One of the notable milestones in machine learning is the creation of systems that can address specific needs, like responding naturally to humans or recognizing subtle patterns in data. However, creating these specialized systems typically required training new models completely from scratch—a process that demanded enormous amounts of data and computational resources. For example, an e-commerce company might have a chatbot trained for basic customer support. To launch a second chatbot for product recommendations, they would need to create a new model from the ground up.
Fortunately, organizations soon discovered a better way: instead of starting from zero, they could build upon existing foundations. This breakthrough meant taking pre-trained models—like GPT for language tasks or ResNet for image analysis—that already possessed general-purpose capabilities from training on massive datasets and fine-tuning them for specific tasks. You could now use a language model for summarizing legal documents or fine-tune a vision model for detecting defects in manufacturing. Fine-tuning uses the general knowledge encoded in pre-trained models, so the additional labeled data focuses on the nuances of the specific task or domain. Since you need less data for fine-tuning than training from scratch, the quality and relevance of that data become especially important. In this blog post, we discuss fine-tuning, how it works, the challenges it poses, and best practices.
Key takeaways:
-
Fine-tuning in machine learning is the process of taking a pre-trained model (usually a large one trained on a broad dataset) and training it further on a specific task or dataset so it adapts to the new task effectively.
-
This technique leverages the general knowledge the model has already acquired (for example, a language model’s grasp of English) and refines it, saving time and resources because you don’t need to train a model from scratch.
-
Fine-tuning is commonly used to customize models like language translators, image classifiers, or voice recognition systems to a particular domain or improve performance on niche data, yielding better accuracy than an out-of-the-box generic model while using considerably less data and compute than initial training.
What is fine-tuning?
Fine-tuning is a transfer learning technique where a pre-trained neural network’s parameters are selectively updated using a task-specific dataset, allowing the model to specialize its learned representations for a new or related task. This process adjusts specific layers of the model that capture task-specific features while using the general features encoded in the early layers. Fine-tuning updates the model’s parameters, such as weights, while preserving the overall architecture, allowing the model to balance generalization and task-specific specialization through iterative training on new data.
How does fine-tuning work?
Fine-tuning adapts a pre-trained model to a specific task through a systematic process, as outlined below:
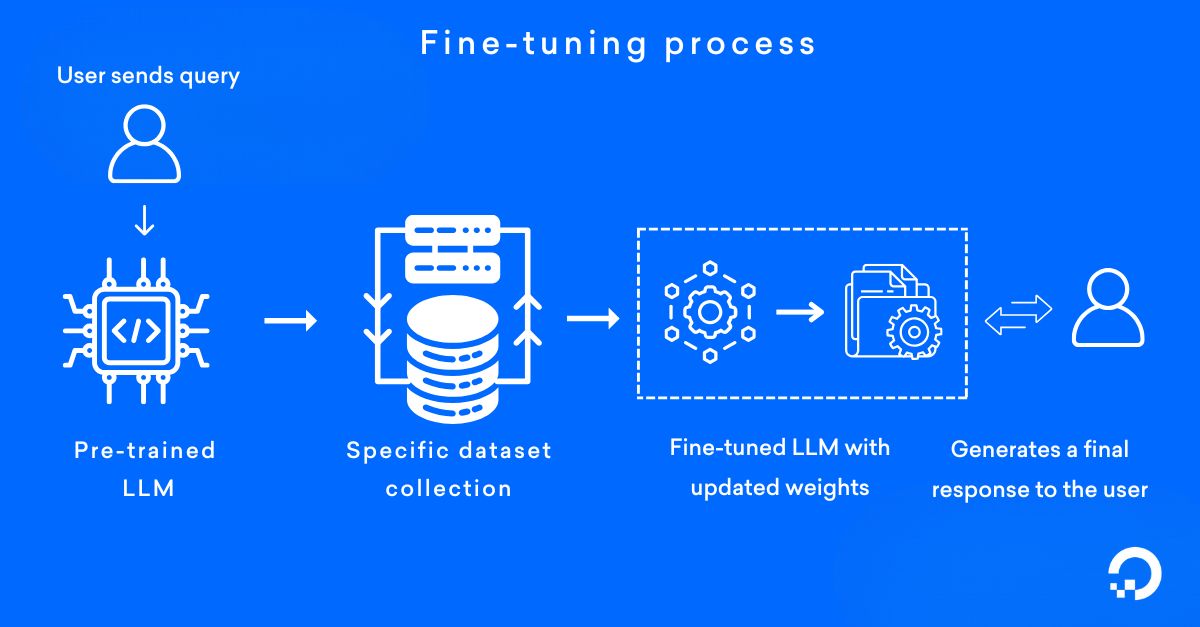
This image provides a simplified representation of a fine-tuning process for general understanding. The specific configurations and data flow may vary based on the particular use case.
1. Start with a pre-trained model
Choose a pre-trained model, such as a large language model (LLM) (from platforms like Hugging Face or Kaggle), that has already been trained on extensive datasets. Use this model as a foundation because it already encodes general features and broad knowledge. For example, start with a model like GPT trained on diverse text corpora.
2. Prepare a task-specific dataset
Collect and organize a dataset specific to the task you want the model to perform. Include labeled examples that reflect your domain. For instance, in a healthcare chatbot, a task-specific dataset could include patient inquiries (e.g., “What are the symptoms of the flu?”) paired with medically accurate responses. Fine-tuning the model on such data ensures precise, context-aware answers that better align with medical guidelines.
3. Fine-tune the model
Use the task-specific dataset to fine-tune the pre-trained model and adjust its weights.
-
Focus on optimizing the later layers of the model to learn task-specific features. For example, train the model to classify sentiment in customer reviews to summarize product descriptions or improve sales strategies.
-
Decide whether to freeze or lightly fine-tune the early layers to preserve general features while adapting to your specific task.
-
Apply techniques like *backpropagation to update the model’s parameters effectively.
*Backpropagation is an algorithm used to train neural networks by calculating and distributing the error from predictions back through the network layers, enabling the model to update its parameters and improve accuracy.
4. Validate the model
Test the fine-tuned model on a validation set to measure its performance and ability to generalize to new data. Use this step to catch any *overfitting and ensure the model performs well on unseen examples. For instance, validate an image classification model by testing it on images not included in the training set.
*Overfitting occurs when a model learns the details and noise of the training data to the extent that it negatively impacts its performance on new, unseen data. As a result, while it may perform well on the training data, it struggles with accuracy and effectiveness on different datasets.
5.Deploy the fine-tuned model
Prepare the fine-tuned model for deployment by exporting it in a format compatible with your production environment, such as ONNX or TensorFlow SavedModel. Optimize the model for inference by using quantization techniques to reduce latency and resource usage without compromising accuracy. Integrate the model into your application via REST APIs, Google Remote Procedure Call (gRPC) endpoints, or direct SDKs. Implement monitoring to track performance metrics like accuracy and latency and establish a feedback loop to gather real-world data.
Unlock the full potential of Mistral-7B, a 7B parameter model that outshines larger models like Llama-2 13B in reasoning, math, and code tasks. Learn how to fine-tune Mistral-7B using cost-effective LoRA techniques in this step-by-step tutorial. With 4-bit quantization and LoRA, fine-tuning becomes accessible even with limited GPU resources. Dive into hands-on strategies for optimizing LLMs, from data preparation to model optimization, and elevate your AI development with state-of-the-art fine-tuning techniques.
Benefits of fine-tuning
Fine-tuning improves the potential of your AI models by efficiently adapting pre-trained models to specific tasks. Rather than training a new model from scratch, this approach lets organizations create specialized AI systems that are tailored to their exact needs…
1. Reduced computational resources
Fine-tuning uses pre-trained models, allowing you to reuse their general knowledge instead of training from scratch. By updating only specific layers or parameters, the process increases the cloud ROI by minimizing the computational cost and time required for training. This makes it an efficient way to adapt large models for specific tasks using a small amount of task-specific data.
2. Improved task-specific performance
Fine-tuning improves the performance of a pre-trained model for a specific use case by tailoring it to a specific task. The process adjusts the model’s weights to focus on domain-specific features, improving accuracy and reliability for the target task. For example, a fine-tuned language model can generate contextually relevant responses in customer service applications.
3. Better utilization of general features
Fine-tuning allows the model to retain general features learned during pre-training while specializing in a new task. Early layers provide foundational knowledge, while later layers are adjusted to focus on specific aspects of the task. This balance enables models to perform well in related tasks without losing generalization capabilities.
💡Looking to supercharge your AI and machine learning projects?
DigitalOcean GPU Droplets offer flexible, cost-effective, scalable solutions to match your workloads. Train and fine-tune AI/ML models, process massive datasets, and tackle complex neural networks for deep learning—all while meeting the demands of high-performance computing (HPC).
Challenges of fine-tuning
While powerful, fine-tuning has several challenges that can impact the model’s performance and usability. These challenges stem from the need for specialized data, maintaining a balance between generalization and task-specific learning, and managing computational demands.
1. Limited task-specific data
Fine-tuning requires a high-quality, labeled dataset specific to the task, but such data may be scarce or difficult to collect. Without sufficient data, the model struggles to learn domain-specific features effectively. This limitation might reduce the model’s performance and lead to overfitting on a small amount of training data.
2. Risk of catastrophic forgetting
During fine-tuning, the model may overwrite the general knowledge it learned during pre-training while adapting to the specific task. This phenomenon, known as catastrophic forgetting, can reduce the model’s effectiveness for related tasks. Balancing task-specific learning without losing the model’s generalization capabilities becomes a challenge.
Explore these tutorials to transform your workflows with YOLOv11 and DigitalOcean GPU Droplets:
-
Part I - Transform your object detection workflows with DigitalOcean GPU Droplets and YOLOv11, the state-of-the-art model that redefines speed and accuracy across tasks like object detection, segmentation, pose estimation, and real-time tracking.
-
Part II- From running YOLOv11 models pre-trained on COCO and ImageNet datasets to fine-tuning for your unique needs, GPU Droplets provide the scalable, cost-effective infrastructure you need.
3. High computational cost for large models
All fine-tuning processes require computational resources, which involve adjusting the model’s parameters to suit a specific task better. However, the scale of computational demand grows significantly with larger models, such as LLMs, and more extensive updates. The larger the model and the more parameters that need to be adjusted, the greater the hardware, like cloud GPUs or TPUs, time, and other resource requirements. This challenge might make fine-tuning less accessible for users with resource constraints.
Fine-tuning best practices
By following fine-tuning best practices, you can ensure optimal results and maximize the model’s potential.
1. Use task-specific data
Prepare a high-quality, labeled dataset by clearly defining the specific task and collecting relevant data from reliable sources that align closely with the particular task you want the model to perform. Include diverse examples by adding task variations and edge cases so that the model grasps a balanced representation across categories of task-relevant features. For instance, if fine-tuning a language model for e-commerce, collect customer queries and product descriptions to train it effectively.
2. Optimize specific layers
Focus on fine-tuning the later layers of the model, as they capture task-specific features while freezing or minimally adjusting the early layers to retain general knowledge. Use techniques like layer freezing in frameworks such as PyTorch or TensorFlow to ensure efficient use of computational resources. Adjust the number of trainable layers based on the complexity of the new task.
Confused about whether to choose fine-tuning or retrieval-augmented generation (RAG) for your next AI project? Dive into our in-depth article, RAG vs. fine-tuning, which explores both approaches, helping you understand their strengths, use cases, and key factors to make the right choice for your business.
3. Monitor validation performance
Continuously evaluate the model’s performance on a validation set during fine-tuning. Track metrics such as accuracy, loss, or F1 score to detect overfitting or underfitting. Stop training if performance on the validation set starts degrading, and adjust parameters or training data if needed.
4. Implement small learning rates
Use a lower learning rate during fine-tuning to avoid overwriting the pre-trained model’s weights. Start with a learning rate ten times smaller (the exact factor varies based on the specific model and task) than the one used during pre-training and adjust it based on the task. Implement learning rate schedulers to reduce the rate during training for better convergence.
Fine-tuning in machine learning FAQs
What is fine-tuning in machine learning?
Fine-tuning is a transfer learning technique where a pre-trained neural network’s parameters are selectively updated using a task-specific dataset, allowing the model to specialize for a new or related task. This process adjusts specific layers that capture task-specific features while preserving the general knowledge encoded in earlier layers from the original training.
How does fine-tuning differ from training a model from scratch?
Fine-tuning uses pre-trained models as a foundation, reusing their general knowledge instead of starting from zero, which significantly reduces computational cost, time, and data requirements. While training from scratch requires enormous datasets and computational resources, fine-tuning focuses only on task-specific nuances using smaller amounts of high-quality, labeled data.
What are the main challenges of fine-tuning?
The primary challenges include catastrophic forgetting (where the model overwrites general knowledge while learning task-specific features), data scarcity (requiring high-quality labeled datasets that may be difficult to collect), and computational demands that scale with model size. Balancing task-specific learning without losing generalization capabilities requires careful management of which layers to update.
What are the best practices for successful fine-tuning?
Key best practices include preparing high-quality, diverse, labeled datasets that align with your specific task, focusing on fine-tuning later layers while freezing early layers to retain general knowledge, using lower learning rates to avoid overwriting pre-trained weights, and continuously monitoring performance on validation sets to prevent overfitting. Layer freezing and learning rate scheduling are essential techniques for optimal results.
Accelerate your AI projects with DigitalOcean Gradient GPU Droplets
Accelerate your AI/ML, deep learning, high-performance computing, and data analytics tasks with DigitalOcean GradientAI GPU Droplets. Scale on demand, manage costs, and deliver actionable insights with ease. Zero to GPU in just 2 clicks with simple, powerful virtual machines designed for developers, startups, and innovators who need high-performance computing without complexity.
Key features:
-
Powered by NVIDIA H100, RTX 6000 Ada, RTX 4000, L40S, and AMD MI300X, MI325X GPUs
-
Save up to 75% vs. hyperscalers for the same on-demand GPUs
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
-
HIPAA-eligible and SOC 2 compliant with enterprise-grade SLAs
Sign up today and unlock the possibilities of DigitalOcean GradientAI GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
