AI Technical Writer

Introduction
Deep learning technology has rapidly evolved and has become a key player in our daily lives, particularly in this era of speech-to-text applications. Whether it’s powering automated AI call systems, voice assistants such as SIRI or Alexa, or seamlessly integrating with search engines, this feature significantly enhances user experiences. Its widespread adoption has made it an integral part of our lives.
Emerging as a formidable contender in the arena of open source AI’s, the Audio Speech Recognition (ASR) model Whisper by OpenAI has gained immense popularity. It presents a level of effectiveness comparable to other production-grade models, all while being accessible to users at zero cost. Additionally, it provides a range of pre-trained models for users to leverage the power of AI to transcribe and translate any audio piece.
In this article, we will examine the recently released Distil Whisper project. This latest iteration of the Whisper model offers a 6x speedup in running. We will also examine what made this model release possible and conclude with a code demonstration.
Key Points
- Model Size Reduction: Distil Whisper is 49% smaller than the original Whisper model while maintaining critical functionality.
- Performance Boost: Achieves up to 6x speed improvements in inference time compared to the original Whisper model, making it ideal for real-time applications and large-scale transcription tasks.
- Accuracy Retention: Maintains performance within 1% Word Error Rate (WER) of the original Whisper model on out-of-distribution audio datasets.
- Technical Innovations: Implements layer-based compression, pseudo-labeling, and Kullback-Leibler divergence techniques to effectively transfer knowledge from the teacher model.
- Enhanced Robustness: Shows 1.3x fewer instances of repeated word duplications and 2.1% reduction in insertion error rate compared to the original model, resulting in better handling of noisy audio.
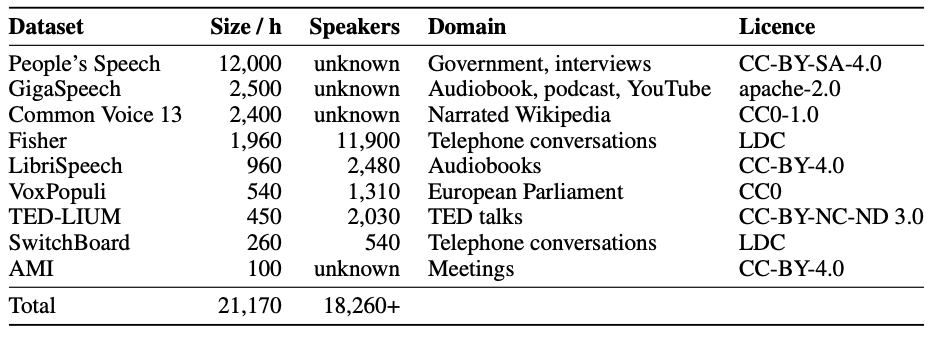
- Training Data: Trained on 22,000+ hours of pseudo-labeled audio data spanning 10 domains and 18,000+ speakers for comprehensive coverage.
- Commercial License: Available under a commercial license, making it suitable for business applications and production environments.
- Seamless Integration: Works with Hugging Face Transformers library for easy implementation in existing audio processing pipelines.
- Optimized for Various Scenarios: Specialized algorithms for both short-form (under 30 seconds) and long-form transcription with efficient chunking.
- Hardware Flexibility: Supports both CPU and GPU acceleration, with optimized performance on CUDA-compatible hardware.
Prerequisites
- Python 3.8+ installed.
- PyTorch 2.0+ with CUDA support (for GPU acceleration).
- Install dependencies: pip install transformers datasets torchaudio.
- Familiarity with the Whisper model and audio processing basics.
What is Knowledge distillation (KD)?
Before we dive deeper into the model itself, let’s discuss what makes the speedups possible for Distil Whisper. Knowledge distillation (KD) refers to the process of training a smaller and a computationally efficient model, also known as the student which tries to mimic the behaviour of a larger and more complex model or the teacher. Essentially, it is a form of model compression which helps in transferring the knowledge from a larger model to train a smaller model without any significant loss in performance. Here, knowledge refers to the learned weights and biases, which represent the pattern understanding in a trained model.
The large model a.k.a. teacher is trained on a task of interest, such as NLP tasks, image recognition, and much more. This deep learning model is computationally very expensive. Next, a student model is created and trained on the same tasks and this model retains the knowledge of the teacher model. Here, the key idea is to use the teacher’s model predictions, the softened probabilities or logits, as targets to train the student model.
During the training process, the student model aims to mimic not just the final predictions of the teacher model, but also the knowledge embedded in the intermediate steps as well. This transfer of knowledge helps the student model generalize better and perform well on the task while reducing the complexities.
This model distillation has proven to demonstrate substantial reduction in model size and computational requirements with minimal to no degradation of performance.
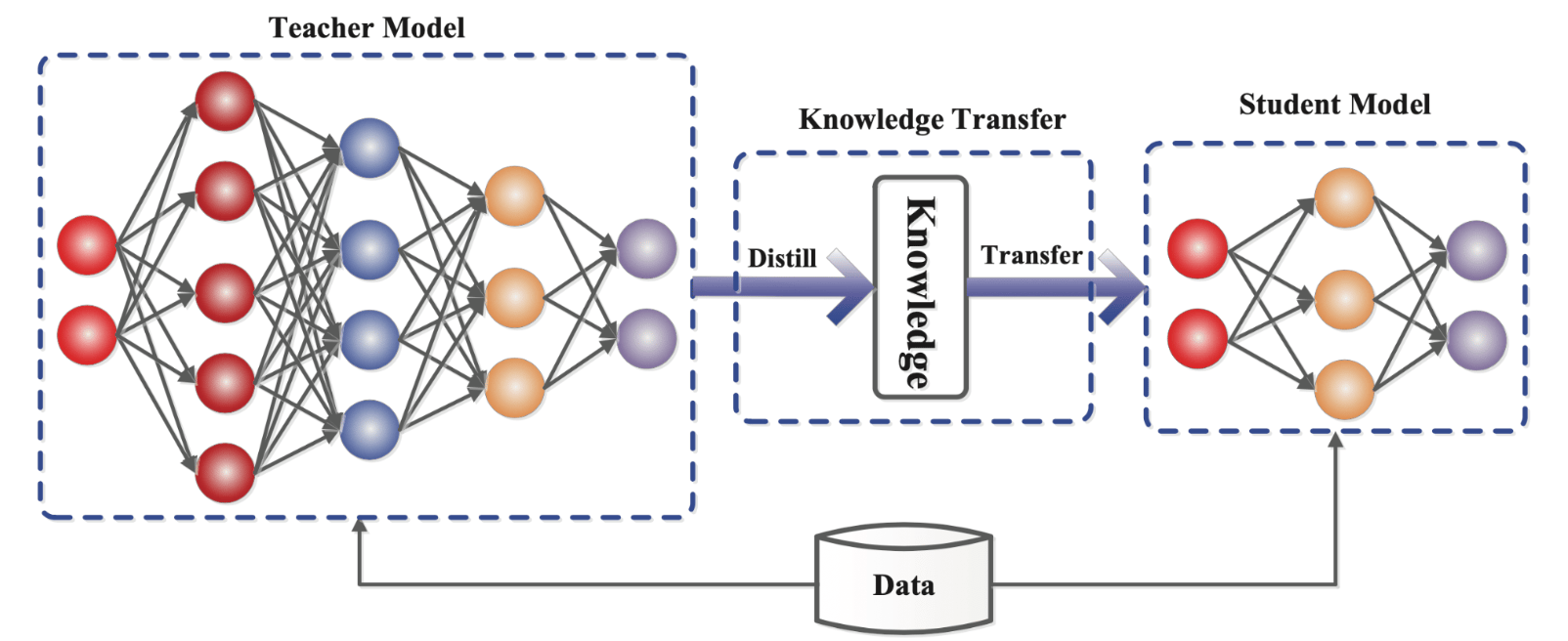
In the case of Distil-Whisper, the teacher model is Whisper and the student model is Distil-Whisper. Both models share the same Seq2Seq architecture but with different dimensionality.
The Distil Model
Now, let’s take a look at the Distil Whisper model itself. First, it’s important to understand what differentiates the new model release from the original. The major changes proposed in the research paper, to compress the mode, are briefly discussed below:
Shrink and Fine-Tune: For the Distilled model, the researchers implemented layer-based compression. This is done by initializing the student model through the replication of weights from layers that are maximally spaced apart in the teacher model. For example, when setting up a 2-layer student model based on a 32-layer teacher model, the weights of the first and 32nd layers from the teacher to the student are replicated.
Pseudo Labeling: This form of distillation can be also viewed as “sequence-level” KD, in this process knowledge is transferred to the student model in a sequence. This sequence is generated in Pseudo-labels.
Kullback-Leibler Divergence: In the KL Divergence, the complete probability distribution of the student model is trained to align with the distribution of the teacher model. This alignment is achieved by minimizing the Kullback-Leibler (KL) divergence across the entire set of potential next tokens at the i_th position. This can be interpreted as “word-level” knowledge distillation, wherein knowledge is passed from the teacher model to the student model through the logits associated with the potential tokens.
Distil-Whisper
Recent developments in natural language processing (NLP) have shown significant progress in the compression of transformer-based models. Successful applications of knowledge distillation (KD) have been observed in reducing the size of models like BERT without any significant performance loss. Distil-Whisper, a distilled version of Whisper, boasts a remarkable enhancement - being 6 times faster, 49% smaller in size, and achieving a performance level within 1% word error rate (WER) on out-of-distribution evaluation sets.
To achieve this, it’s worth noticing in particular that the training objective was optimized to involve minimizing both the KL divergence between the distilled model and the Whisper model, and the cross-entropy loss computed on pseudo-labeled audio data.
The Distil-Whisper is trained on 22k hours of pseudo-labelled audio data, consisting of 10 domains with more than 18k speakers.
What is new in Distil Whisper?
To ensure the training solely incorporates reliable pseudo-labels, a straightforward heuristic approach is introduced that refines the pseudo-labeled training dataset. For every training sample, both the ground truth labels and the pseudo-labels generated by Whisper are normalized, using the Whisper English normalizer. Once done, the word error rate (WER) between the normalized ground truth and pseudo-labels is computed. The samples exceeding the given WER threshold are discarded. This filtering method improves the quality of the transcription and model performance.
The original Whisper paper introduces a long-form transcription algorithm that systematically transcribes 30-second audio segments, adjusting the sliding window based on timestamps predicted by the model. In Distil Whisper, an alternative strategy is used in which the long audio file is chunked into smaller fragments with small overlapping adjacent segments in between. The model processes each chunk, and the inferred text is connected at intervals by identifying the longest common sequence between overlapping portions. This stride facilitates precise transcription across chunks without the need for sequential transcription.
Speculative Decoding (SD) is an approach to expedite the inference process of autoregressive transformer models by incorporating a faster assistant model. By utilizing the faster assistant model for generation and restricting the validation forward passes to the main model only, the decoding process experiences a substantial acceleration. SD helps in generating the output that matches the sequence of the tokens generated by the main model. The same approach is applied using Distil Whisper as the assistant to the Whisper model.
Speculative Decoding delivers substantial latency improvements while ensuring identical outputs mathematically. This makes it a seamless and logical replacement for existing Whisper pipelines.
Architecture
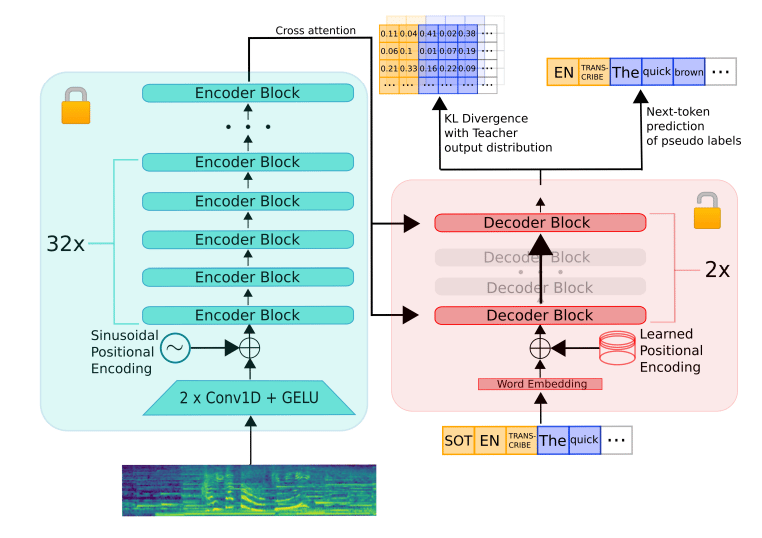
Pictured below is a figure representing the architecture of the Distil Whisper model. The encoder, depicted in green, is entirely replicated from the teacher to the student and remains fixed during training. The student’s decoder comprises only two decoder layers, initialized from the initial and final decoder layers of the teacher (depicted in red). All other decoder layers of the teacher are omitted.
The model undergoes training based on a weighted combination of KL divergence and PL loss terms. During inference, it is able to use this to sequentially identify the next most likely token with respect to both the text’s latent encoding as well as the audio. First, a waveform audio snippet is inputted to the encoder module. The audio is encoded with respect to the temporal position within. The decoder block is able to then sequentially process the encoded input tokens. The decoder block then takes this encoding, along with the previous token in the input sequence, using a Beginning of Sequence (BOS) token at the start, to decode the output as a string.
Capabilities
Distil-Whisper is designed to replace Whisper for English speech recognition. The capabilities of Distil-Whisper can essentially be boiled down to 5 main key functionalities:
Faster Inference: Achieving an inference speed six times faster, while maintaining performance within 1% Word Error Rate (WER) of Whisper on out-of-distribution audio.
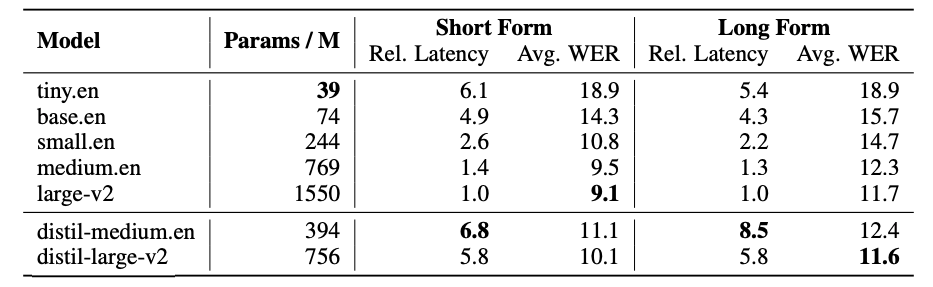
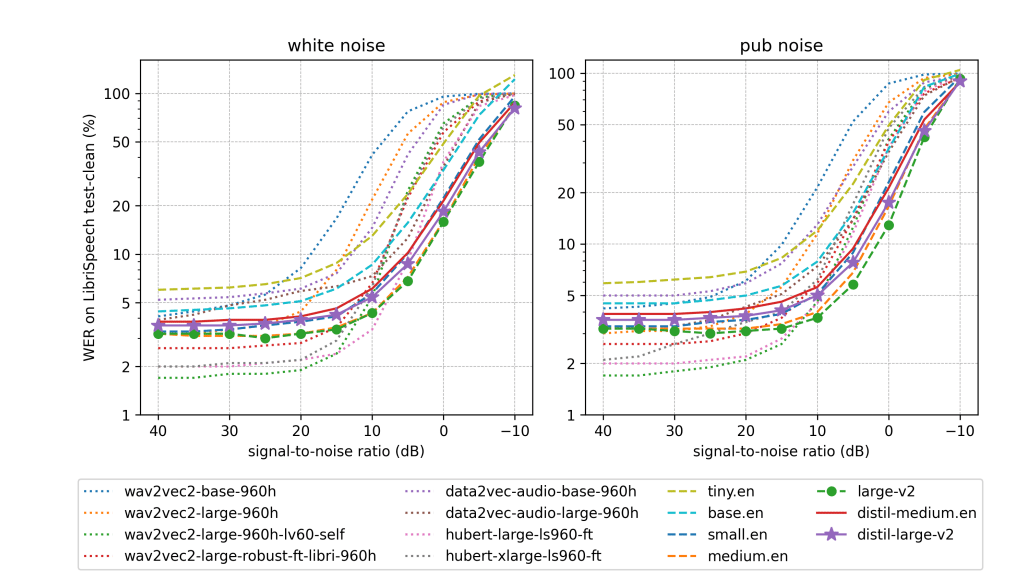
Robustness to noise and hallucinations: The plot shows that as the noise becomes more intensive, the WER of the Distil-Whisper degrades less severely compared to other models, which are trained on the LibriSpeech corpus. Quantified by 1.3 times fewer instances of repeated 5-gram word duplicates and a 2.1% reduction in insertion error rate (IER) compared to Whisper. This suggests that the extent of hallucination is reduced in Distil-Whisper compared to the original Whisper model. The average deletion error rate (DER) remains comparable for both large-v2 and distil-large-v2, with performance differing by ~ 0.3% DER.
Designed for speculative decoding: Distil-Whisper serves as an assistant model for Whisper, providing a two-fold increase in inference speed while mathematically guaranteeing identical outputs to the Whisper model. Commercial License: Distil-Whisper is licensed and can be used for commercial applications.
Code Demo
Following this guide, we can run the Distil-Whisper model and transcribe audio samples of speech in very little time.
#Install the dependencies
!pip install --upgrade pip
!pip install --upgrade transformers accelerate datasets[audio]
Short-Form Transcription
Short-form transcription involves transcribing audio samples lasting less than 30 seconds, which aligns with the maximum receptive field of Whisper models.
Load the Distil-Whisper using AutoModelForSpeechSeq2Seq and AutoProcessor classes.
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
Next, pass the model and the processor to the pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
Load the dataset from the LibriSpeech corpus,
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
Call the pipeline to transcribe the sample audio,
result = pipe(sample)
print(result["text"])
To transcribe a sample audio stored locally, make sure to pass the path to the file.
result = pipe("path_to_the_audio.mp3")
print(result["text"])
Long-Form Transcription
To transcribe long audio (longer than 30 seconds) Distil-Whisper uses a chunked algorithm. Here, we will use the long-form saved audio from the directory.
Load the model and processor again:
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "distil-whisper/distil-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
To enable chunking, we will utilize the chunk_length_s parameter in the pipeline. For Distil-Whisper, the minimum chunk length is 15 seconds. In order to activate batching, include the batch_size argument.
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=15,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
Now, we’ll load a lengthy audio sample that has been stored in the directory for your convenience. Pass the path to the saved audio file to transcribe. Also feel free to upload any mp3 samples of your choice to the directory and transcribe it using this code demo.
result = pipe('/content/I_used_LLaMA_2_70B_to_rebuild_GPT_Banker...and_its_AMAZING_(LLM_RAG).mp3')
print(result["text"])
Import the textwrap library, we can use the library to view the result as a formatted paragraph.
import textwrap
wrapper = textwrap.TextWrapper(width=80,
initial_indent=" " * 8,
subsequent_indent=" " * 8,
break_long_words=False,
break_on_hyphens=False)
print(wrapper.fill(result["text"]))
Speculative Decoding
Speculative decoding guarantees similar outputs to the Whisper model, but achieves this at twice the speed. This characteristic positions Distil-Whisper as an ideal seamless replacement for current Whisper pipelines, ensuring consistent results while enhancing efficiency.
For Speculative Decoding, we need both the teacher and the student model.
Load the teacher model ‘openai/whisper-large-v2’ and the processor.
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v2"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
Next, load the student model. The Distil-Whisper shares the exact same encoder as the teacher model; it is only necessary to load the 2-layer decoder, effectively treating it as a standalone “Decoder-only” model.
from transformers import AutoModelForCausalLM
assistant_model_id = "distil-whisper/distil-large-v2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
Pass the student model to the pipeline,
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
Once done, pass the sample to be transcribed,
from datasets import load_dataset
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
For additional optimisation, use Flash Attention 2
!pip install flash-attn --no-build-isolation
To activate Flash Attention 2, simply pass the parameter use_flash_attention_2=True to the from_pretrained function during initialization.
In case the GPU is not supported, please use BetterTransformers. To do so, install optimum.
!pip install --upgrade optimum
The code below converts the model to a “BetterTransformer” model,
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
model = model.to_bettertransformer()
FAQ’s
1. What makes Distil Whisper different from the original Whisper model? Distil Whisper is a distilled version of the original Whisper, meaning it’s trained to retain most of the performance while being smaller and faster. Unlike the heavy Whisper model that can be computationally expensive, Distil Whisper is optimized for speed and efficiency, allowing near real-time transcription without needing high-end GPUs.
2. Does Distil Whisper compromise accuracy for speed? Not significantly. While there is a slight reduction in accuracy compared to the full Whisper model, Distil Whisper is designed to strike a balance—providing much faster transcription with accuracy levels that remain competitive and usable across different applications.
3. Who should use Distil Whisper? Distil Whisper is ideal for developers, content creators, and businesses that need scalable transcription solutions. Whether you’re building a live captioning tool, transcribing podcasts, or generating subtitles for multilingual content, Distil Whisper offers an efficient solution.
4. Can Distil Whisper handle multilingual transcription? Yes. Distil Whisper, like the original Whisper, supports multiple languages. This makes it highly valuable for international use cases, such as transcribing interviews, webinars, or YouTube videos in different languages.
5. How can I get started with Distil Whisper? You can access Distil Whisper through open-source repositories and integrate it into your workflow with minimal setup. Developers can run it on local machines or cloud platforms, and it works well even on less powerful GPUs, making it beginner-friendly and cost-efficient.
Closing thoughts
In this article, we introduced Distil-Whisper, which is a distilled and accelerated version of Whisper. Distil-Whisper stands out as an exceptionally impressive model and serves as an excellent candidate for testing applications. On out-of-distribution long-form audio, DistilWhisper surpasses Whisper, exhibiting fewer instances of hallucinations and repetitions. This highlights the effectiveness of large-scale pseudo-labeling in distilling ASR models, especially when combined with our Word Error Rate (WER) threshold filter. We further demonstrated Distil-Whisper and seamlessly used the model to transcribe long-form and short-form audio in English.
References
- Original Research Paper : DISTIL-WHISPER: ROBUST KNOWLEDGE DISTILLATION VIA LARGE-SCALE PSEUDO LABELLING
- Code reference Hugging Face GitHub repo: distil-whisper
- Whisper blog post: Create your own speech-to-text application with Whisper from OpenAI and Flask
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
