By ayoosh katuria and Shaoni Mukherjee

Introduction
When working with deep learning models that use PyTorch, efficiently managing GPUs can make a huge difference in performance. Whether you’re training large models or running complex computations, using multiple GPUs can significantly speed up the process. However, handling multiple GPUs properly requires understanding different parallelism techniques, automating GPU selection, and troubleshooting memory issues.
In this article, we’ll explore:
- How do you use multiple GPUs for your network, whether through data parallelism (splitting data across GPUs) or model parallelism (distributing model layers across GPUs)?
- How to automate GPU selection so PyTorch assigns available GPUs to new objects.
- How to diagnose and fix memory issues, ensuring smooth training and inference without running into out-of-memory errors.
By the end of this guide, you will understand how to optimize GPU usage in PyTorch.
Prerequisites
Before diving into PyTorch 101: Memory Management and Using Multiple GPUs, ensure you have the following:
- Basic understanding of Python and PyTorch.
- PyTorch is installed on your system.
- Access to a CUDA-enabled GPU or multiple GPUs for testing (optional but recommended).
- Familiarity with GPU memory management concepts (optional but beneficial).
- pip for installing any additional packages.
Moving tensors around CPU / GPUs
Every Tensor in PyTorch has a to() member function. It’s job is to put the tensor on which it’s called to a certain device whether it be the CPU or a certain GPU. Input to the to function is a torch.device object which can initialised with either of the following inputs.
cpufor CPUcuda:0for putting it on GPU number 0. Similarly, if you want to put the tensors on
Generally, whenever you initialise a Tensor, it’s put on the CPU. You can move it to the GPU then. You can check whether a GPU is available or not by invoking the torch.cuda.is_available function.
if torch.cuda.is_available():
dev = "cuda:0"
else:
dev = "cpu"
device = torch.device(dev)
a = torch.zeros(4,3)
a = a.to(device) #alternatively, a.to(0)
You can also move a tensor to a certain GPU by giving it’s index as the argument to to function.
Importantly, the above piece of code is device agnostic, that is, you don’t have to separately change it for it to work on both GPU and the CPU.
cuda() function
One way to transfer tensors to GPUs is by using the cuda(n) function, where n specifies the index of the GPU. If you call cuda without arguments, the tensor will be placed on GPU 0 by default.
Additionally, the torch.nn.Module class provides to and cuda methods that can move the entire neural network to a specific device. Unlike tensors, when you use the to method on an nn.Module object, it’s sufficient to call the function directly; you do not need to assign the returned value.
clf = myNetwork()
clf.to(torch.device("cuda:0") # or clf = clf.cuda()
Automatic selection of GPU
It’s beneficial to explicitly choose which GPU a tensor is assigned to; however, we typically create many tensors during operations. We want these tensors to be automatically created on a specific device to minimize cross-device transfers that can slow down our code. PyTorch offers functionality to help us achieve this.
One useful function is torch.get_device. This function is only supported for GPU tensors and returns the index of the GPU on which a tensor is located. Using this function, we can determine the tensor device and automatically move any newly created tensor to that device.
#making sure t2 is on the same device as t2
a = t1.get_device()
b = torch.tensor(a.shape).to(dev)
We can also call cuda(n) while creating new Tensors. By default all tensors created by cuda call are put on GPU 0, but this can be changed by the following statement.
torch.cuda.set_device(0) # or 1,2,3
If a tensor results from an operation between two operands on the same device, the resultant tensor will also be on that device. If the operands are on different devices, an error will occur.
new_* functions
One can also use the new functions that made their way to PyTorch in version 1.0. When a function like new_ones is called on a Tensor, it returns a new tensor of the same data type and on the same device as the tensor on which the new_ones function was invoked.
ones = torch.ones((2,)).cuda(0)
# Create a tensor of ones of size (3,4) on same device as of "ones"
newOnes = ones.new_ones((3,4))
randTensor = torch.randn(2,4)
A detailed list of new_ functions can be found in PyTorch docs.
Using Multiple GPUs
There are two ways we could make use of multiple GPUs.
- Data Parallelism, where we divide batches into smaller batches and process these smaller batches in parallel on multiple GPUs.
- Model Parallelism involves breaking the neural network into smaller subnetworks and then executing these subnetworks on different GPUs.
Data Parallelism
Data Parallelism in PyTorch is achieved through the nn.DataParallel class. You initialize a nn.DataParallel object with a nn.Module object representing your network and a list of GPU IDs, across which the batches must be parallelized.
parallel_net = nn.DataParallel(myNet, gpu_ids = [0,1,2])
Now, you can simply execute the nn.DataParallel object just like a nn.Module .
predictions = parallel_net(inputs) # Forward pass on multi-GPUs
loss = loss_function(predictions, labels) # Compute loss function
loss.mean().backward() # Average GPU-losses + backward pass
optimizer.step()
However, there are a few things I want to clarify. Although our data has to be parallelized over multiple GPUs, we have to initially store it on a single GPU.
We also need to make sure the DataParallel object is on that particular GPU. The syntax remains similar to what we did earlier with nn.Module.
input = input.to(0)
parallel_net = parellel_net.to(0)
In effect, the following diagram describes how nn.DataParallel works.
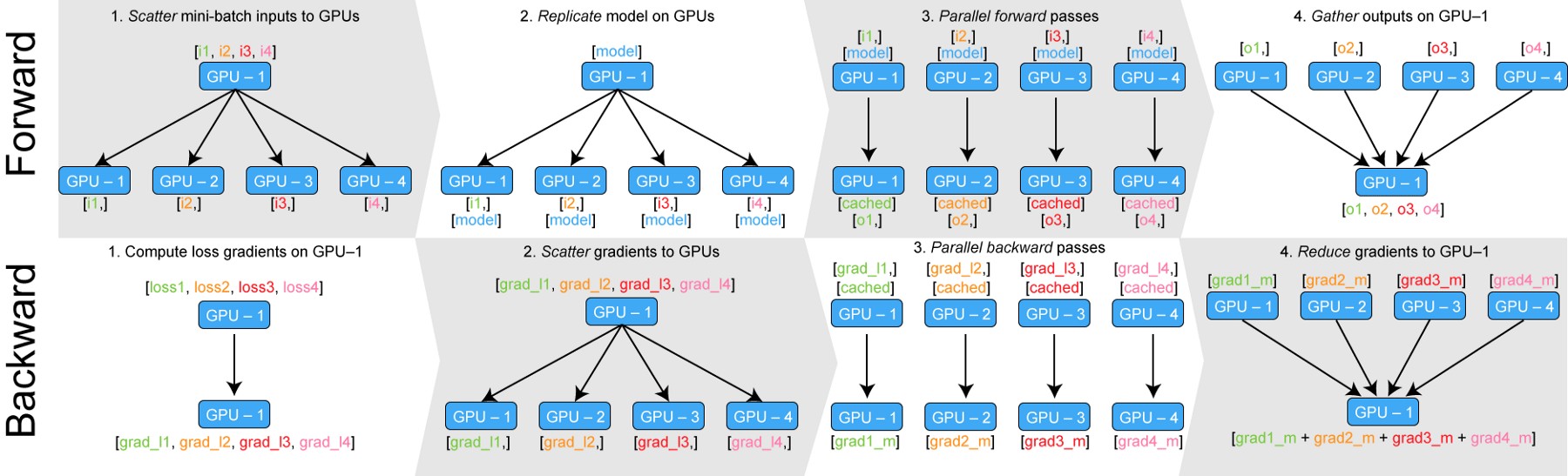
Working of nn.DataParallel. Source
DataParallel takes the input, splits it into smaller batches, replicates the neural network across all the devices, executes the pass and then collects the output back on the original GPU.
One issue with DataParallel can be that it can put asymmetrical load on one GPU (the main node). There are generally two ways to circumvent these problem.
- First, is to compute the loss during the forward pass. This makes sure at least the loss calculation phase is parallelised.
- Another way is to implement a parallel loss function layer. This is beyond the scope of this article. However, for those interested I have given a link to a medium article detailing implementation of such a layer at the end of this article.
Model Parallelism
Model parallelism means breaking your network into smaller subnetworks that you put on different GPUs. The main motivation is that your network might be too large to fit inside a single GPU.
Note that model parallelism is often slower than data parallelism. Splitting a single network into multiple GPUs introduces dependencies between GPUs, which prevents them from running in a truly parallel way. The advantage one derives from model parallelism is not about speed but about the ability to run networks whose size is too large to fit on a single GPU.
As Figure B shows, Subnet 2 waits for Subnet 1 during the forward pass, while Subnet 1 waits for Subnet 2 during the backward pass.
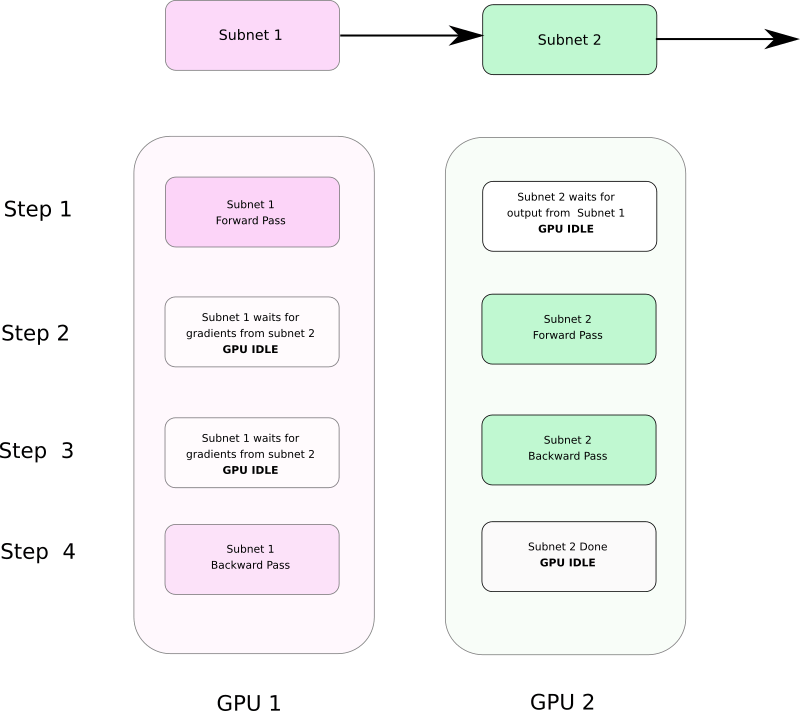
Model Parallelism with Dependencies Implementing Model parallelism in PyTorch is pretty easy as long as you remember two things.
- The input and the network should always be on the same device.
toandcudafunctions have autograd support, so your gradients can be copied from one GPU to another during backward pass. We will use the following piece of code to understand this better.
class model_parallel(nn.Module):
def __init__(self):
super().__init__()
self.sub_network1 = ...
self.sub_network2 = ...
self.sub_network1.cuda(0)
self.sub_network2.cuda(1)
def forward(x):
x = x.cuda(0)
x = self.sub_network1(x)
x = x.cuda(1)
x = self.sub_network2(x)
return x
In the init function we have put the sub-networks on GPUs 0 and 1 respectively.
Notice in the forward function, we transfer the intermediate output from sub_network1 to GPU 1 before feeding it to sub_network2. Since cuda has autograd support, the loss backpropagated from sub_network2 will be copied to buffers of sub_network1 for further backpropagation.
Troubleshooting Out of Memory Errors
This section will discuss how to diagnose memory issues and explore potential solutions if your network is utilizing more memory than necessary.
While going out of memory may necessitate reducing batch size, one can do certain checks to ensure that memory usage is optimal.
Tracking Memory Usage with GPUtil
One way to track GPU usage is by monitoring memory usage in a console with the nvidia-smi command. The problem with this approach is that peak GPU usage and out-of-memory happen so fast that you can’t quite pinpoint which part of your code is causing the memory overflow.
For this, we will use an extension called GPUtil, which you can install with pip by running the following command.
pip install GPUtil
The usage is pretty simple.
import GPUtil
GPUtil.showUtilization()
Just put the second line wherever you want to see the GPU Utilization. By placing this statement in different places in the code, you can figure out what part is causing the network to go OOM.
Dealing with Memory Losses using del keyword
PyTorch has a pretty aggressive garbage collector. The garbage collection will free it as soon as a variable goes out of scope.
It’s important to note that Python does not enforce scoping rules as strictly as languages like C or C++. A variable remains in memory as long as references (or pointers) exist. This behavior is influenced by the fact that variables in Python do not need to be explicitly declared.
As a result, memory occupied by tensors holding your input, output tensors can still not be freed even once you are out of the training loop. Consider the following chunk of code.
for x in range(10):
i = x
print(i) # 9 is printed
When executing the code snippet above, you’ll notice that the value of ‘i’ persists even after we exit the loop where it was initialized. Similarly, the tensors that store loss and output can remain in memory beyond the training loop. To properly release the memory occupied by these tensors, we should use the ‘del’ keyword.
del out, loss
In fact, as a general rule of thumb, if you are done with a tensor, you should del as it won’t be garbage collected unless there is no reference to it left.
Using Python Data Types Instead of 1-D Tensors
In our training loop, we frequently aggregate values to calculate metrics, with the most common example being the update of the running loss during each iteration. However, if this is not done carefully in PyTorch, it can result in excessive memory usage beyond what is necessary.
Consider the following snippet of code.
total_loss = 0
for x in range(10):
# assume loss is computed
iter_loss = torch.randn(3,4).mean()
iter_loss.requires_grad = True # losses are supposed to differentiable
total_loss += iter_loss # use total_loss += iter_loss.item) instead
We expect that in subsequent iterations, the reference to iter_loss will be reassigned to the new iter_loss, and the object representing iter_loss from the earlier representation will be freed. However, this doesn’t happen.
Why is that?
Since iter_loss is differentiable, the line total_loss += iter_loss creates a computation graph that includes an AddBackward function node. During subsequent iterations, additional AddBackward nodes are added to this graph, and no objects holding the values of iter_loss are released. Typically, the memory allocated for a computation graph is freed when backward is called on it; however, in this case, there is no opportunity to call backward.
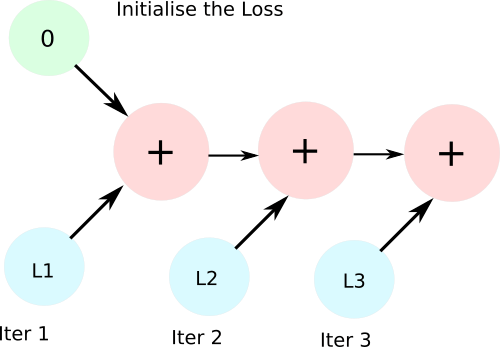
The computation graph is formed when you keep adding the loss tensor to the variable total_loss. To prevent the creation of any computation graph, the solution is to add a Python data type instead of a tensor to total_loss.
We merely replace the line total_loss += iter_loss with total_loss += iter_loss.item(). item returns the Python data type from a tensor containing single values.
Emptying Cuda Cache
While PyTorch efficiently manages memory usage, it may not return memory to the operating system (OS) even after you delete your tensors. Instead, this memory is cached to facilitate the quick allocation of new tensors without requesting additional memory from the OS.
This behavior can pose a problem when using more than two processes in your workflow. If the first process completes its tasks but retains the GPU memory, it can lead to out-of-memory (OOM) errors when the second process is initiated.
To address this issue, you can include a specific command at the end of your code to ensure that memory is released properly.
torch.cuda.empy_cache()
This will make sure that the space held by the process is released.
import torch
from GPUtil import showUtilization as gpu_usage
print("Initial GPU Usage")
gpu_usage()
tensorList = []
for x in range(10):
tensorList.append(torch.randn(10000000,10).cuda()) # reduce the size of tensor if you are getting OOM
print("GPU Usage after allcoating a bunch of Tensors")
gpu_usage()
del tensorList
print("GPU Usage after deleting the Tensors")
gpu_usage()
print("GPU Usage after emptying the cache")
torch.cuda.empty_cache()
gpu_usage()
The following output is produced when this code is executed on a Tesla K80
Initial GPU Usage
| ID | GPU | MEM |
------------------
| 0 | 0% | 5% |
GPU Usage after allcoating a bunch of Tensors
| ID | GPU | MEM |
------------------
| 0 | 3% | 30% |
GPU Usage after deleting the Tensors
| ID | GPU | MEM |
------------------
| 0 | 3% | 30% |
GPU Usage after emptying the cache
| ID | GPU | MEM |
------------------
| 0 | 3% | 5% |
Using torch.no_grad() for Inference
By default, PyTorch creates a computational graph during the forward pass. This process involves allocating buffers to store gradients and intermediate values necessary for computing the gradient during the backward pass.
During the backward pass, most of these buffers are freed, except for those allocated for leaf variables. However, during inference, since there is no backward pass, these buffers remain allocated, which can lead to excessive memory usage over time.
To prevent this memory buildup when executing code that does not require backpropagation, always place it within a torch.no_grad() context manager.
with torch.no_grad()
# your code
Using CuDNN Backend
You can utilize the cuDNN benchmark instead of the standard benchmark. CuDNN offers significant optimizations that can reduce your memory usage, especially when the input size to your neural network is fixed. To enable the cuDNN benchmark, add the following lines at the beginning of your code.
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.enabled = True
Using 16-bit Floats
The new RTX and Volta cards by nVidia support both 16-bit training and inference.
model = model.half() # convert a model to 16-bit
input = input.half() # convert a model to 16-bit
However, the 16-bit training options must be taken with a pinch of salt.
While 16-bit tensors can cut your GPU usage by almost half, they have a few issues.
In PyTorch, batch normalization layers can have convergence issues when using half-precision floats. If you encounter this problem, ensure that the batch normalization layers are set to float32.
model.half() # convert to half precision
for layer in model.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.float()
Also, you need to make sure when the output is passed through different layers in the forward function, the input to the batch norm layer is converted from float16 to float32 and then the output needs to be converted back to float16
One can find a good discussion of 16-bit training in PyTorch here.
Additionally, it is important to ensure that when the output is processed through various layers in the forward function, the input to the batch normalization layer is converted from float16 to float32. After processing, the output should be converted back to float16.
Be cautious of overflow issues when using 16-bit floats. I once encountered an overflow while trying to store the union area of two bounding boxes (for calculating Intersection over Union, or IoU) in a float16. It’s important to ensure that the value you intend to save in a float16 is realistic.
Nvidia has recently released a PyTorch extension called Apex that facilitates numerically safe mixed precision training in PyTorch. I have provided the link to that at the end of the article.
Conclusion
Managing memory efficiently in PyTorch, especially with multiple GPUs, is crucial for getting the best performance out of deep learning models. Understanding memory allocation, caching, and gradient accumulation can prevent out-of-memory errors and make the most of your hardware.
When scaling up to multiple GPUs, using DataParallel or DistributedDataParallel helps distribute workloads effectively. However, each approach has trade-offs, so choosing the right one depends on your use case. Keeping an eye on memory usage with tools like torch.cuda.memory_summary() and clearing unused tensors with torch.cuda.empty_cache() can go a long way in avoiding performance bottlenecks.
Ultimately, optimizing memory in PyTorch isn’t just about freeing up space—it’s about ensuring smooth, efficient training so your models run faster and more reliably. With the right practices, you can push the limits of your hardware while keeping things stable and efficient.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
The usage the DataParallel - as shown in this tutorial - is discouraged by the PyTorch team. The Python GIL is a serious performance bottleneck in this case. DistributedDataParallel shoud be used instead: Getting Started with Distributed Data Parallel — PyTorch Tutorials 2.8.0+cu128 documentation
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
