By Adrien Payong and Shaoni Mukherjee

Introduction
AI is steadily progressing as scientists develop methods for knowledge sharing, information representation, reasoning, and decision-making.
The Retrieval-Augmented Generation has recently attracted attention due to its capacity to ground large language models to external, up-to-date knowledge.
In the meantime, AI agents—intelligent software that can perceive and respond to their environment— are essential for tasks involving sequential decision-making, flexibility, and planning.
As tasks become more complex, relying solely on one approach (RAG or AI agents) may not be enough. This has resulted in Agentic RAG, which merges RAG’s knowledge capabilities with AI agents’ decision-making skills.
This article thoroughly explores RAG, AI agents, and Agentic RAG, emphasizing their theoretical background, foundational principles, and use cases.
Prerequisites
Before exploring the complexities of AI Agents, Multi-Agent Systems, and the concept of Retrieval-Augmented Generation, it’s important to understand the following foundational elements:
- Fundamentals of Artificial Intelligence: Understanding key AI principles like machine learning and natural language processing.
- Retrieval-Augmented Generation: Insight into how RAG combines retrieval methods with generative models.
- Autonomous Systems: A fundamental understanding of the importance of autonomy in modern AI applications.
Definition and Conceptual Overview of RAG
Retrieval-augmented generation merges large language models with retrieval systems, grounding responses in external data instead of relying solely on the training parameters. Traditional LLMs, despite their power, often produce plausible but factually incorrect responses known as hallucinations.
Integrating an external retrieval step allows RAG to fetch and add factual or contextual information.
An application of the RAG system can be described in the diagram below:
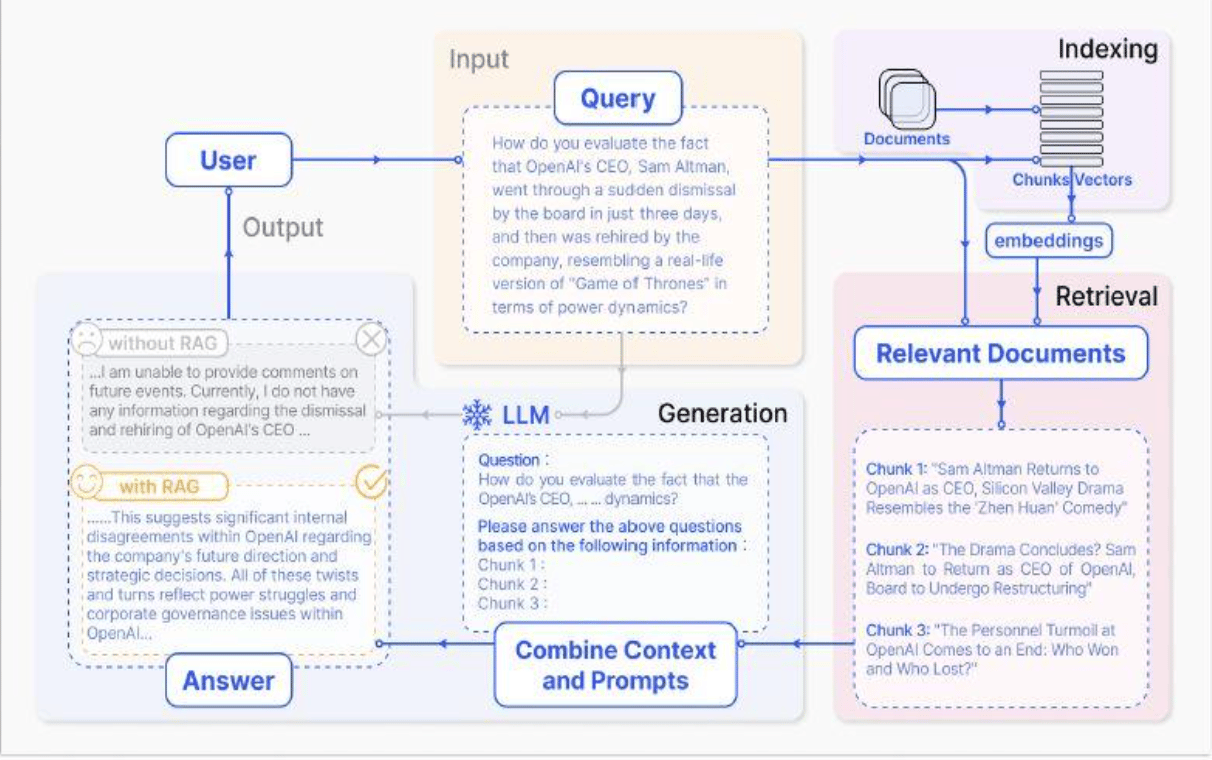
For example, if a user asks a large language model like ChatGPT about a trending news story, the model’s limitations become apparent. It relies on outdated, static information and cannot access real-time updates.
RAG addresses this by drawing the latest relevant data from external sources. So, when a user inquires about a news story, RAG fetches the most recent articles or reports related to that question, which are combined with the original query to form a more informative prompt.
This augmented prompt enables the language model to generate well-knowledgeable and accurate responses by integrating retrieved knowledge into its output. Consequently, RAG improves the model’s ability to deliver precise and timely information, especially in fields requiring real-time updates, like news, scientific advancements, or financial markets.
Key Paradigms of RAG
The RAG research model is undergoing important evolution, which can be categorized into three distinct phases: Naive RAG, Advanced RAG, and Modular RAG, as illustrated in the image below:
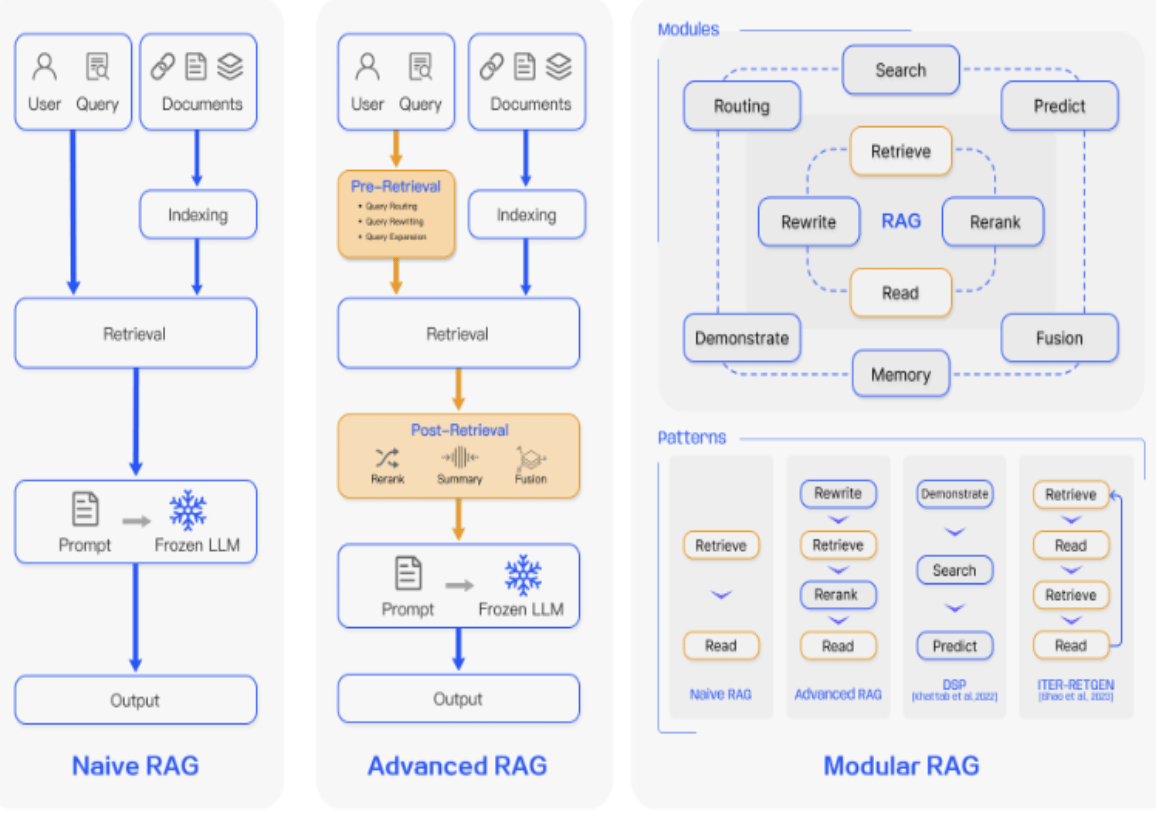
Naive RAG: Initial Methods and Limitations
The Naive Retrieval-Augmented Generation method represented the initial phase of retrieval-augmented techniques. It uses a straightforward pipeline consisting of:
- Indexing: Documents are divided into smaller chunks, converted into vector representations, and stored within a vector database.
- Retrieval: Relevant chunks are retrieved using semantic similarity to the query supplied by the user.
- Generation: The retrieved chunks are combined with the query to generate a response.
However, Naive RAG also comes with some limitations:
Retrieval Challenges
The retrieval process often fails to get both precision and recall. This can result in selecting the wrong or unnecessary chunks and leaving out data necessary to produce accurate responses. These retrieval gaps reduce the quality of the final outcome.
Generation Difficulties
When the model returns responses, it can generate hallucinations – statements not supported factually by the retrieval context. Also, the responses may lack relevance, contain toxic content, or exhibit bias, which could compromise their reliability and utility.
Augmentation Challenges
Effectively aligning retrieved information with task requirements presents considerable challenges:
- Disjointed Outputs: The results can be incoherent if we combine the query and the retrieved information.
- Redundancy: If the same chunks are derived from various sources, the answers can become redundant and lack conciseness.
- Relevance and Significance: Determining the relevance of retrieved text and aligning it with the query context increases complexity.
- Stylistic Consistency: The differing tones or structures of retrieved data require extra effort to merge them smoothly with AI-generated text to achieve coherence and consistency.
Context Limitations
One retrieval pass on the original query doesn’t get sufficient contextual data, especially for complex or multi-faceted queries. That inadequacy may lead to incomplete or splintered responses.
Over-Reliance on Augmented Information
Generation models may depend too much on retrieved content, leading to results that merely reflect that information without genuine synthesis or insights. This makes the results less meaningful and less useful for complex queries.
Advanced RAG
Advanced RAG overcomes the shortcomings of naive RAG by providing specific improvements to the retrieval and indexing process. Such improvements aim to improve retrieval precision, reduce noise, and enhance the general utility of information retrieved. Advanced RAG uses both pre- and post-retrieval techniques to optimize the process.
Pre-Retrieval Process
Pre-retrieval work towards the indexing structure improvement and refinement of the original user query for retrieval quality.
The purpose is twofold: to improve the quality and relevance of the indexed content and to make the query better suited for efficient retrieval.
This includes strategies like improving data granularity, optimizing index structures, adding metadata, optimizing alignment, and mixed retrieval. Query optimization aims to clarify the user’s original question for the retrieval task. Common techniques involve query rewriting, transformation, and expansion.
Post-Retrieval Process
After retrieving relevant context, it’s essential to integrate it with the user query to improve generation. Methods in the post-retrieval process include reranking chunks and context compression.
Re-Ranking Chunks
Retrieved chunks are rearranged based on relevance, prioritizing the most important content at the start of the prompt. Frameworks such as LlamaIndex, LangChain, and HayStack have adopted this approach to optimize retrieval results.
Context Compression
Directly inputting all retrieved documents into LLMs can overwhelm the system, causing information dilution and reducing attention to key details. To mitigate this, the following strategies can be used:
- Selecting essential Information: Post-retrieval efforts are focused on identifying the most critical sections while eliminating irrelevant or repetitive content.
- Shortening context: Compressing the retrieved chunks ensures a concise input to the model that remains focused on the query.
Modular RAG
The Modular RAG architecture transcends the Naive and Advanced RAG models, offering improved adaptability and versatility. It uses multiple strategies to enhance its capabilities, including a dedicated search module for similarity searches and careful fine-tuning of the retriever. Groundbreaking innovations tackle distinct challenges head-on, including restructured RAG modules and optimized RAG pipelines. This modular design enables sequential processing and comprehensive end-to-end training across components, building upon the core principles of Advanced and Naive RAG to enhance the RAG framework.
The Modular RAG framework offers specialized components to improve retrieval and processing capabilities, as shown in the table below.
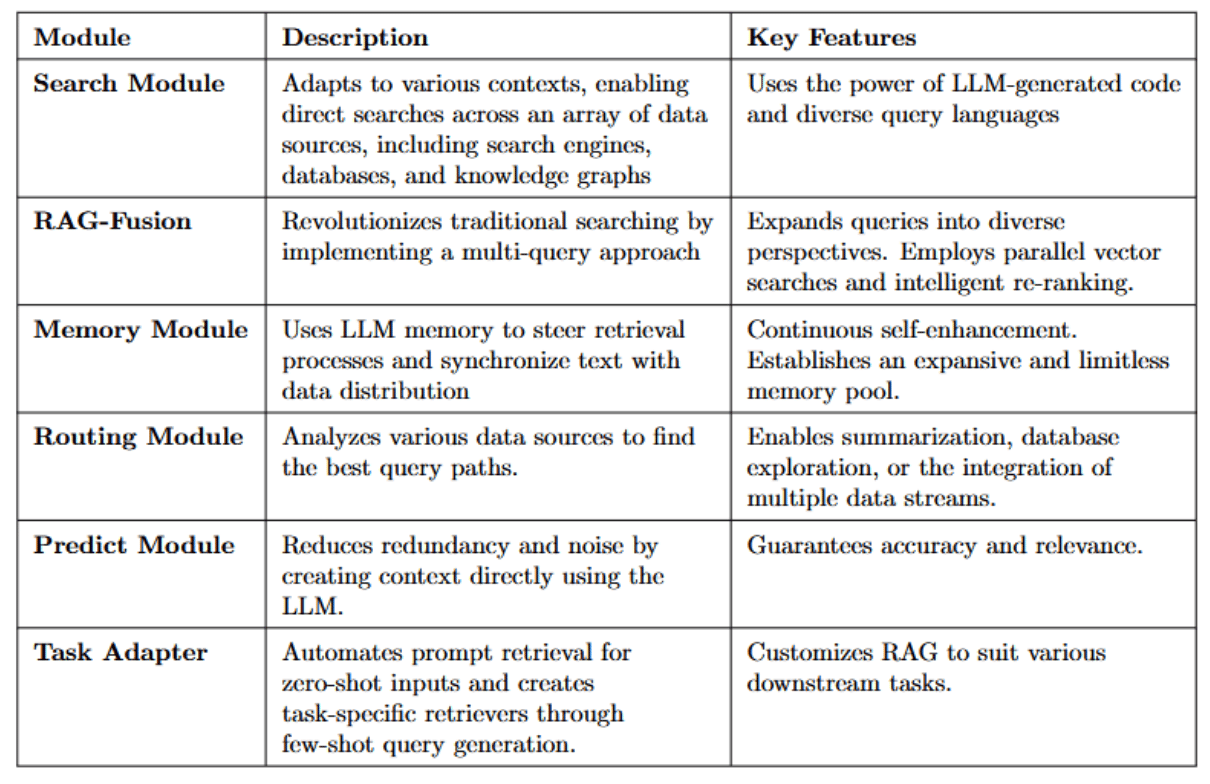
This modular approach greatly enhances retrieval precision and adaptability for various tasks and queries.
Modular RAG represents an advanced step forward in the RAG family. It goes beyond static retrieval systems by incorporating specialized modules and allowing flexible setups. It enhances performance and enables easy integration with emerging technologies, demonstrating its potential for various applications.
AI Agents: Autonomy and Adaptability
The term AI Agent usually brings to mind autonomous robots or digital assistants that interact with their surroundings in ways similar to humans. However, we can define an AI agent as any computational entity that perceives and responds to its environment using intelligent processes. Important components include:
- Perception: The processes involved in gathering and interpreting incoming data, whether from sensors, API, or user interactions.
- Reasoning/Decision-Making: An internal mechanism that generates plans or decisions based on the perceived data. This process may rely on rules, heuristics, or machine learning algorithms.
- Action: The resulting output from the agent, which can manifest as textual responses, directives to external systems, or physical interactions within an environment.
Some Common Types of AI Agents
From simple reflex agents to advanced utility-based agents, each type possesses distinct abilities suited to different levels of complexity and task requirements.
Simple Reflex Agents
Simple reflex agents are the most fundamental type of AI agents. They react only to the current input from their environment, lacking any memory of previous interactions or consideration for the broader context. These agents use predefined rules called condition-action rules to determine their actions.
How Simple Reflex Agents Work
A simple reflex agent works by:
- Perceiving the Environment: It gathers input (or percept) that illustrates the current state of its environment.
- Matching a Condition: The agent compares the percept against a predetermined set of rules or conditions.
- Executing an Action: The agent performs the respective action once the condition is met.
The agent’s logic can be encapsulated as:
“If condition, then action.”
For example, a thermostat is a basic reflex agent using simple condition-action rules.
- Percept: The current temperature of the room.
- Condition-Action Rules:
- If the temperature falls below 68**°F**, activate the heater.
- If the temperature exceeds 77**°F**, deactivate the heater.
The thermostat operates without considering variables such as time of day or expected temperature fluctuations; it responds exclusively to the current temperature reading.
Let’s consider the following diagram:
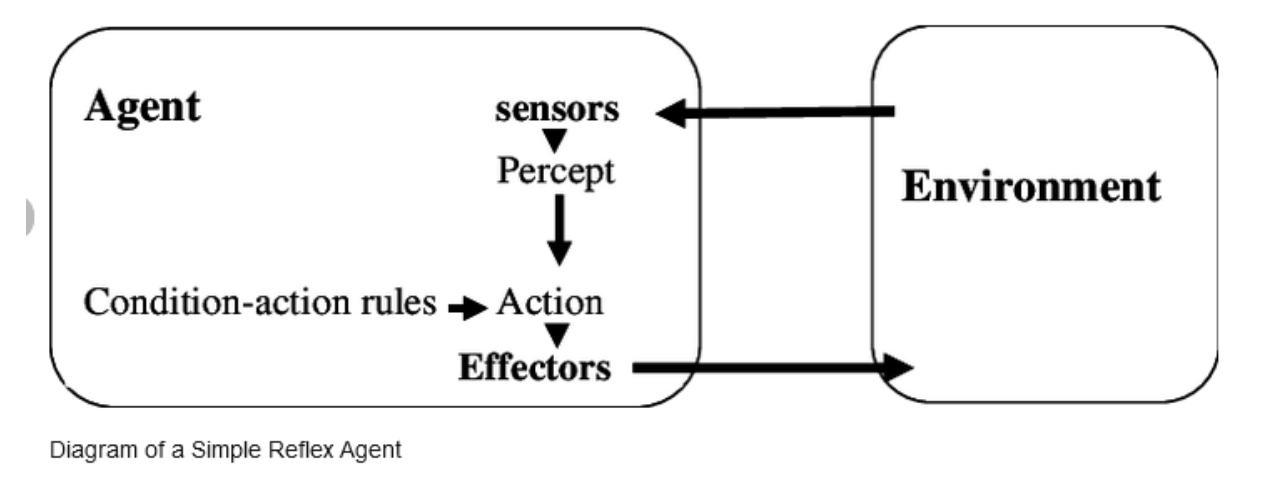
The illustration above represents a Simple Reflex Agent, which engages with its environment via sensors to gather inputs and uses effectors to execute actions based on established condition-action rules. The environment provides feedback, creating an ongoing interaction loop.
Limitations of Simple Reflex Agents
Simple reflex agents, while advantageous, have some limitations. They lack memory and cannot adjust to changing situations or learn from past experiences. Their decisions are based only on the present input without considering previous contexts or future possibilities.
This inflexibility can cause issues in situations that require a better understanding of the environment or more complex decision-making. For example, a thermostat can accurately control temperature but fails to factor in variables(external factors) like the time of day or forecasted weather changes. This lack of adaptability and rule creation restricts simple reflex agents to specific tasks in stable environments.
Model-Based Reflex Agents: Bridging the Gap Between Simplicity and Context
Model-based reflex agents improve upon simple reflex agents by using an internal model of their environment. By keeping a representation of the world, these agents can deduce the current state of their environment and predict the outcomes of their actions.
How Model-Based Reflex Agents Work
A model-based reflex agent’s primary characteristic is its internal model, which functions as a memory of the environment’s state and aids the agent in understanding current percepts in a wider context. When the agent receives a percept, it updates its internal model to reflect environmental changes. The agent then refers to this updated model to assess condition-action rules and decide on the best action. Unlike simple reflex agents that depend only on immediate percepts, model-based agents make decisions using both current observations and inferred states from their model.
For example, a robot vacuum cleaner represents a model-based reflex agent. It uses sensors to identify its position and detect obstacles while keeping an internal room map. This map helps the vacuum recall areas it has already cleaned and navigate obstacles more effectively. This way, the agent prevents unnecessary actions and enhances performance compared to a simple reflex system.
Let’s consider the following image:
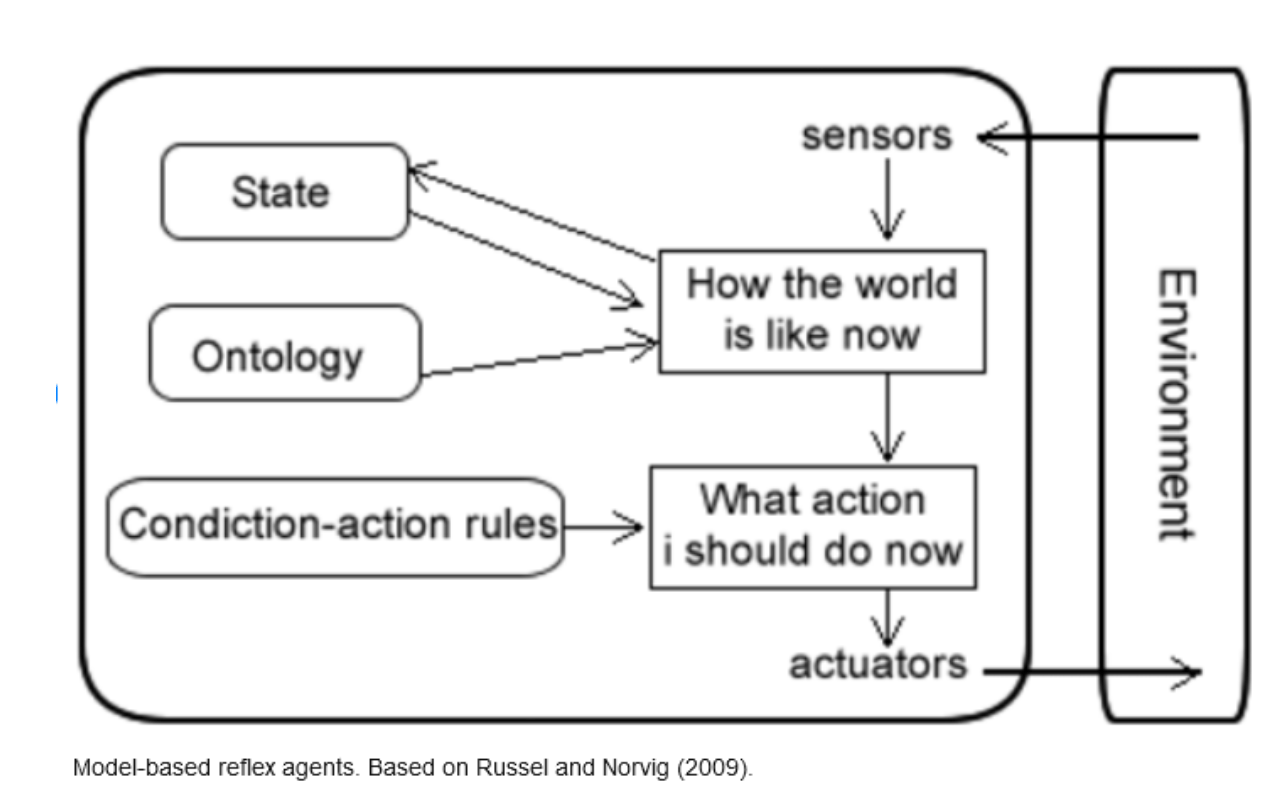
The diagram illustrates a Model-Based Reflex Agent that uses sensors to perceive its environment. It keeps an internal state and ontology to grasp the current situation. The agent uses condition-action rules to determine which action to take and carries out these actions via actuators, thereby interacting with the environment in a feedback loop.
Limitations of Model-Based Reflex Agents
Although having an internal model improves these agents’ abilities, they still face some limitations. First, the effectiveness of the agent’s decisions relies heavily on the quality and thoroughness of its internal model. If the model is outdated or incorrect, the agent could make poor or wrong decisions. They lack long-term goals and planning skills and depend on predefined condition-action rules, restricting their adaptability in complex or unpredictable situations.
Although they have some drawbacks, model-based reflex agents find a middle ground between simplicity and adaptability. They are especially effective for tasks where environmental changes are present but can be reasonably inferred by maintaining an internal state. This quality makes them an important stepping stone towards more advanced AI systems, such as goal-based or learning agents.
Goal-Based Agents: Decision-Making with Purpose
Goal-oriented agents enhance reflex-based agents by integrating goals into their decision-making framework. Unlike basic or model-based reflex agents, which respond exclusively to current perceptions or conditions, goal-oriented agents assess potential actions based on how effectively they fulfill targeted outcomes. Their planning and reasoning capabilities provide them with the adaptability needed to thrive in complex and changing environments.
How Goal-Based Agents Work
A goal-based agent operates by performing the following actions:
- Perceiving the Environment: The agent observes the current conditions of the environment via its perceptual inputs.
- Updating State: It maintains a representation of the current state of the world.
- Evaluating Goals: The agent reviews its objectives to ascertain the intended outcomes.
- Planning: Using search or decision-making algorithms, the agent assesses potential actions and predicts their implications to identify the optimal course of action.
- Executing Actions: Once a plan is established, the agent implements the action to advance toward its objectives.
For example, a GPS navigation system acts as a goal-oriented agent. Users set a destination, and the agent assesses the best route based on distance, traffic, and road conditions. After selecting a path, the system provides step-by-step guidance to reach the destination.
We will consider the following diagram:

The diagram above shows a Goal-Based Agent that perceives its environment evaluates its state, tracks changes in the world, and assesses the effects of actions to predict future outcomes. It relies on specific goals to decide which action to take and implement these decisions using effectors to meet its targets.
Types of Goal-Based Agents
Goal-based agents fall into four main categories based on their decision-making styles:
- Reactive Agents: These agents prioritize immediate objectives and react quickly to environmental changes. They use set rules or heuristics instead of detailed planning.
- Deliberative Agents: Also called planning agents, deliberative agents focus on long-term goals by assessing potential actions and their effects. They use an environmental model to estimate the outcomes of their actions, selecting the most suitable option for their objectives.
- Hybrid Agents: Hybrid agents merge the benefits of reactive and deliberative agents. They respond immediately in urgent situations and deliberate when time and resources allow for planning. These agents often feature a layered architecture supporting reactive and deliberative processes.
- Learning Agents: Learning agents improve decision-making by drawing insights from previous experiences. They adapt their actions by refining their strategies or goals based on feedback from their surroundings.
Strengths of Goal-Based Agents
Goal-based agents are effective in complex environments. Their adaptability lets them respond to changing conditions by focusing on goals rather than strict rules. With planning abilities, they assess future outcomes and choose actions that align with long-term objectives, ensuring progress toward their goals. Their ability to adjust plans in response to environmental changes allows optimal decision-making even in uncertain situations.
Limitations of Goal-Based Agents
While adaptable and capable of planning, goal-based agents face limitations. Their computational complexity can be high due to the substantial resources required for generating and evaluating plans in environments with many possible actions or unpredictable changes.
Specifying goals can be challenging, particularly with vague or conflicting objectives.
Finally, these agents rely heavily on accurate environmental models and reliable prediction algorithms; inaccuracies can lead to suboptimal decisions, limiting effectiveness.
Utility-Based Agents: Optimizing Decision-Making with Preferences
Utility-based agents enhance goal-based agents by introducing utility, which measures the desirability of different outcomes. Rather than simply reaching a target, these agents assess the desirability of each potential result, prioritizing actions that enhance overall utility. This skill in evaluating trade-offs and balancing competing objectives makes utility-based agents effective in complex and uncertain environments.
How Utility-Based Agents Work
Utility-driven agents thrive on a unique system where they assign numerical values (utilities) to various states or outcomes. They use utility functions to measure how effectively a particular action fulfills their preferences or objectives. Here’s the process they follow:
- Perceiving the Environment: The agent observes the current environment state via its percepts.
- Updating State: It updates its internal map of the environment to reflect the latest changes.
- Evaluating Utility: The agent uses its utility function to evaluate the desired outcomes for each action.
- Selecting an Action: It chooses the action that promises the highest utility, considering both short-term and long-term consequences.
- Executing the Action: The chosen action is implemented, and the cycle continues as the environment evolves.
An autonomous vehicle is a practical example of a utility-based agent. It assesses various factors such as travel time, fuel efficiency, passenger comfort, and safety. It also uses a utility function to balance conflicting goals for the optimal route and driving style.
Let’s consider the following diagram:
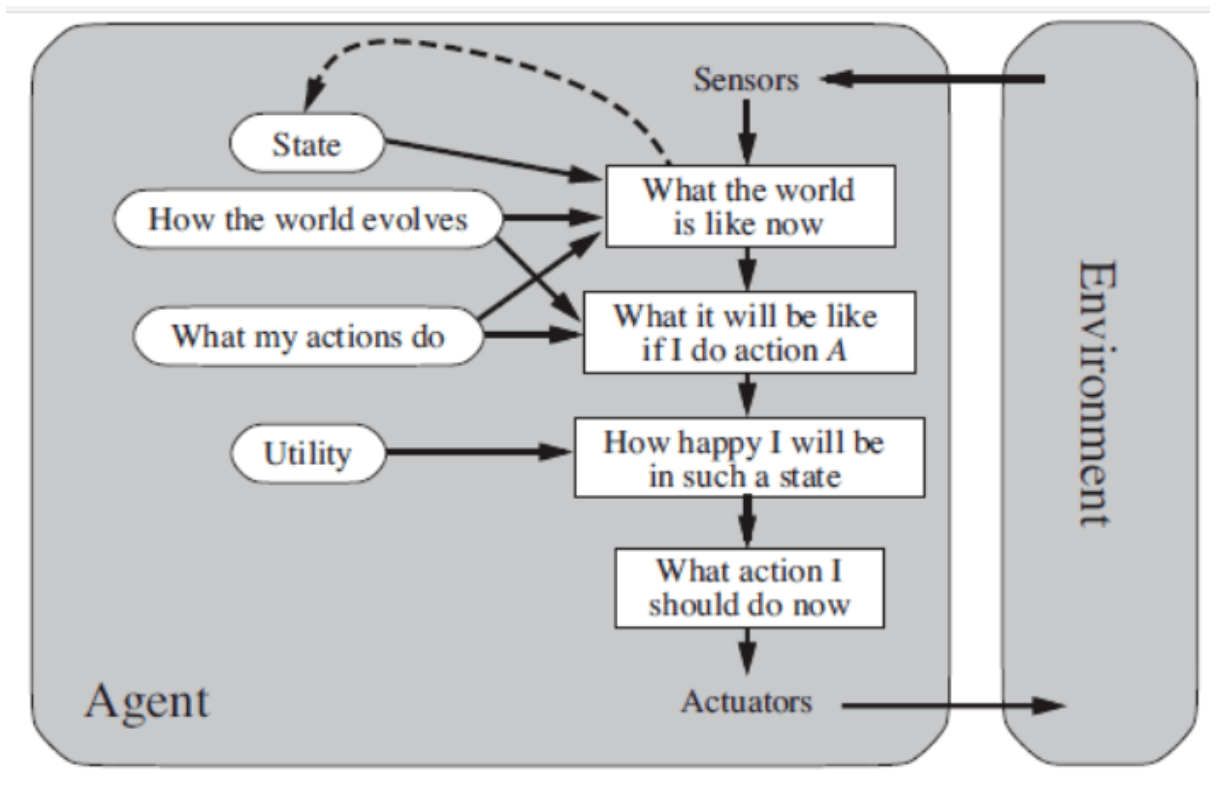
The diagram above shows a Utility-Based Agent that uses sensors to perceive its environment. It assesses the state, potential actions, and their results with a utility function to determine how satisfied it would be in each scenario. The agent then selects the best action and carries it out using actuators, forming a feedback loop with the environment.
Strengths of Utility-Based Agents
Utility-based agents have several strengths that make them effective in complex situations. Their optimized decision-making abilities allow them to choose the best action using utility functions to weigh trade-offs between competing goals. They are adaptable, as changes to the utility function allow them to adjust to new priorities easily. These agents are effective in unpredictable environments, evaluating actions based on expected outcomes to maintain reliable performance under challenging conditions.
Limitations of Utility-Based Agents
Utility-based agents offer benefits but have notable drawbacks. A key challenge is the complexity of designing utility functions, which must accurately capture preferences or goals, especially in situations with multiple objectives. They also require high computational resources because evaluating utility across many potential actions in large state spaces is resource-intensive. These agents also face issues due to uncertainty in predictions. Their performance is highly dependent on the reliability of their predictions about the environment and the outcomes of their actions.
Understanding the AI Agents Stack
The evolution of artificial intelligence has resulted in the development of advanced AI agents that can make decisions autonomously and perform tasks autonomously. These agents depend on a complex framework called the ‘AI agents stack,’ which includes various layers and components essential for their operations. The AI agents stack represents a multi-tiered architecture that supports the functioning of AI agents. As of late 2024, it has been structured into three primary layers:
Model Serving This foundational layer revolves around deploying large language models via inference engines, generally accessible through APIs. Prominent providers include OpenAI and Anthropic, which offer proprietary models, while platforms such as Together.AI and Fireworks provide open-weight models, including Llama 3. For local model inference, tools like vLLM are noteworthy for GPU-based serving, while Ollama and LM Studio are favored by enthusiasts for running models on personal devices.
Storage AI agents must manage the state of conversation histories, memories, and external data. Vector databases like Chroma, Weaviate, Pinecone, Quadrant, and Milvus are frequently used for this “external memory,” which allows agents to process data beyond their immediate context. Traditional databases, such as Postgres with vector search features from pgvector, also contribute to embedding-based search and storage.
Agent Frameworks
These frameworks coordinate large language model calls and manage the agent’s state, encompassing conversation history and execution stages. They enable the integration of various tools and libraries, allowing agents to execute functions that extend beyond standard AI chatbots. The frameworks vary in their methodologies regarding state management, tool execution, and support for numerous models, which affects their applicability for diverse purposes.
Understanding Multi-Agent Systems
Multi-agent systems are an exciting research and application area in the rapidly changing field of artificial intelligence. A multi-agent system consists of several autonomous agents that work together, compete, or operate independently in a shared environment to tackle complex challenges. These agents, which can be software programs or physical robots, are built to perceive their environment, communicate with each other, and make decisions to fulfill their individual or collective objectives.
Some Multi-Agent Frameworks and Platforms
There are several frameworks and tools available for developing and implementing MAS, listed below are some prominent examples:
- JADE (Java Agent Development Framework): JADE is a widely recognized open-source framework for developing multi-agent systems in Java. It conforms to the standards set forth by the FIPA (Foundation for Intelligent Physical Agents).
- PADE (Python Agent DEvelopment framework): PADE is a framework designed for the development, execution, and management of environments where multiple agents operate in distributed computation.
- NetLogo: NetLogo is a multi-agent programming environment designed for modeling and simulating complex systems.
- Swarm: An experimental framework developed by OpenAI to facilitate the orchestration of interactions among multiple agents, allowing for complex coordination between them.
- LangGraph: A flexible framework for building advanced multi-agent systems, emphasizing development simplicity and scalability.
- LangChain: A prominent framework for developing applications based on large language models, including multi-agent architectures, supported by a strong community.
The emerging developing frameworks for multi-agent platforms also include:
- RLlib: It provides advanced support for reinforcement learning.
- PettingZoo: A library in Python specifically designed for research in multi-agent reinforcement learning.
- OpenAI Gym: It is recognized for its flexible environments that are suitable for multi-agent scenarios.
When choosing a framework, it is essential to consider the programming language’s compatibility and scalability requirements. It’s also important to consider the specific research or development objectives to ensure that the platform meets the needs of your project.
Challenges in Multi-Agent Systems
Multi-agent systems have significant benefits. However, their development is accompanied by various challenges. Let’s consider some of them:
- One of the primary concerns is communication overhead, as managing effective and secure exchanges between agents becomes increasingly complex in larger systems.
- Coordination complexity presents additional challenges, requiring advanced strategies to enhance collaboration and resolve conflicts in competitive and cooperative settings.
- Another major obstacle is scalability, where introducing new agents dramatically escalates the complexity and resource requirements of the system.
- Finally, the design of agent behavior requires careful planning and expertise for resilience and adaptability to change.
These challenges emphasize the importance of strategic planning and sophisticated tools during the development of MAS.
Using DigitalOcean’s GenAI Platform for AI Agent Development
DigitalOcean’s GenAI Platform represents an innovative solution for developing and deploying AI agents. This fully managed service alleviates the challenges associated with AI development by offering access to sophisticated models, customization resources, and integrated workflows.
With the GenAI Platform, developers can access top-tier generative AI models. These models allow developers to use the latest advancements in generative AI without complex infrastructure management. This direct access reduces the entry barriers, enabling teams of any size to exploit the capabilities of large language models for various applications.
The GenAI Platform simplifies AI development with integrated workflows that enhance functionality and reduce complexity. Some components include:
- Retrieval-Augmented Generation: Enhance response accuracy and relevance by merging generative AI with customized data.
- Function Calling: Enable agents to execute specific functions for external tasks, broadening their abilities.
- Agent Routing: Support multitasking by enabling agents to manage various goals within the same system.
GenAI Platform is more than a mere development tool. It functions as an all-encompassing ecosystem that provides developers with the essential resources to build intelligent and adaptable AI agents.
Agentic RAG: The Synthesis of Retrieval-Augmented Generation and Autonomy
Agentic RAG is a practical approach to improve adaptability and decision-making in complex, iterative tasks.
Motivation and Emergence
Agentic RAG innovates the retrieval augmentation concept by broadening it from static, single-turn interactions to the multi-step context of autonomous agents. While RAG focuses on factual grounding, AI Agents provide planning capabilities and adaptability within complex environments. By integrating these two models, agentic RAG seeks to develop autonomous systems that efficiently navigate iterative decision-making tasks without experiencing hallucinations.
The motivation behind agentic RAG development stems from use cases that require context-aware generation and real-time actions. Examples encompass advanced robotics, legal advisory services, healthcare diagnostics, and ongoing customer service engagements.
In these contexts, merely retrieving relevant information is insufficient. The agent must analyze the information, assess its importance, determine a response, and potentially execute an action in a continuous feedback loop.
Technical Deep Dive and Design Considerations
A thorough technical exploration of Retrieval-Augmented Generation and Agentic RAG systems emphasizes the essential role of effective retriever modules, generator models, and adaptive agent controllers.
Retriever Choice and Optimization
The retriever module is central to both RAG and Agentic RAG techniques. Two primary methods are traditional sparse vector retrieval (TF-IDF or BM25) and neural dense vector retrieval (incorporating techniques like DPR, ColBERT, or Sentence-BERT). Sparse retrieval methods are well-recognized, straightforward to manage, and perform reliably with short queries. In contrast, neural retrieval often excels in handling more complex queries and synonyms; however, it requires GPU resources for training and inference.
To enhance the performance of large-scale systems, Approximate Nearest Neighbor (ANN) search frameworks such as FAISS (Facebook AI Similarity Search), ScaNN(Scalable Nearest Neighbors), and HNSW(Hierarchical Navigable Small Worlds) are commonly used. These libraries efficiently index dense vectors within high-dimensional spaces, improving query speeds through quantization, clustering, or graph-based strategies. Although ANN approaches generally involve a trade-off between search speed and recall accuracy, their substantial reduction in latency is essential for real-time or near-real-time retrieval in Agentic RAG systems.
The selection of an ANN framework is typically contingent upon specific use case requirements, with factors including data scale, dimensionality, and hardware resources (CPU versus GPU). Ongoing research in this domain, which encompasses innovations in hardware acceleration and novel indexing structures, persistently pushes the frontiers of efficient large-scale vector search.
Generator Model Selection
The generator may be a pre-trained transformer, such as GPT-3.5, GPT-4, T5, or a specialized model that has been fine-tuned for the relevant domain. The selection process is contingent upon:
- Size and Latency Requirements: Larger models provide more fluent and contextually rich outputs, albeit at potentially increased costs or slower execution times.
- Domain Specialization: Fine-tuning a model to specific domain-related datasets (legal, medical, academic) can improve relevance and mitigate the likelihood of erroneous output.
- Control Mechanisms: Some techniques, such as “prompt engineering” or adapter modules, can guide the generative process more precisely. These features are particularly advantageous in complex, safety-critical environments.
Agent Controller and Loop Structure
In Agentic Retrieval-Augmented Generation systems, the agent controller manages a complex multi-step loop that integrates retrieval and generation processes. This iterative cycle generally proceeds in the following manner:
- Trigger Activation: The system begins operation upon receiving a user query or recognizing a predefined event.
- Contextual Retrieval: The controller queries the knowledge base to obtain relevant context.
- Initial Generation: The generative model formulates a preliminary response or hypothesis using the retrieved context.
- Response Evaluation: The agent evaluates the generated content against established constraints, such as business rules or ethical guidelines, while also comparing it with accumulated knowledge from prior interactions.
- Iterative Refinement: If the initial response is insufficient or uncertain, the controller initiates further retrieval steps to fill information gaps.
- Action Implementation: Following validation or refinement, the agent produces the final response, invokes external APIs, or executes the subsequent planned action.
- Continuous Learning: The system integrates new data from various sources, including user interactions, environmental feedback, and system logs, into its knowledge base. This enables continuous improvements of future responses.
This adaptive loop enables Agentic RAG systems to engage in complex reasoning tasks, self-correct, and improve performance.
Handling Ambiguity and Uncertainty
Agentic Retrieval-Augmented Generation systems can encounter ambiguity and uncertainty when handling incomplete, contradictory, or unclear data. To address these challenges, various strategies may be implemented:
- Uncertainty quantification helps the system track the retriever’s and the generator’s confidence scores. This allows it to escalate the issue to a human operator or seek further clarification when the confidence levels are low.
- The system can also produce multiple hypotheses rather than a singular answer, automatically comparing these options or incorporating user feedback to refine its responses.
- Reinforcement learning allows the agent to gain insights from repeated interactions, identifying retrieval queries or generative methods that achieve higher success rates over time.
Some Use Cases of Agentic RAG
Let’s consider some use cases:
Advanced Healthcare Diagnostics: An Agentic RAG system could continuously analyze emerging medical research in real-time. When a physician inputs patient symptoms, the system pulls the most recent studies, suggests potential diagnoses and treatment strategies, and may ask specific questions to clarify any uncertainties. It refines its recommendations through repeated interactions while staying aligned with the latest research findings.
Legal Reasoning: An Agentic RAG agent can extract pertinent case law, regulations, and established precedents within a law firm environment, subsequently creating memos and legal arguments. It can ask clarifying questions to enhance legal reasoning and generate comprehensive briefs rooted in accurate legal references.
Autonomous Customer Support: A purely generative customer service chatbot might provide answers that are either incorrect or superficial. In contrast, with Agentic RAG, the system actively refers to knowledge bases, policy guidelines, and established troubleshooting processes. The agent can acquire additional context from the user and iteratively improve the response, enabling independent handling of returns, refunds, or technical support escalations.
Comparative Summary
Advancements in artificial intelligence have led to the emergence of concepts like Retrieval-Augmented Generation (RAG), AI Agents, and Agentic RAG.
The table compares RAG, AI Agents, and Agentic RAG based on key characteristics.
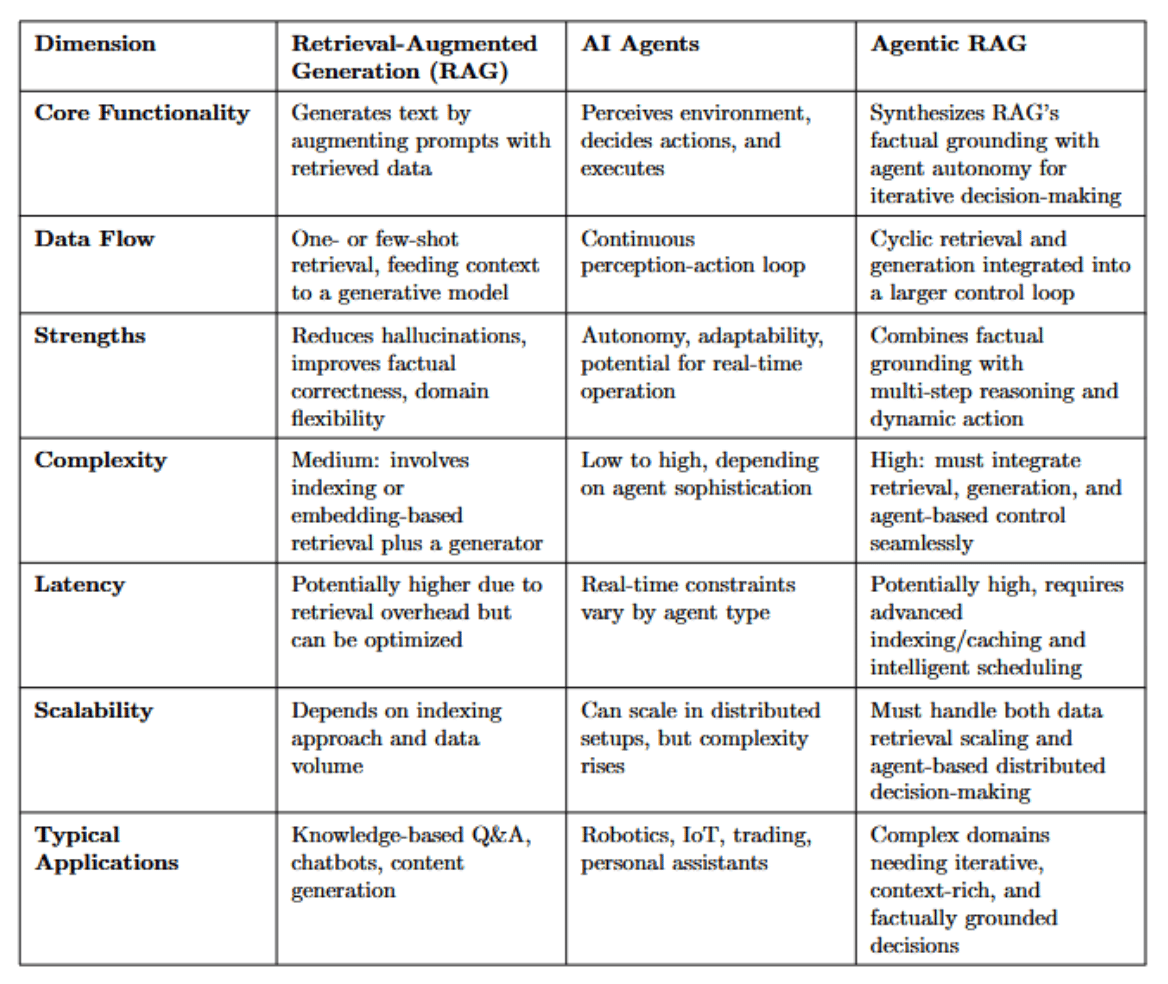
Strengths and Synergies
RAG excels at providing current, fact-based responses, which makes it especially effective for specialized tasks such as medical or legal inquiries, where specific domain knowledge is essential.
In contrast, AI Agents provide adaptability and autonomy due to their continuous learning and decision-making capabilities. By integrating the strengths of agentic RAG, the factual grounding of RAG is merged with the autonomy of AI Agents to create a system that addresses the limitations of each model.
This collaboration guarantees that decisions are based on the most accurate information, minimizing the risks of errors and outdated recommendations.
Challenges
Let’s consider some challenges:
- Integration Overhead: Managing retrieval modules, language generation, and agent decision-making processes can be more complex than using a single technique.
- Computational Demands: Agentic RAG’s iterative nature can increase computational expenses, particularly when managing extensive data sets.
- Data Quality and Bias: Both RAG and Agentic RAG depend on the quality of their data sources. If the data contains biases or is incomplete, the results generated by the system will show these imperfections.
- Security and Ethical Issues: Autonomous agents equipped with advanced retrieval abilities raise ethical and security concerns. This ranges from data privacy to potential misuse and biases in decision-making.
Conclusion
This article examines the fast advancements in artificial intelligence, exploring how scientists develop groundbreaking methods to share insights, present information, and make decisions.
A notable development in this field is Retrieval-Augmented Generation, which has attracted considerable interest for its capability to ground large language models in real-time, external knowledge. It overcomes the restrictions posed by traditional AI systems.
At the same time, AI agents have become critical software tools that can perceive and adapt to their surroundings.
Nevertheless, as the complexities of real-world challenges grow, depending solely on RAG or AI agents frequently proves inadequate. This scenario has given rise to Agentic RAG, a new framework that merges RAG’s factual grounding features with AI agents’ decision-making capabilities. Combining these strengths, Agentic RAG provides a comprehensive solution for multi-step tasks in ever-changing environments.
References
- Retrieval-Augmented Generation for Large Language Models: A Survey
- Single-Agent vs Multi-Agent Systems: Two Paths for the Future of AI
- 5 Types of AI Agents that you Must Know About
- Reliable Agentic RAG with LLM Trustworthiness Estimates
- A Hands-on Guide to Enhance RAG with Re-Ranking
- Query Transform Cookbook
- CONFLARE: CONFormal LArge language model REtrieval
- Top 7 Challenges with Retrieval-Augmented Generation
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
