AI/ML Technical Content Strategist

One of the most significant advancements in NVIDIA’s recent GPU microarchitectures is the introduction and evolution of Tensor Cores. These dedicated processing units, first introduced with the Volta architecture, are purpose-built to accelerate matrix operations—key components of deep learning workloads. Over time, Tensor Cores have been further refined across the Turing and Ampere architectures, dramatically improving performance and efficiency for AI training and inference.
Unlike standard CUDA cores, Tensor Cores are optimized for high-throughput tensor computations, enabling operations like matrix multiplication and accumulation at speeds that traditional GPU cores can’t match. A major innovation brought by Tensor Cores is their support for automatic mixed precision (AMP) training. By combining the speed of lower-precision arithmetic with the accuracy of higher-precision calculations, AMP allows deep learning models to train faster without sacrificing model accuracy.
In this article, we’ll explain how Tensor Cores differ from standard cores, how they function under the hood, and why they’ve become essential in modern deep learning workflows. We’ll also compare the capabilities of Tensor Cores across NVIDIA’s Volta, Turing, and Ampere GPU series—highlighting the architectural upgrades and performance gains with each generation.
Whether you’re a machine learning engineer, data scientist, or developer running compute-intensive workloads on platforms like DigitalOcean’s GPU Droplets, understanding how Tensor Cores contribute to training speedups and model scalability will help you make informed decisions about your GPU infrastructure.
By the end of this guide, you’ll have a solid grasp of:
- What Tensor Cores are and how they function,
- How do they enable mixed precision training in deep learning?
- The differences in Tensor Core performance across Volta, Turing, and Ampere,
- How to identify GPUs equipped with Tensor Cores and use them effectively.
Let’s dive in.
Key takeaways:
- Tensor Cores are specialized units in NVIDIA GPUs (starting with the Volta architecture) designed to accelerate matrix operations like multiplications and convolutions.
- They use lower-precision formats (such as FP16 or INT8) to perform many operations in parallel, significantly boosting performance for deep learning tasks.
- Mixed-precision computing allows Tensor Cores to maintain high accuracy by combining fast, low-precision calculations with higher-precision accumulation (e.g., FP16 compute with FP32 accumulation).
- To benefit from Tensor Cores, developers must use compatible libraries and enable mixed-precision training or inference in frameworks like PyTorch or TensorFlow.
- Without using the appropriate data types or settings, Tensor Cores remain underutilized, limiting potential performance gains.
Prerequisites
A basic understanding of GPU hardware is required to follow along with this article. We recommend looking at the NVIDIA website for additional guidance about GPU technology.
What are CUDA cores?

When discussing the architecture and utility of Tensor Cores, we first need to discuss CUDA cores. CUDA (Compute Unified Device Architecture) is NVIDIA’s proprietary parallel processing platform and API for GPUs, while CUDA cores are the standard floating point unit in an NVIDIA graphics card. These have been present in every NVIDIA GPU released in the last decade as a defining feature of NVIDIA GPU microarchitectures.
Each CUDA core is able to execute calculations and each CUDA core can execute one operation per clock cycle. Although less capable than a CPU core, when used together for deep learning, many CUDA cores can accelerate computation by executing processes in parallel.
Before the release of Tensor Cores, CUDA cores were the defining hardware for accelerating deep learning. Because they can only operate on a single computation per clock cycle, GPUs are limited to the performance of CUDA cores and are also limited by the number of available CUDA cores and the clock speed of each core. To overcome this limitation, NVIDIA developed the Tensor Core.
What are Tensor Cores?
According to Michael Houston from NVIDIA, Tensor Cores are specialized hardware units designed to accelerate mixed precision training. The first generation introduced a fused multiply-add operation, allowing two 4x4 FP16 matrices to be multiplied and added to either an FP16 or FP32 output matrix. This approach significantly speeds up deep learning computations by using lower-precision FP16 inputs while still producing a higher-precision FP32 result—delivering faster performance with minimal impact on model accuracy. Newer NVIDIA microarchitectures have taken this further by supporting even lower-precision formats to enhance efficiency without compromising training quality.
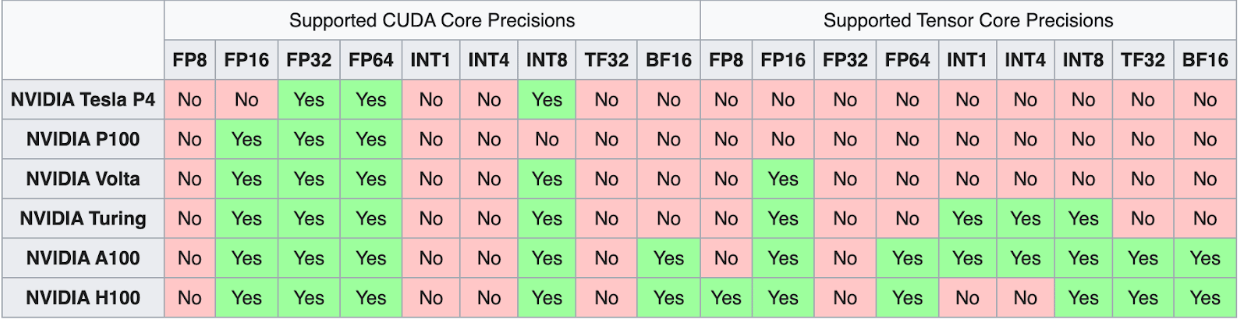
The first generation of Tensor Cores was introduced with the Volta microarchitecture, starting with the V100. With each subsequent generation, more computer number precision formats were enabled for computation with the new GPU microarchitectures. In the next section, we will discuss how each microarchitecture generation altered and improved the capability and functionality of Tensor Cores.
How do Tensor Cores work?

Each generation of GPU microarchitecture has introduced a novel methodology to improve performance among Tensor Core operations. These changes have extended the capabilities of the Tensor Cores to operate on different computer number formats. In effect, this massively boosts GPU throughput with each generation.
Info: Experience the power of AI and machine learning with DigitalOcean GPU Droplets. Leverage NVIDIA H100 GPUs to accelerate your AI/ML workloads, deep learning projects, and high-performance computing tasks with simple, flexible, and cost-effective cloud solutions.
Sign up today to access GPU Droplets and scale your AI projects on demand without breaking the bank.
First Generation
As shown in the visual comparison between Pascal and Volta computation, the first generation of Tensor Cores was introduced with NVIDIA’s Volta GPU microarchitecture. These cores brought mixed precision training to the forefront using the FP16 number format, significantly boosting computational throughput. With this advancement, GPUs like the V100 saw up to a 12x increase in teraFLOPs performance. Compared to the previous Pascal architecture, the V100’s 640 Tensor Cores delivered up to a 5x speedup in performance—marking a major leap in GPU efficiency and deep learning capabilities.
Second Generation
As shown in the visualization comparing Pascal and Turing computation speeds across different precision formats, the second generation of Tensor Cores debuted with NVIDIA’s Turing GPU architecture. Turing expanded Tensor Core support beyond FP16 to include even lower-precision formats like Int8, Int4, and Int1. These enhancements enabled mixed precision training to reach new levels of efficiency—delivering up to a 32x performance boost compared to Pascal GPUs.
Beyond Tensor Cores, Turing GPUs introduced Ray Tracing Cores as well. These specialized units handle the complex physics of light, reflection, and sound in real-time 3D environments. If you’re into game development or video production, RTX Quadro GPUs with Turing architecture can significantly elevate your creative workflow by harnessing both Tensor and Ray Tracing Cores.
Third Generation
 Comparison of DLRM training times in relative terms on FP16 precision - Source
Comparison of DLRM training times in relative terms on FP16 precision - Source
The Ampere line of GPUs introduced the third generation of Tensor Cores, which is the most powerful yet.
In an Ampere GPU, the architecture builds on the previous innovations of the Volta and Turing microarchitectures by extending computational capability to FP64, TF32, and bfloat16 precisions. These additional precision formats work to accelerate deep learning training and inference tasks even further. The TF32 format, for example, works similarly to FP32 while simultaneously ensuring up to 20x speedups without changing any code. From there, implementing automatic mixed precision will further accelerate training by an additional 2x with only a few lines of code. Furthermore, the Ampere microarchitecture has additional features like specialization with sparse matrix mathematics, third-generation NVLink to enable lightning-fast multi-GPU interactions, and third-generation Ray Tracing cores.
Ampere GPUs, particularly the data center A100, represent the current pinnacle of GPU power. For budget-conscious users, the workstation GPU series, including the A4000, A5000, and A6000, provides a cost-effective way to leverage the potent Ampere microarchitecture and its third-generation Tensor Cores.
Fourth Generation
As highlighted in the announcement of the Hopper microarchitecture and its capabilities, the fourth generation of Tensor Cores is set to debut with NVIDIA’s H100 GPU. First revealed in March 2022, the H100 introduces support for FP8 precision formats, which NVIDIA claims will accelerate large language model performance by an impressive 30x over the previous generation.
In addition to these computational gains, NVIDIA’s new NVLink technology—also part of the Hopper architecture—will connect up to 256 H100 GPUs. This advancement significantly expands the scale at which data professionals can train and deploy models, opening the door to even more powerful and efficient AI systems.
Which GPUs have Tensor Cores?
| GPU | Does it have Tensor Cores? | Does it have Ray Tracing Cores? |
|---|---|---|
| M4000 | No | No |
| P4000 | No | No |
| P5000 | No | No |
| P6000 | No | No |
| V100 | Yes | No |
| RTX4000 | Yes | Yes |
| RTX5000 | Yes | Yes |
| A4000 | Yes | Yes |
| A5000 | Yes | Yes |
| A6000 | Yes | Yes |
| A100 | Yes | Yes |
The GPU cloud offers a wide assortment of GPUs from the past five generations, including GPUs from the Maxwell, Pascal, Volta, Turing, and Ampere microarchitectures.
Maxwell and Pascal microarchitectures predate the development of Tensor Cores and Ray Tracing cores. The effect of this difference in composition is very clear when looking at deep learning benchmark data for these machines, as it clearly shows that more recent microarchitectures will outperform older microarchitectures when they have similar specifications, like memory.
The V100 is currently the only GPU that comes equipped with Tensor Cores, although it lacks Ray Tracing cores. While it is still a strong deep learning machine overall, the V100 was the first data center GPU to introduce Tensor Cores. However, its older design has resulted in it lagging behind workstation GPUs like the A6000 in terms of performance for deep learning tasks.
The workstation GPUs, RTX4000 and RTX5000, provide excellent budget-friendly options for a GPU platform suited for deep learning. Notably, the second-generation Tensor Cores significantly enhance the capabilities of RTX5000, allowing it to achieve performance levels nearly comparable to those of V100 in terms of batch size and time to completion for benchmarking tasks.
The Ampere GPU line, which features both third-generation Tensor Cores and second-generation Ray Tracing cores, boosts throughput to unprecedented levels over previous generations. This technology enables the A100 to have a throughput of 1555 GB/s, up from the 900 GB/s of the V100.
In addition to the A100, the workstation line of Ampere GPUs includes the A4000, A5000, and A6000. These offer excellent throughput and the powerful Ampere microarchitecture at a much lower price point.
Once the Hopper microarchitecture is officially released, the H100 GPU is expected to deliver up to 6x the performance of the current peak offered by the A100. According to NVIDIA CEO Jensen Huang during the GTC 2022 Keynote, the H100 will not be available for purchase until at least the third quarter of 2022.
FAQ
1. How do Tensor Cores perform a fused multiply-add operation?
Tensor Cores are designed to execute a fused multiply-add (FMA) operation very efficiently. Specifically, they multiply two input matrices and immediately add the result to a third matrix—all in a single step. This reduces the number of operations, minimizes memory access latency, and boosts throughput significantly. This fusion is especially beneficial in deep learning workloads like matrix multiplications and convolutions, where these operations dominate.
2. What is the significance of FP16 and FP32 formats in mixed precision training?
FP16 (half-precision) allows faster computation and lower memory usage, which enables training on larger batch sizes or models. However, using FP16 alone can lead to numerical instability, such as underflow or overflow. That’s where FP32 (single-precision) comes in—it is used for critical calculations like gradient accumulation, ensuring stability and accuracy. Mixed precision training smartly balances the two formats: compute-heavy tasks are handled in FP16 for speed, while FP32 maintains accuracy where needed.
3. Which NVIDIA GPUs contain Tensor Cores, and which do not?
Tensor Cores were first introduced in NVIDIA’s Volta architecture (e.g., Tesla V100), and have since been included in Turing (e.g., RTX 2080), Ampere (e.g., A100, RTX 3090), and the latest Hopper (e.g., H100) GPUs. These GPUs are optimized for AI workloads and benefit greatly from Tensor Core acceleration. In contrast, older architectures like Pascal (e.g., GTX 1080 Ti, Titan Xp) do not include Tensor Cores, so they lack the same level of performance for deep learning tasks.
4. What is the difference between Ray Tracing Cores and Tensor Cores? How do Tensor Cores accelerate deep learning inference and training?
Ray Tracing Cores and Tensor Cores serve different purposes. Ray Tracing Cores are built for rendering lifelike lighting, shadows, and reflections in real-time graphics (especially in gaming and simulations). Tensor Cores, on the other hand, are optimized for AI workloads. They accelerate deep learning by processing matrix operations—like those used in neural networks—at high speed and low precision. This allows for faster forward passes (inference) and backward passes (training), especially in large models like transformers or CNNs.
5. What kinds of AI and machine learning tasks benefit most from Tensor Cores?
Tensor Cores deliver the biggest advantages in compute-heavy tasks that rely heavily on matrix multiplications and convolutions. This includes:
- Image classification and object detection with CNNs,
- Natural language processing using transformer models (e.g., BERT, GPT),
- Generative models like GANs and VAEs,
- Speech recognition and machine translation,
- Large language models (LLMs) used in chatbots and content generation. These tasks see significant improvements in speed and memory efficiency with Tensor Core utilization.
6. Why is mixed precision training beneficial in terms of speed and memory?
Mixed precision training combines the benefits of FP16 and FP32 to achieve faster and more memory-efficient training. Using FP16 reduces the size of tensors and speeds up arithmetic operations, allowing for larger batch sizes and better GPU utilization. Meanwhile, using FP32 for key steps like loss scaling or gradient updates maintains model stability. This approach often leads to up to 3x speed improvements and reduced memory footprint, all while maintaining comparable model accuracy.
7. What are the limitations and drawbacks of using Tensor Cores? Tensor Cores come with a few challenges. Since they rely on lower-precision formats like FP16, there’s a risk of numerical issues—like gradient underflow or unstable training—unless you use techniques like loss scaling and mixed-precision training carefully. Their performance benefits also drop off when working with small batch sizes or tensor shapes that don’t align to multiples of 8. Not every operation can take advantage of Tensor Cores, which can lead to bottlenecks in mixed workloads. Debugging becomes trickier too, especially with mixed-precision setups. Memory usage patterns can also differ, sometimes requiring code tweaks. And for older or legacy models, you might not see big speedups without reworking the architecture. That said, when implemented properly, Tensor Cores still offer a major boost for most modern AI workloads.
Concluding thoughts
Technological progress across GPU generations is closely tied to the evolution of Tensor Core technology. As explored throughout this article, Tensor Cores enable high-performance mixed-precision training that has propelled NVIDIA’s Volta, Turing, and Ampere architectures to the forefront of AI development. With each generation, these cores have significantly increased the volume of data that can be processed for deep learning tasks in real time. By understanding the capabilities and differences between each version of Tensor Cores, developers can better leverage their power—especially when combined with scalable, on-demand infrastructure like DigitalOcean GPU Droplets, which offer a seamless way to train and deploy AI models efficiently.
Resources
- Nvidia - Tensor Cores
- Nvidia - Tensor Cores (2)
- Nvidia - Hopper Architecture
- Nvidia - Ampere Architecture
- Nvidia - Turing Architecture
- Nvidia - Volta Architecture
- H100 - Nvidia product page
- A100 - Nvidia product page
- V100 - Nvidia product page
- Full breakdown on Tensor Cores from TechSpot
- Succinct breakdown on Tensor Cores from TechCenturion
- TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
