud GPU
Physical and cloud GPUs share the same core functionality— both provide the high computational power needed for processing complex calculations. The physical GPUs are manufactured by companies like NVIDIA, AMD, and Intel, which design and produce hardware for direct installation in personal and enterprise systems.
Major cloud service providers like Amazon Web Services (AWS), Google Cloud, Microsoft Azure, and DigitalOcean offer cloud GPUs, which allow you to rent GPUs on demand for AI/ML tasks. However, they differ in the following factors:
| Parameter | Physical GPU | Cloud GPU |
|---|---|---|
| Infrastructure | Requires physical installation and management of GPU hardware | Hosted and managed by cloud service providers, no need for physical hardware setup |
| Scalability | Limited scalability; requires purchasing and upgrading physical hardware | Easily scalable based on demand. |
| Cost | High initial investment in hardware, plus maintenance costs | Flexible, with hourly or monthly billing, no upfront hardware costs. Pay-as-you-go pricing based on usage |
| Performance control | Complete control over performance tuning and system optimization | Optimized based on the provider’s infrastructure, with some limitations on customization |
| Upgrades | Requires manual upgrades or replacement of physical hardware | Automatic hardware updates provided by the cloud provider |
| Maintenance | User is responsible for hardware and cooling system maintenance | No maintenance is required from the user, managed by the provider |
| Accessibility | Limited to local usage (unless accessed via remote desktop software or virtual private networks) | Accessible from anywhere with the internet, multiple users can share resources |
| Setup time | Time-consuming setup involving physical installation and configuration | Quick setup; no need to install physical components |
| Data privacy and security | Offers full control over data storage and security. Additional measures are required to ensure physical security and encryption | Relies on cloud provider’s security protocols; ensure compliance with data regulations and encryption |
Benefits of cloud GPU
Cloud GPUs don’t eliminate the need for traditional CPU computing power—they amplify computational abilities by quickly processing vast amounts of data. Apart from executing complex calculations, you can benefit from cloud GPUs over purchasing an on-premise GPU for the following reasons:
1. Cost-effectiveness
Cloud GPUs offer cost savings by eliminating the need for upfront hardware purchases. You pay only for the resources you use, making it a flexible and budget-friendly option. For instance, if you’re running GPU-intensive tasks like rendering high-quality graphics for videos or performing scientific simulations for just a few hours, you can rent the GPU resources and stop paying as soon as the task is complete*. This pay-as-you-go model helps you avoid the costs of buying, maintaining, and upgrading expensive physical GPUs. The flexibility to scale resources up or down based on demand ensures you don’t over-provision, reducing the total cost of ownership (TCO).
*Costs may vary based on the cloud provider’s pricing model and compute node. Additional charges like data transfer fees, storage, and network usage might apply. Be sure to check for any long-term commitments or minimum usage requirements from the provider.
2. Reduced maintenance
You don’t need to worry about hardware upkeep, as the cloud provider handles all aspects of maintenance, including software updates and performance optimizations. They monitor and manage the infrastructure, ensuring your GPUs are always available and running smoothly. For example, if you’re training a convolutional neural network (CNN) for image recognition and the cloud GPU you’re using experiences a hardware failure, such as overheating or a memory malfunction, the cloud provider automatically reallocates your workload to another available GPU in the data center.
3. Fast processing
With cloud GPUs, you can break down data-intensive tasks into smaller subtasks that can be processed concurrently by different cores. Their efficient memory management minimizes performance constraints, while optimized algorithms use parallel capabilities for faster results. For example, if you’re building simulations for financial modeling, a cloud GPU can quickly analyze vast datasets to forecast market trends, reducing the time required to generate insights.
How do you choose your cloud GPU?
Choosing the right cloud GPU can feel challenging, especially with many available options. You need to understand the various misconceptions surrounding GPUs and navigate complex specifications and performance metrics, which can vary between providers. You also need to ensure the GPU capabilities match your project requirements while staying within budget. If you over-provision or under-provision resources, it could affect both performance and costs.
That’s why it’s necessary to thoroughly assess your needs before deciding so that you can find the best solution:
Performance requirements
Understanding the different GPU models, architectures, and performance capabilities will help you pick the perfect GPU that aligns with your specific project needs, optimizing efficiency and driving desired outcomes.
Start by looking for the GPU’s processing power, which includes clock speed and the number of CUDA cores or Tensor cores, as these elements directly affect overall computational speed. Check the VRAM capacity, as higher VRAM might efficiently handle large datasets and complex models in memory-intensive tasks such as 3D rendering, video editing, and high-resolution image processing. Evaluate the GPU’s architecture and consider newer architectures like NVIDIA’s Hopper, found in NVIDIA’s H100s, which might provide better performance and efficiency than its predecessors.
Unlock the power of GPU performance optimization for deep learning with our comprehensive guide. Discover key insights on NVIDIA GPU architectures, programming languages like CUDA and Triton, and essential performance monitoring tools. Whether you’re a seasoned developer or just starting out, this article will equip you with the knowledge to accelerate your AI projects and maximize GPU efficiency.
Scalability
Scalability directly impacts how efficiently your infrastructure can handle growing data volumes and increasingly complex model training processes. Choose a cloud GPU provider that supports elastic scaling to easily add or remove GPU instances based on demand. For example, during high-demand periods, such as training large language models for tasks like text generation or sentiment analysis, you can process vast amounts of text data in parallel, reducing training time while ensuring model accuracy as datasets grow.
Cost evaluation
When choosing a cloud GPU for your project, evaluate cost factors associated with billing, GPU model, storage, and data transfer to avoid budget overruns.
Decide between the pricing models, such as on-demand vs. reserved instances. Most providers offer on-demand pricing because of its flexibility, where you are billed by the second or hour. While this model is well-suited for workloads fluctuating in demand, reserved instances are better for long-term GPU usage, such as continuous deep learning model training or real-time recommendation systems, where consistent GPU power is essential.
The GPU type impacts costs, as higher-performance GPUs come with premium pricing compared to entry-level options. While high-performance GPUs can accelerate processing times, they may lead to increased expenses if not necessary for the task at hand. For example, when you are building AI side projects or early-stage prototypes, you can opt for a more affordable option, such as an NVIDIA T4, which allows you to maintain performance without overspending. For larger, more complex projects like processing massive datasets in fields such as autonomous driving or climate modeling, requiring faster processing and higher computational power, invest in a high-end GPU like an NVIDIA H100 to ensure that your workload runs efficiently.
Data must be stored, accessed, and processed efficiently to maximize performance in cloud projects. When exploring different storage options, like block storage vs. object storage— consider opting for object storage when you deal with unstructured data like images, videos, or large datasets (that do not have a predefined structure). Block storage is ideal if you are building a “speed-critical” application that requires low-latency access, such as databases or financial transactional applications.
Be aware of the data transfer fees, particularly egress costs, which can escalate when moving large datasets to and from the cloud. While some providers may offer free data uploads (ingress), they might charge for downloads (egress), which can drive up expenses if you frequently retrieve results or transfer data across regions.
Integration with existing infrastructure
Ensure that your cloud provider’s GPU integrates with your current setup to avoid compatibility issues or disruptions. Start by confirming that the cloud provider supports the frameworks and libraries you already use, such as TensorFlow or PyTorch, and integrates smoothly with your storage and networking configurations. Check if the cloud provider’s infrastructure can handle the increased compute load without latency issues while processing real-time data.
Verify that your orchestration tools and operating system are compatible with the GPU, and run a small-scale test to catch any integration issues, such as compatibility problems with drivers or mismatches in network configurations, before scaling up. While taking these proactive steps will improve your overall workflow, be mindful of potential vendor lock-in and assess whether the cloud provider’s solutions might restrict your flexibility, complicating future cloud migrations or multi-cloud strategies.
Networking and data transfer speeds
To ensure smooth and efficient performance, focus on how fast data can move between your storage, compute instances, and GPUs. High bandwidth ensures that data moves quickly between your storage and the GPU, reducing any delays in processing. Low latency is essential for real-time tasks like gaming or live streaming, where even a slight lag can affect performance. Fast data transfer speeds help avoid bottlenecks, ensuring your GPU gets the data it needs to keep your tasks running smoothly. Plus, having a solid internal network for distributed workloads allows your instances to communicate efficiently and boost overall performance.
Support and reliability
Choose a cloud provider with a reliable support plan and strong uptime guarantees. For instance, if you’re running critical applications such as AI-driven diagnostics in healthcare, you’ll need a provider that ensures minimal downtime and responsive customer support. A trusted cloud provider ensures you meet deadlines and prevents expensive setbacks such as project overruns, missed opportunities, or operational disruptions.
By providing consistent uptime and timely technical assistance, you can maintain smooth project execution, avoid financial penalties, and maximize cloud ROI by keeping your projects on track and within budget.
Accelerate your AI projects with DigitalOcean GPU Droplets
Unlock the power of NVIDIA H100 GPUs for your AI and machine learning projects. DigitalOcean GPU Droplets offer on-demand access to high-performance computing resources, enabling developers, startups, and innovators to train models, process large datasets, and scale AI projects without complexity or significant upfront investments.
Key features:
-
Powered by NVIDIA H100 GPUs with 640 Tensor Cores and 128 Ray Tracing Cores
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
Sign up today and unlock the possibilities of GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
