LLMs are powerful tools for tasks like code generation, log analysis, and data parsing—letting engineers automate repetitive development work. For companies developing software tools, LLMs enable building AI-powered features into their products—from document analysis to conversational interfaces, which previously required teams of ML engineers and months of training custom models. However, general-purpose models can struggle with accuracy and precision when responding to nuanced queries about specialized fields like law, engineering, and medicine. Businesses adapted by fine-tuning, a technique in machine learning where you take a pre-trained model and further train it on a specific dataset to adapt it for a particular task or domain. For example, a business could fine-tune an LLM to build a chatbot that reflects its brand’s tone for a better conversational style with customers.
However, fine-tuning requires regular model retraining to incorporate new data and maintain performance, which can be resource-intensive and time-consuming for organizations seeking to keep their models current. As an alternative (or supplement), retrieval-augmented generation (RAG) improves LLM outputs by retrieving relevant information from external knowledge sources and then using this context during generation, making it ideal for fields where data evolves frequently. For example, the same business that fine-tuned a chatbot for brand consistency could use RAG to enable the bot to answer questions about the latest feature details for a SaaS tool or the most up-to-date return policy for an e-commerce store. RAG ensures the chatbot provides timely and accurate information without constant retraining, offering a flexible solution for tasks where precision and up-to-date knowledge are essential. This article explores RAG, fine-tuning, and factors you might consider while choosing between RAG vs fine-tuning.
Key takeaways:
-
Retrieval-Augmented Generation (RAG) improves AI responses by fetching relevant external information at query time, allowing models to incorporate up-to-date facts, whereas fine-tuning involves training a pre-existing model further on specialized data to improve its performance in a specific domain.
-
RAG is beneficial when an AI needs real-time access to a knowledge base or the latest information without retraining the entire model, making answers more accurate and context-specific by grounding them in retrieved data.
-
Fine-tuning tailors a model’s knowledge to a particular task and can boost accuracy for that task, but it requires additional data and training; the choice between RAG and fine-tuning depends on whether the priority is dynamic information access (RAG) or optimizing model behavior for a particular static dataset or task (fine-tuning).
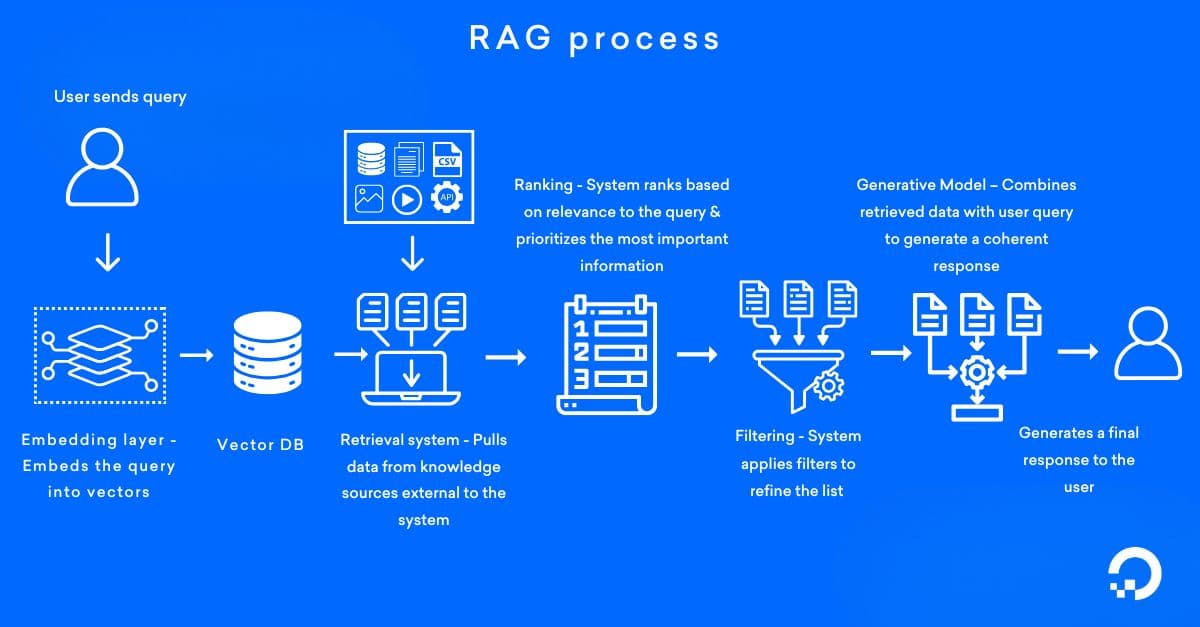
What is RAG?
RAG is a technique in natural language processing (NLP) and artificial intelligence (AI) introduced by Meta in 2020 that combines two components: information retrieval and text generation. In response to a user query, it retrieves relevant information from a knowledge base (which can contain structured or unstructured data). A generative model then uses this retrieved context along with the query to produce more accurate, grounded, and up-to-date responses.
What is fine-tuning?
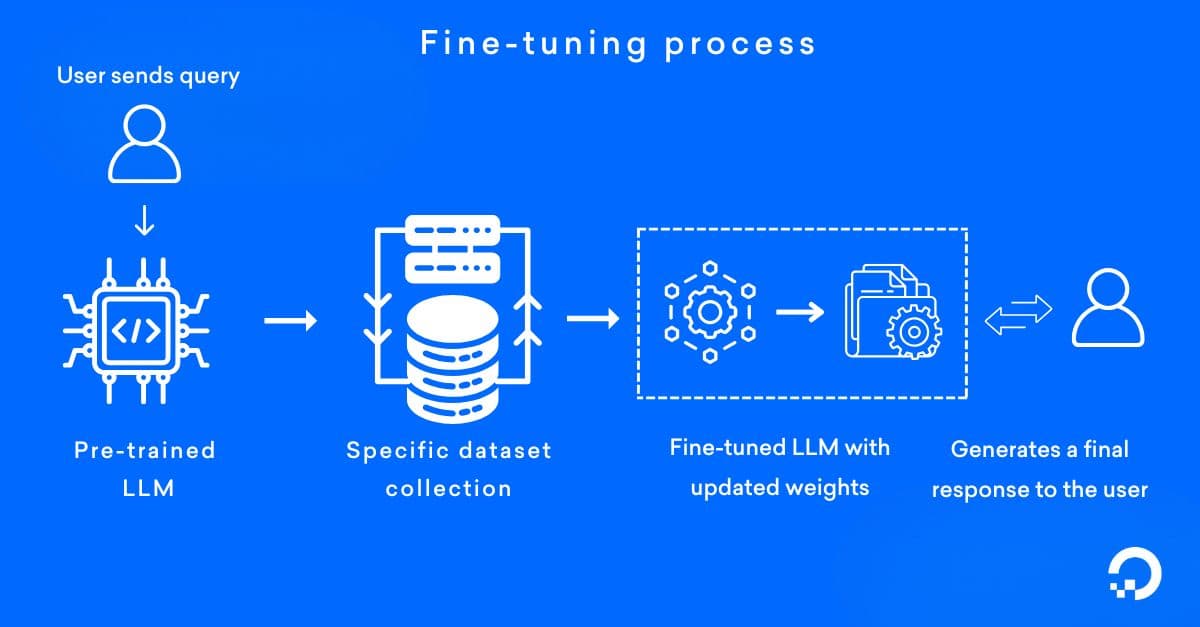
Fine-tuning is a machine learning technique that adapts pre-trained models for specific tasks or domains, and is widely used across various areas of AI, including NLP, computer vision, and speech recognition. It starts with a pre-trained model, trained on general datasets, and adjusts the model’s weights using a smaller, specific dataset relevant to a particular task. Once trained, the model is adapted to the nuances of the application, and then it is deployed into production, where it generates more relevant, context-specific refined outputs.
When to use RAG?
RAG is ideal when your model needs to retrieve up-to-date and/or external information not contained within its initial training data. However, be mindful that RAG depends on a knowledge base that needs to be consistently updated by your organization to maintain accurate and relevant results.
Learn how to containerize and deploy RAG applications on DigitalOcean GPU Droplets, with practical demonstrations showing how containerization solves common RAG deployment challenges.
Tackling vast datasets
Managing and retrieving the correct information becomes a challenge when you deal with a large and diverse knowledge base. In fields like healthcare and finance, there are extensive, continuously updated datasets of medical research, patient records, financial transactions, and market trends. RAG retrieves the latest information from external knowledge sources, such as medical studies or financial datasets provided by the organizations. It integrates it into an LLM to get coherent and relevant responses for the user.
Addressing ambiguity
You won’t always receive clear or well-defined queries when working with LLMs. Users often provide vague inputs, multiple meanings, or incomplete details. When users provide unclear or ambiguous queries, RAG helps by:
-
Retrieving relevant context that can help clarify the intended meaning
-
Providing the LLM with this additional context to generate more informed responses
-
Allowing the LLM to use both its trained understanding and the retrieved information to better interpret ambiguous queries
When to use fine-tuning?
You can deploy a fine-tuning model when adapting a pre-trained model to perform specialized tasks using domain-specific data. However, fine-tuning may lead to overfitting if the dataset is too small or needs more diversity, potentially compromising the model’s generalization capabilities. Overfitting occurs when a model learns the details and noise of the training data to the extent that it negatively impacts its performance on new, unseen data. As a result, while it may perform well on the training data, it struggles with accuracy and effectiveness on different datasets.
Learn how to fine-tune Mistral-7B, a powerful 7B parameter model that outperforms larger models like Llama-2 13B in reasoning, math, and code tasks, using cost-effective LoRA techniques. The step-by-step tutorial walks through fine-tuning the MosaicML instruct dataset using 4-bit quantization and LoRA, making it accessible even without massive GPU resources. Developers will learn hands-on strategies for state-of-the-art LLM fine-tuning, from data preparation through model optimization.
Handling exceptions
When dealing with rare or unusual scenarios not typically covered in a pre-trained model, you can consider fine-tuning. By fine-tuning labeled examples of these edge cases, you ensure the model can handle them accurately. This approach is practical when you need precise control over how the model responds in specialized or uncommon situations. It allows you to customize it to specific needs that general models can’t address.
Fine-tuning is effective when you label examples of rare bugs to train the model on specific cases. For instance, if a legacy software testing tool encounters unusual bugs specific to its architecture or outdated technologies, fine-tuning can refine the model’s understanding of these unique errors and accurately identify and classify such issues in future instances.
Static or specialized data needs
When you are developing applications with specific datasets that require adapting a pre-trained model, you can opt for fine-tuning. This occurs in niche applications where general models may perform poorly due to the uniqueness of the data or the task at hand. For example, the Mistral-7B-Instruct-v0.1 LLM is an instruct fine-tuned version of the Mistral-7B-v0.1 generative text model, improved through fine-tuning on various publicly available conversation datasets.
Clear and defined task objectives
Fine-tuning becomes a practical approach when tasks are clear and well-defined. You may encounter scenarios where specific outputs are required, such as generating content, answering questions, or classifying data based on precise criteria. In such cases, fine-tuning takes a pre-trained model and trains it further on a smaller, task-specific dataset. This process adjusts the model’s weights to better align with the nuances and requirements of the target task. By providing labeled examples during training, the model learns to recognize patterns and relationships relevant to the specific outputs you need.
For instance, if the task is to classify emails as spam or not, fine-tuning the model with a dataset of labeled emails allows it to learn the characteristics of spam messages, leading to improved accuracy in identifying similar emails in the future.
💡Ready to elevate your AI and machine learning projects to new heights?
DigitalOcean GPU Droplets provide flexible, cost-effective, and scalable solutions tailored to your workloads. Seamlessly train and infer AI/ML models, handle massive datasets, and conquer complex neural networks for deep learning—all while meeting high-performance computing (HPC) demands.
What factors should be considered when choosing between RAG and fine-tuning?
RAG and fine-tuning both aim to improve model performance. However, they differ in how they achieve this—RAG retrieves external information from a knowledge base while fine-tuning adapts the model using a fixed dataset. Depending upon your use case, combining both methods, a hybrid approach might offer the best of both worlds: domain-specific expertise with access to the latest information. By considering the following factors, you can determine which approach best suits your needs and ensures the most effective results for your project.
Model training resources
Since RAG retrieves information from external sources rather than relying on extensive pre-training, you don’t need to spend much time or resources training the model. This makes RAG a good choice when you need fast deployment or when you lack the infrastructure to handle large-scale training. While RAG minimizes initial training costs, the knowledge source database must be constantly updated to deliver relevant and accurate responses. Over time, the costs of maintaining and scaling this database might increase if you’re dealing with large volumes of data or need frequent updates.
Curious to build a knowledge-driven chatbot using RAG?
Learn how to create your own RAG application with GPU Droplets—perfect for handling large text data and providing accurate, up-to-date responses!
While fine-tuning your model, you’ll need access to high-performance GPUs and substantial datasets to train the model effectively on your specific task. Fine-tuning is more resource-intensive because you’re adjusting the model’s internal parameters, which can take time and considerable computing power, especially for large models. Fine-tuning can offer more precise control over model behavior if you have the necessary infrastructure and time. While fine-tuning costs a hefty upfront investment in computational resources, time, and infrastructure, it might require less ongoing maintenance once the model is fine-tuned.
Response time
Since RAG retrieves information from external sources stored in a vector database, the retrieval speed might affect how quickly responses are generated. You might encounter slight delays if you’re dealing with a large or complex knowledge base. If real-time performance is important to your application, focusing on minimizing database query times will keep response speeds fast and efficient.
With fine-tuned models, everything is handled within the pre-trained model, meaning responses are generated instantly without external lookups. This gives you faster, more reliable response times, making it an ideal choice for applications where low latency is a priority.
Performance metrics
RAG is assessed based on its ability to retrieve relevant, contextually accurate information. Key metrics include the retrieved documents’ precision, recall, and relevance and the generated responses’ quality. Since RAG pulls from external sources, ensure the retrieved content aligns with the query’s intent. You’ll focus on metrics like retrieval accuracy and response fluency for tasks that handle diverse or open-ended queries.
For fine-tuning, the evaluation criteria tend to be more task-specific and directly tied to the model’s performance on a narrowly defined objective. Metrics such as accuracy, F1 score, or BiLingual Evaluation Understudy score (BLEU score - for language tasks) are used, depending on the application. Fine-tuned models are optimized for consistency and precision within a specific domain, so you’ll prioritize task-specific metrics, ensuring the model’s performance is stable and repeatable over time.
LLM architecture considerations
RAG’s hybrid approach combines a transformer-based model (a neural network process for handling sequential data like text) with an external knowledge base. It doesn’t require heavy customization of the model itself, but the LLM must be capable of integrating external knowledge seamlessly. You’ll need an LLM that’s strong in general-purpose knowledge and can interpret a wide range of queries. In this case, the LLM’s ability to work well with external databases or knowledge sources is more important than deep training on domain-specific tasks.
Fine-tuning relies on a pre-trained LLM adjusted for a specific task by training on a dataset. Choose a model that’s open to adaptation and can be fine-tuned for highly specialized tasks. The LLM should be versatile and able to handle targeted training efficiently. The fine-tuning process is more resource-intensive and demands an LLM that can be adapted for precise, task-specific goals. If your tasks are well-defined and don’t require frequent updates, fine-tuning offers a simplified approach that improves performance without altering the foundational structure of the model.
FAQs:
What is the main difference between RAG and fine-tuning?
RAG (Retrieval-Augmented Generation) improves LLM outputs by retrieving relevant information from external knowledge sources during generation, making it ideal for frequently changing data. Fine-tuning adapts a pre-trained model by further training it on specific datasets to adjust the model’s weights for particular tasks or domains, providing more precise control over model behavior.
When should you use RAG instead of fine-tuning?
RAG is ideal when your model needs up-to-date or external information not in its training data, when dealing with large and diverse knowledge bases, or when handling ambiguous queries that need additional context. It’s also better for scenarios where data changes frequently, as RAG can provide real-time information without requiring model retraining.
What are the cost considerations between RAG and fine-tuning?
RAG requires less upfront training costs since it doesn’t need extensive model retraining, but the knowledge database must be constantly updated, which can increase ongoing costs. Fine-tuning requires a hefty upfront investment in computational resources, high-performance GPUs, and substantial datasets, but might require less ongoing maintenance once completed.
How do RAG and fine-tuning compare in terms of performance and speed?
Fine-tuned models provide faster, more reliable response times since everything is handled within the pre-trained model without external lookups, making them ideal for low-latency applications. RAG retrieval speed might be affected by database query times, potentially causing slight delays, but offers more accurate and up-to-date information by pulling from external sources.
Accelerate your AI projects with DigitalOcean Gradient GPU Droplets
Accelerate your AI/ML, deep learning, high-performance computing, and data analytics tasks with DigitalOcean Gradient GPU Droplets. Scale on demand, manage costs, and deliver actionable insights with ease. Zero to GPU in just 2 clicks with simple, powerful virtual machines designed for developers, startups, and innovators who need high-performance computing without complexity.
Key features:
-
Powered by NVIDIA H100, H200, RTX 6000 Ada, L40S, and AMD MI300X GPUs
-
Save up to 75% vs. hyperscalers for the same on-demand GPUs
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
-
HIPAA-eligible and SOC 2 compliant with enterprise-grade SLAs
Sign up today and unlock the possibilities of DigitalOcean Gradient GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
